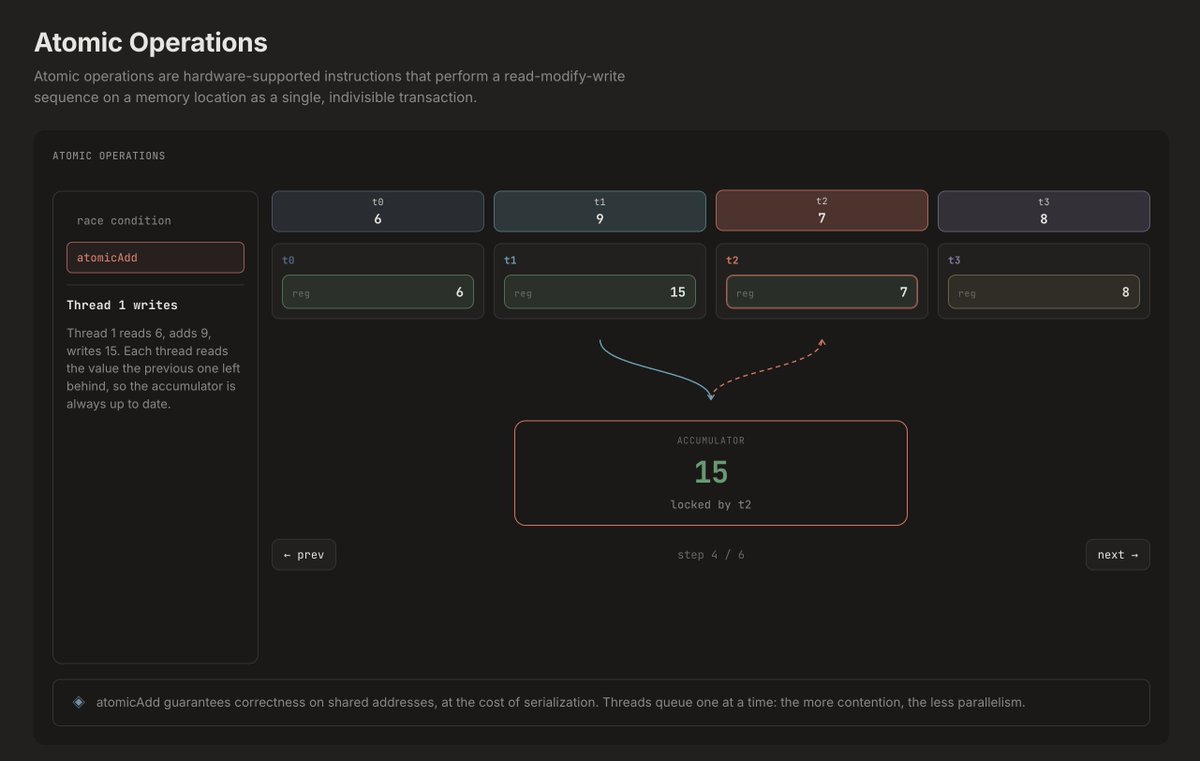
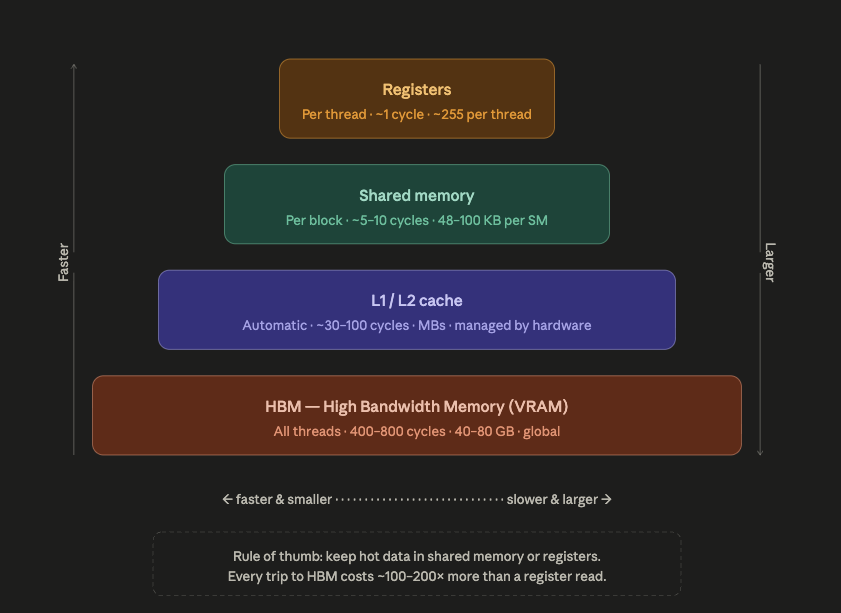
