@nickcammarata It’s so satisfying to interpret a comp bio model and see that it learned both true biology and previously unknown biology
English
Brennan Simon
13 posts
@brennan__simon
Agents for Computational Cancer Research - Graduate Student, Cancer Biology PhD Program Stanford University


Building a personal knowledge base for my agents is increasingly where I spend my time these days. Like @karpathy, I also use Obsidian for my MD vaults. What's different in my approach is that I curate research papers on a daily basis and have actually tuned a Skill for months to find high-signal, relevant papers. I was reviewing and curating papers manually for some time, but now it's all automated as it has gotten so good at capturing what I consider the best of the best. There are so many papers these days, so this is a big deal. You all get to benefit from that with the papers I feature in my timeline and on @dair_ai. The papers are indexed using @tobi qmd cli tool (all of it in markdown files along with useful metadata). So good for semantic search and surfacing insights, unlike anything out there. I am a visual person, so I then started to experiment with how to leverage this personal knowledge base of research papers inside my new interactive artifact generator (mcp tools inside my agent orchestrator system). The result is what you see in the clip. 100s of papers with all sorts of insights visualized. I keep track of research papers daily, so believe me when I tell you that this system is absolutely insane at surfacing insights. This is the result of months of tinkering on how to index research and leverage agent automations for wikification and robust documentation. But this is just the beginning. The visual artifact (which is interactive too) can be changed dynamically as I please. I can prompt my agent to throw any data at it. I can add different views to the data. Different interactions. I feel like this is the most personalized research system I have ever built and used, and it's not even close. The knowledge that the agents are able to surface from this basic setup is already extremely useful as I experiment with new agentic engineering concepts. I feel like this knowledge layer and the higher-level ones I am working on will allow me to maximize other automation tools like autoresearch. The research is only as good as the research questions. And the research questions are only as good as the insights the agents have access to. Where I am spending time now is on how to make this more actionable. I am obsessed about the search problem here. The automations, autoresearch, ralph research loop (I built one months ago) are easier to build but are only as good as what you feed them. Work in progress. More updates soon. Back to building.
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then: - the human iterates on the prompt (.md) - the AI agent iterates on the training code (.py) The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc. github.com/karpathy/autor… Part code, part sci-fi, and a pinch of psychosis :)
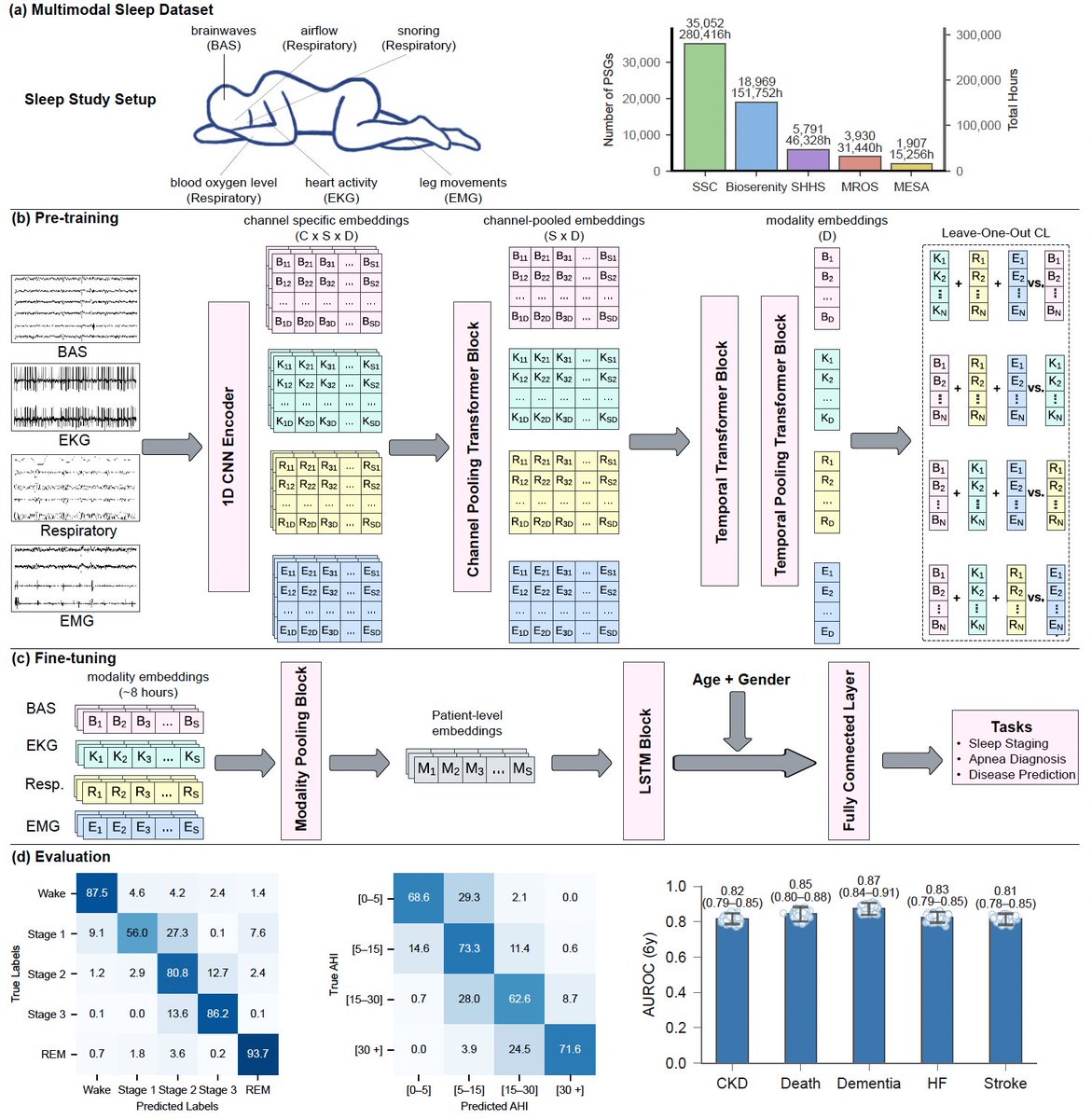
Nature research paper: Towards end-to-end automation of AI research go.nature.com/4rSOGFK