Sabitlenmiş Tweet

🎉 Our paper “Unlocking Dataset Distillation with Diffusion Models” has been accepted at #NeurIPS 25!
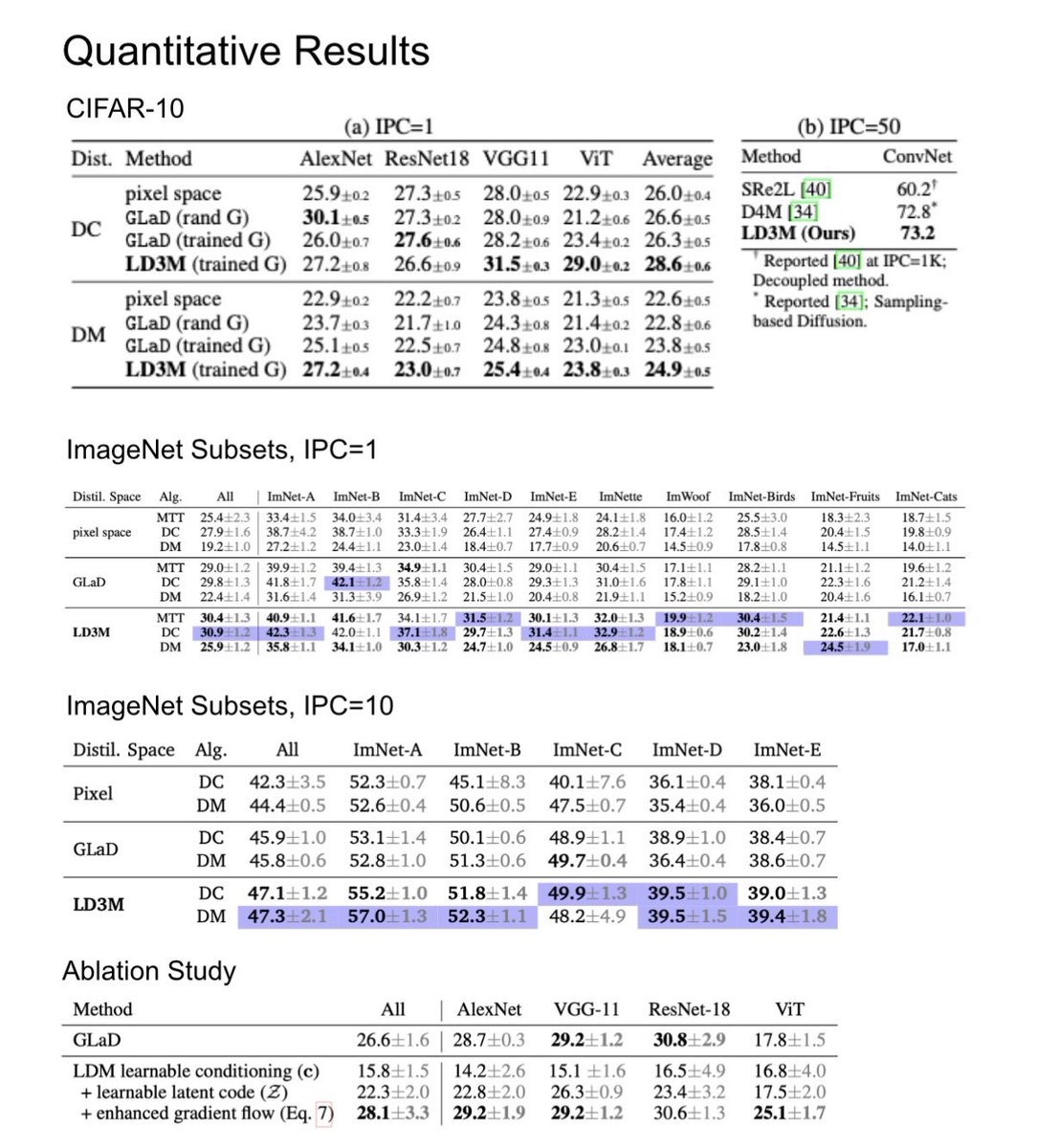
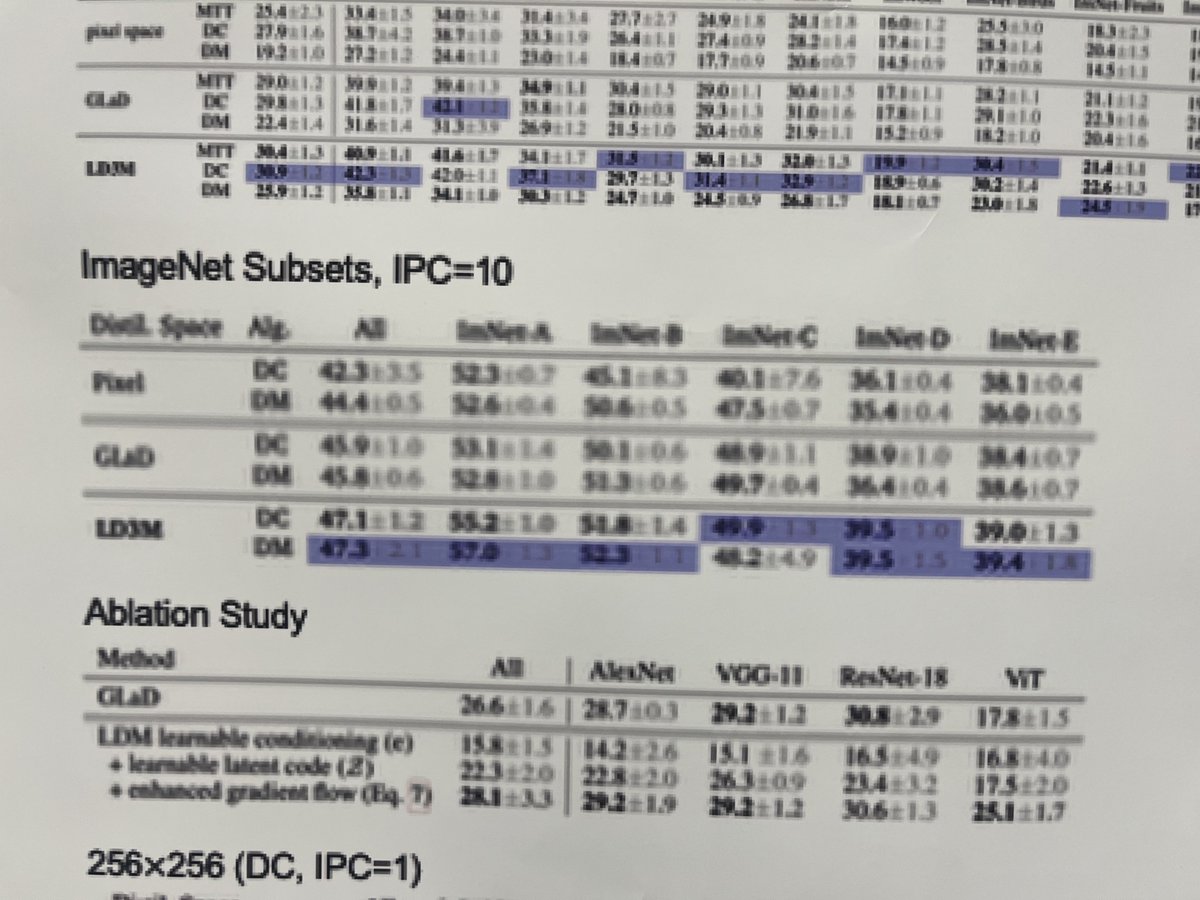
We show how to unlock end-to-end dataset distillation through diffusion models by tackling the vanishing gradient problem!
📄 : arxiv.org/abs/2403.03881
#DiffusionModels
English