Raghav Ramabadran retweetledi

Today we all lost our jobs.....
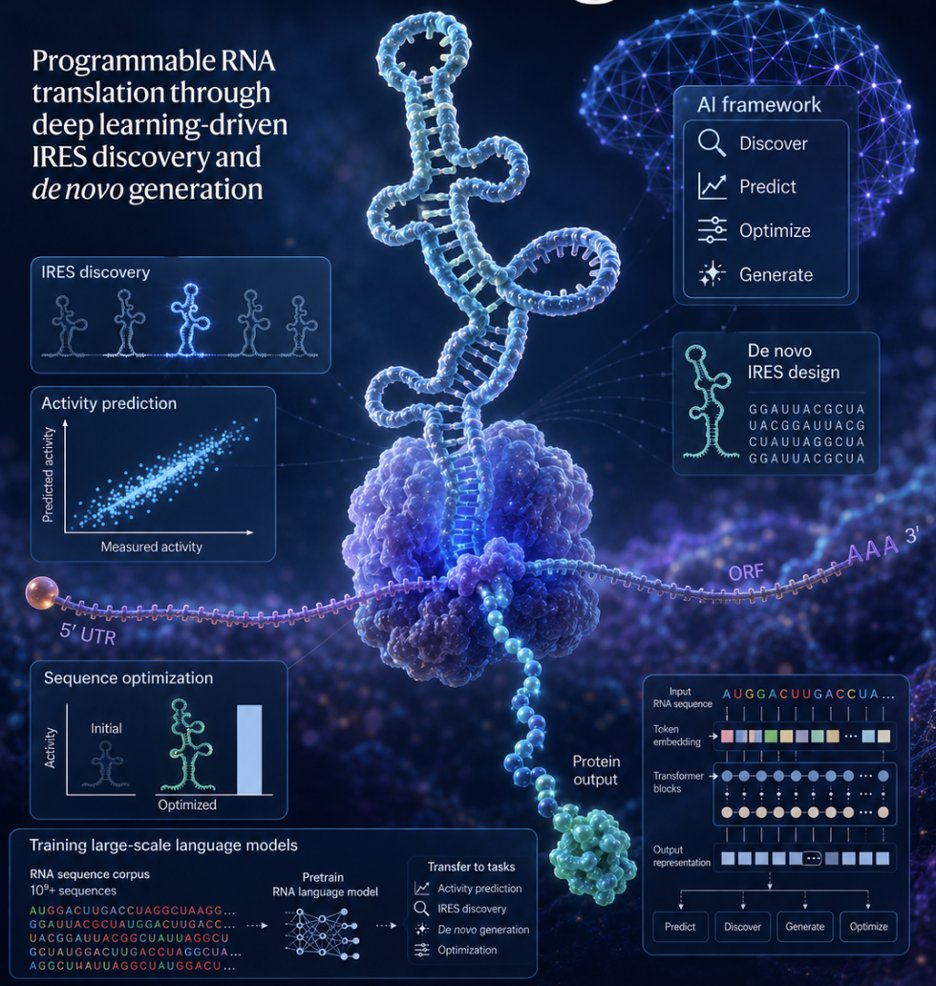
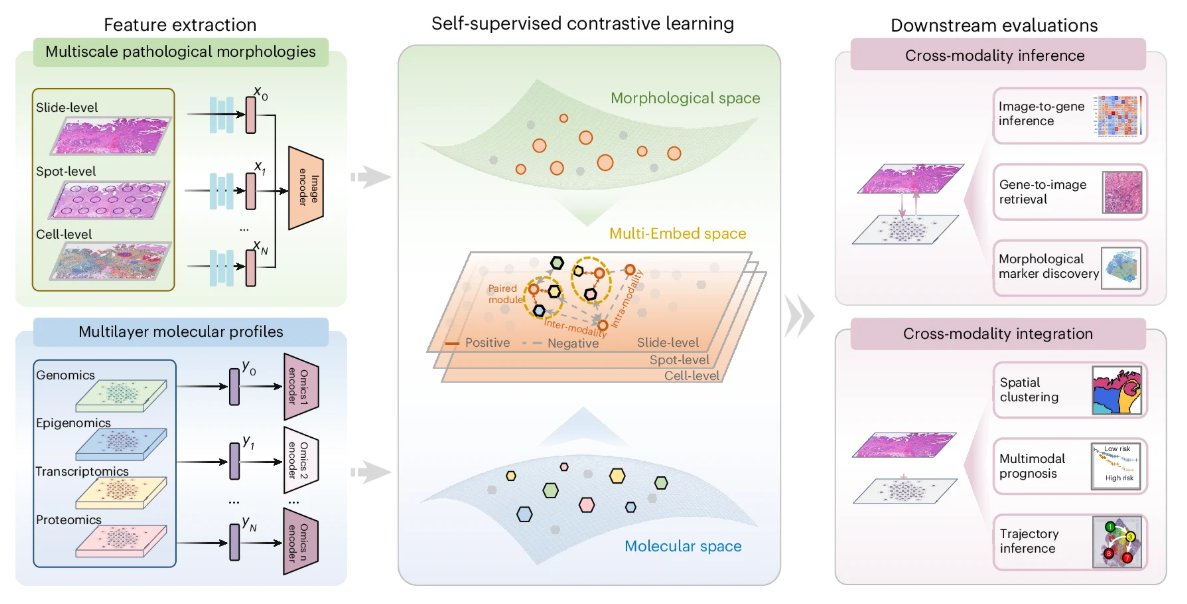
Three Nature papers showing that scientists in the conventional sense are obsolete
At least read the first one.... the AI replaced all things that the scientist does ....
nature.com/articles/s4158…

English