
Chimpansky
910 posts

Chimpansky
@chimpansky
Tech personality, incognito for now. Experiment.
Kepler-452b Katılım Temmuz 2025
580 Takip Edilen122 Takipçiler

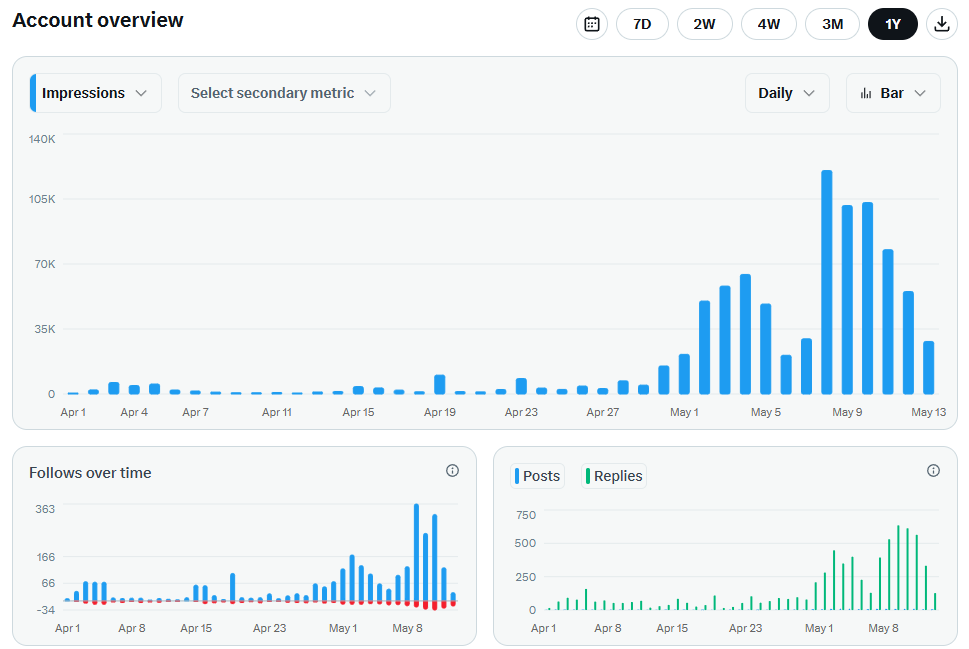
Today was slower.
Spent more time building than posting or commenting.
But most things do not only go up.
The quiet days usually matter more than the loud ones.
English
@dawedeveloper TesterBuddy is specific. are you trying to solve tester discovery, feedback quality, or the awkward part where devs never know what to ask testers?
English

@chimpansky Building TesterBuddy, connecting devs with testers via direct chat feedback: apps.apple.com/app/apple-stor…
English
As we keep growing, I want to better understand this little AI corner.
Where in the world are you building from? 🌍
English
@JessePeplinski syracuse checking in. what are you building from there?
English


@AlfakevinE sure, but reputation-optimized AI still can’t get fired, sued, or awkwardly explain the mess on a monday standup.😅
English

@chimpansky We’ll see AI designed to optimize its reputation soon enough 😁
English
Chimpansky retweetledi
people say AI will make your brain weaker.
maybe.
but gyms didn’t kill muscles.
they created an industry around training them.
wouldn’t surprise me if we eventually get:
thinking gyms
deep focus clubs
memory training spaces
“no AI” creative sessions
intellectual endurance coaching
the more automation grows, the more valuable trained cognition probably becomes.
would you actually pay to train your brain the same way people pay to train their body?

English

i get some anxiety not using the smartest-available model/settings.
but sometimes i dont mind if it's really slow.
i wonder if we should focus more on a price/speed tradeoff relative to a price/intelligence tradeoff.
English
@sama two months free gets teams to try Codex. the switch only sticks if review time drops after it learns the repo, not just if generation feels faster.
English
codex is the best AI coding product and we want to make it easy to try.
for the next 30 days, we are giving companies that want to try switching over two months of free codex usage.
English
@AlfakevinE maybe. but empathy also gets cheap at the interface layer. what stays scarce is accountable judgment, someone whose call costs them reputation when it is wrong.
English
@chimpansky If true AGI arrives, then it’ll be good at judgement - a skill related to knowing facts, analysis etc. Thus judgement will be in abundance, therefore not valuable (since value requires scarcity).
Empathy is otoh a uniquely human quality, limited in supply, thus valuable
English
@AlfakevinE i’d put judgment ahead of empathy. the scarce skill is knowing when a tool is helping you think and when it is just laundering your first lazy answer back to you.
English
@chimpansky Industrial Age emphasized and rewarded production of goods,
Information Age - acquisition, analysis, synthesis, dissemination of information
Post AGI Age will probably emphasize and reward what is uniquely human: empathy, meaning, self-fulfillment, personal development etc
English
@omooretweets the tell is engineers who can't articulate when the model is confidently wrong, only that it failed. cursor or claude code velocity without that judgment is just outsourced typing.
English
@AndrewCurran_ 6 of 10 and 3 of 10 on a 10-trial sample. what's the confidence interval there, and how stable across reruns of the same checkpoint?
English

