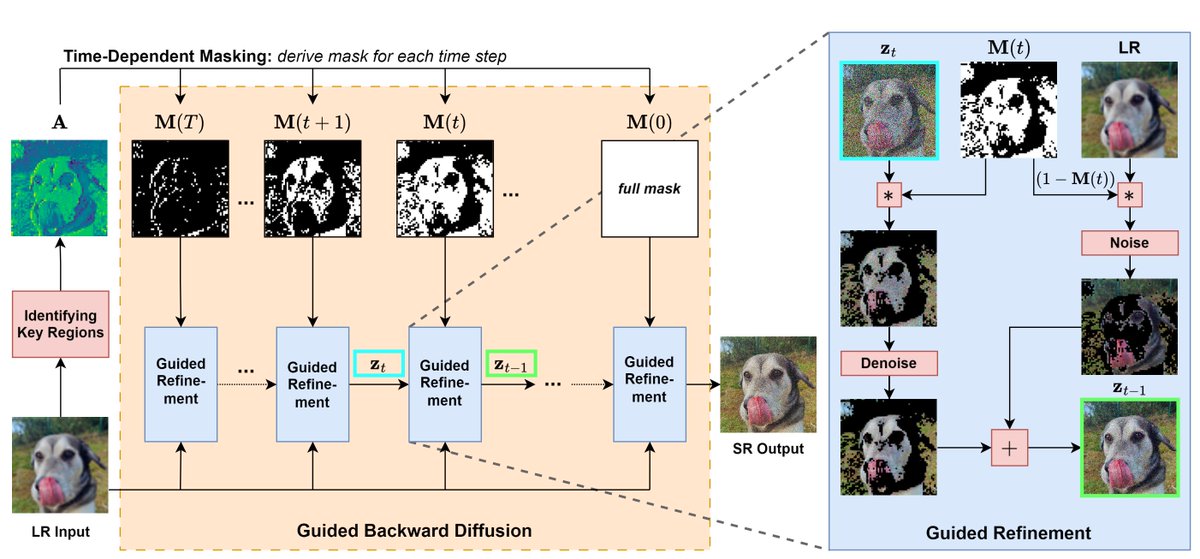
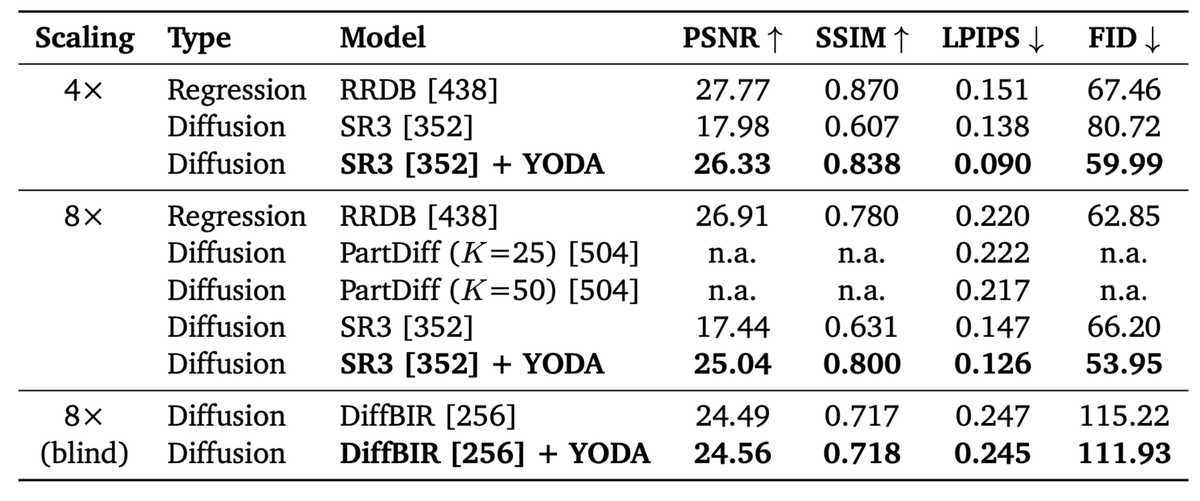
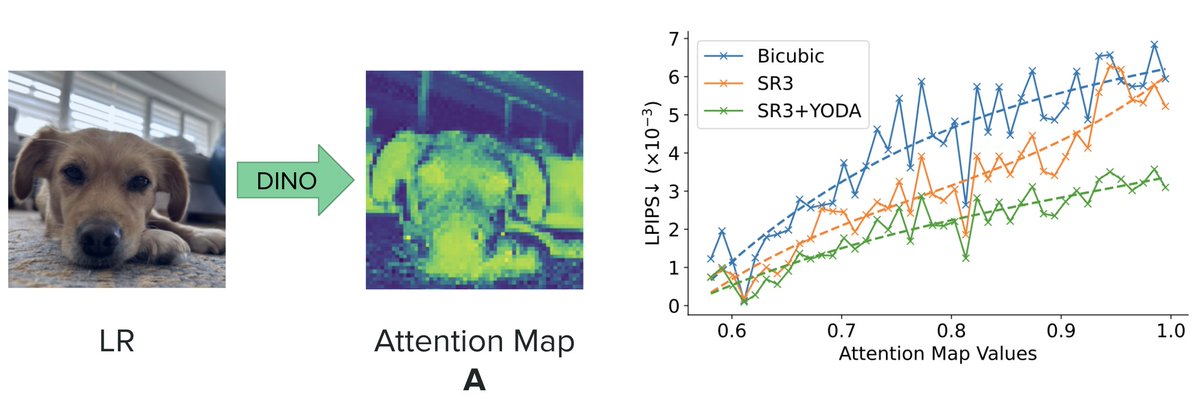
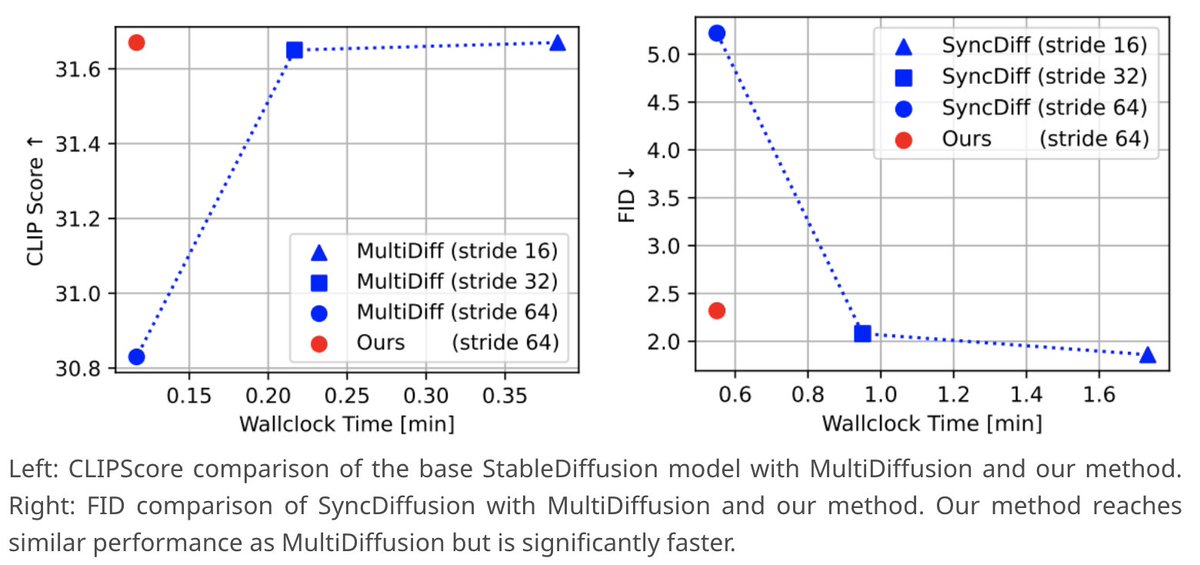
Sabitlenmiş Tweet

I am happy to share that SpotDiffusion was accepted to WACV 2025.
