@torstensandor@audreyt I tried it today and I loved it, coming from codex with almost no terminal knowledge. I wish I had a remote control feature or a sandbox env though. Have you managed to solve for that?
Damn, I didn't know how good omp (oh my pi) is. It is an absolute joy to use.
Although I switched to the Codex desktop app mostly, omp makes me love the terminal again.
Thanks @audreyt for the tip!
omp.sh
I love using Hermes from @NousResearch as my 24/7 AI chief of staff because it's reliable, free, and open source.
Here's my new 45-minute free course that covers how to:
→ Install Hermes safely
→ Connect Telegram, voice, Google Workspace, and more
→ Create routines like morning briefing, business review, and health check
📌 Watch the full course now: youtu.be/2ZacwCbiLjg
Is it me, or the hourly / weekly limits from the basic subscriptions of Claude / Codex are quite helpful in making you learn how to use them efficiently? I wonder if creating "soft" restrictions is actually one of the ways to help people improve (and avoid $$$ bills).
@KSimback I agree with you to an extent - I have seen talent (both junior and senior) become so dependent on AI to the extent they are struggling to think without them. It's still a young research field, but early papers show that if we completely exclude friction, we risk cogn. decline!
@bnivanovX Anyone operating at the forefront of AI is likely challenging their cognitive capabilities quite a bit, there’s a constant learning motion you have to sustain
If you’re doing diligence on a new startup, you now need to assess their “AI nativeness” alongside team, product and market
Why? If they’re not at the forefront of using AI, it puts them at risk of not executing fast enough
It’s not a hard pass filter, but it is signal - here’s a few early tells:
1. Did they give you a .md file, alongside a deck, that you can feed to your LLM?
2. Did they build an interactive HTML deck or just send a PDF/docsend?
3. Do they talk about proprietary skills, data, evals or methods they’re using to build their product?
4. Do they ship significant product updates between meetings?
Not an exhaustive list, just some anecdotal signs that I’ve noticed
Hack of the day: "Look at my project [project location] - here's a copy paste of the 15 loops people are actually running article. What /goal should I run today to make my project way better?" Also 200k views on the article so far.
7/
The repo is public and MIT licensed. I know it is early and probably rough in places. It maybe be basic and table stakes for most of you. Nevertheless, I’d really appreciate feedback, issues, forks, criticism, and pointers from people who have been doing this longer than me.
6/
The part I personally care about most: Codex stays responsible for the local work and maintains a role as an orchestrator. ChatGPT returns text and then Codex decides whether to use it or not!
1/
Hey guys! Small personal milestone: I just launched my first public GitHub project - ChatGPT Subagent Bridge. It routes selected Codex tasks to ChatGPT in Chrome, captures the answer, saves it to the workspace, and lets Codex review it before use.
github.com/Adornoo/chatgp…
Long shot, but @jxnlco , @thsottiaux , @reach_vb@gabrielchua, can we make codex dynamically route tasks based on complexity e.g. have a master in 5.5 med and then auto go up to high /xhigh or delegate to 5.4 nano. Despite the generous resets, trying to max tokens!
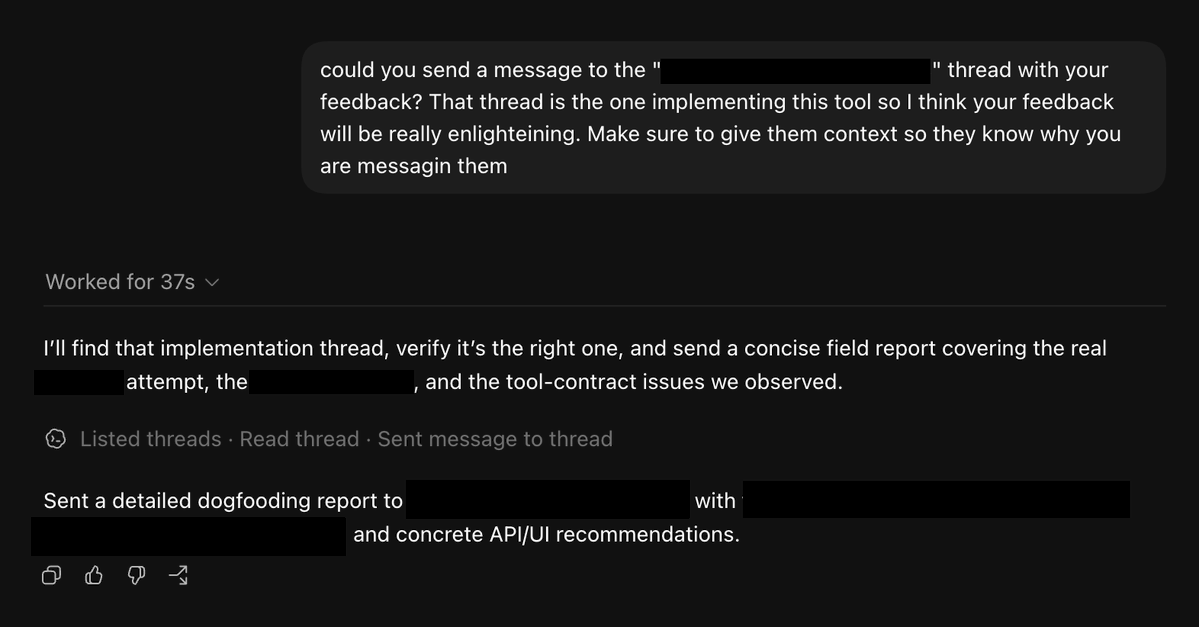
When I’m building new tools for Codex, I usually interview Codex about what the tool feels like to use so I can improve the ergonomics.
Now that threads can talk to each other, I can ask one Codex to interview another and send the notes back to the implementation thread.
I'm becoming a thinner and thinner Codex wrapper everyday.
@LLMJunky Have you figured out a logic on how to control
Which model is used for what to optimise tokens based on the task at hand? Now that you can add other models into codex some sort of an auto router will be great
One line of config is about to change how you Codex
Update 0.105.0 will bring configurable multi-agent depth. Your agents can now spawn agents that spawn agents.
Max agent depth used to be hard-coded to 1 level deep. Not anymore.
Root agent spawns a researcher. Researcher spawns a frontend agent, a backend agent, a tester, and code reviewer. All running in parallel.
The catch? It will annihilate your token budget. If you're one of those who struggles to use all the tokens on your Pro account, problem solved lol.
But beware: a single prompt could spiral into dozens of parallel model calls if setup irresponsibly.
But with the right scaffolding? Agent teams that divide work, delegate subtasks, and coordinate across branches.
Things are getting rather interesting, wouldn't you agree?
Instructions in ze comments. 👇
I know openai still aren't confident about auto model routing cause it isn't even an experimental feature on codex. I have to manually change to spark like some sort of token impoverished ape.
@OpenRouter What is the routing logic or how do the models make decisions when to delegate up or when to delegate down? Is this complex guidance that you have developed and are we able to edit or create custom instructions?
New server tool: Subagent 🤖
Your model can now delegate focused sub-tasks to a smaller, cheaper, faster model mid-generation.
The big model orchestrates, the subagent executes. The subagent can use any model on OpenRouter.