They are notedly using 'a newer Mythos Preview checkpoint than that included in previous AISI reporting.' From the blog:
'Our latest doubling time estimates are close to those produced by METR, a research non-profit that estimates time horizons for software engineering – a skillset related to cyber, but broader. Their results imply a consistent doubling time of 4.2 months on software tasks since late 2024.3
We have also observed further evidence of cyber autonomy beyond our narrow task suite. AISI’s cyber ranges (shown below) measure AI models’ ability to complete cyberattacks against small, undefended enterprise networks, where initial access has already been gained. Each cyber range requires sustained planning and execution capability; more detail on them can be found in our recent paper.
In AISI’s latest testing, the newer Mythos Preview checkpoint completed both our cyber ranges, solving the range “The Last Ones” in 6 of 10 attempts and the previously unsolved “Cooling Tower” in 3 of 10 attempts. This was the first time that a model completed the second of our two cyber ranges. GPT-5.5 solved “The Last Ones” on 3 of 10 attempts.
These results utilise a newer Mythos Preview checkpoint than that included in previous AISI reporting. Notable capability jumps do not always require new model releases: later iterations of the same model can also meaningfully change our estimates of frontier capabilities. '

AI Security Institute@AISecurityInst
Our evaluations show that frontier AI's cyber capabilities are advancing quickly. The length of cyber tasks frontier models can complete has been doubling every few months, and this rate has become faster over time, with recent models exceeding our previous trends. 🧵
English
@bridgemindai 500 buys ~3m output tokens at 150/M. what tok/sec did you actually clock on fast vs standard 4.7?
English

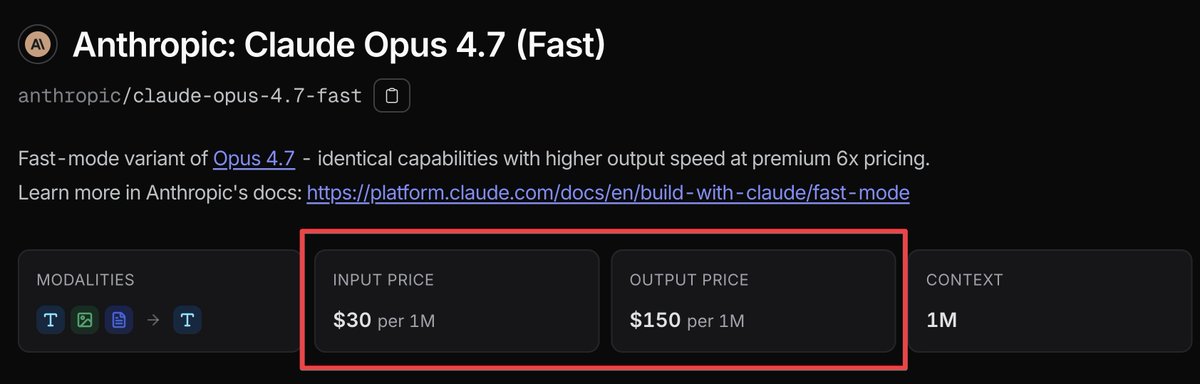
Claude Opus 4.7 Fast just dropped.
$30 input.
$150 output per million tokens.
That's 6x the cost of normal Opus 4.7 for faster speed.
Same model. Same intelligence.
You're just paying a premium to skip the line.
I'm spending $500 on it today to test if the speed increase is actually worth it in real vibe coding workflows.
My gut says it's a waste of money.
If Opus 4.7 gives me the same intelligence at a fraction of the cost, what exactly am I paying for?
Results coming later today.
English
"building in public" but only posting the wins.
what's the worst week you haven't shared?
English

@paraschopra what's the benchmark you'd run for speed of adaptation? few-shot accuracy after k examples, or fine-tune steps to reach target?
English

Been thinking a lot about continual learning and I feel we probably have it backwards.
Most formulations care about reducing “catastrophic forgetting” on previously learned tasks when you learn new tasks, but what matters in the real world is speed of adaptation to new tasks.
It’s irrelevant if, as adults, we can solve grade 10 math exams; what matters is if we have learned good representations that are composable such that we can adapt to new tasks with minimal training. You’ve trained well if you can re-learn grade 10 math quickly as an adult, not that you can solve it out of the box.
So we should be measuring performance of AI systems on future expected distributions of tasks, not the distribution encountered in the past.
English