Page: spotdiffusion.github.io
Code: github.com/stanifrolov/sp…
Paper: arxiv.org/abs/2407.15507
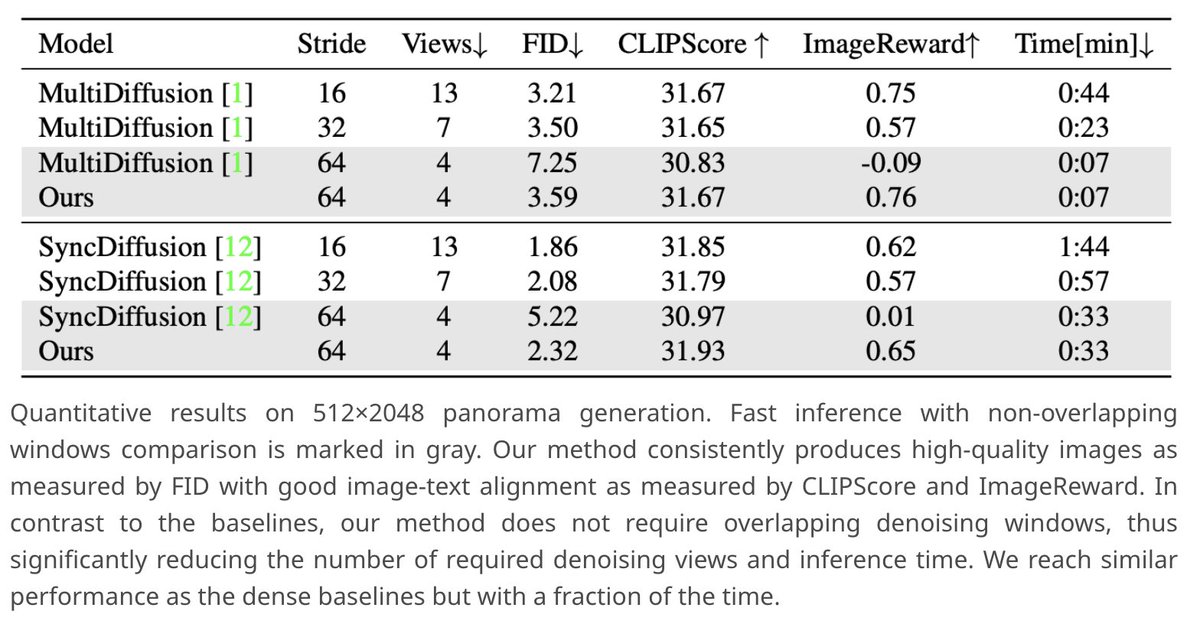
SpotDiffusion is an efficient method for seamless panorama generation from text. 🧵
English