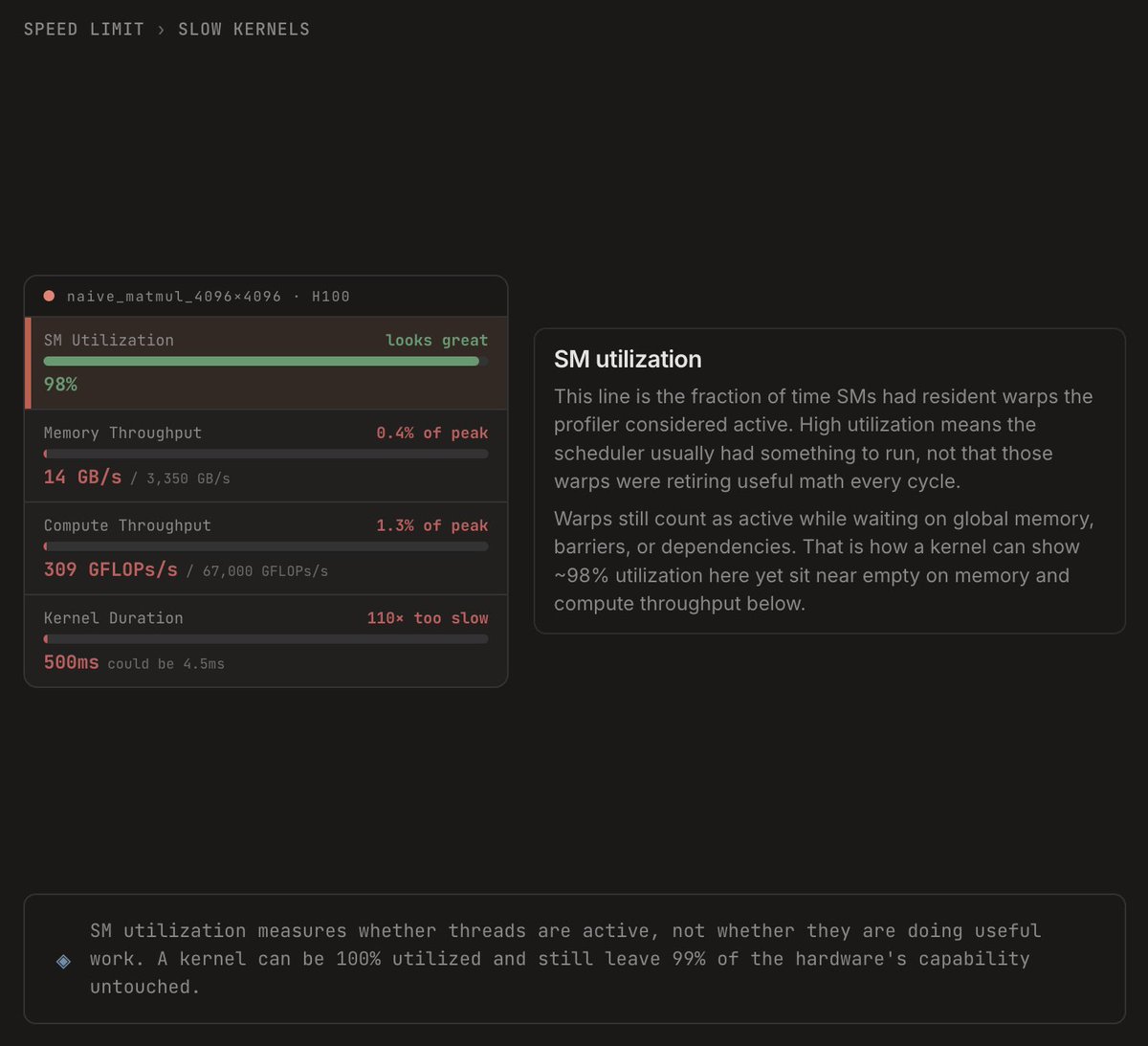
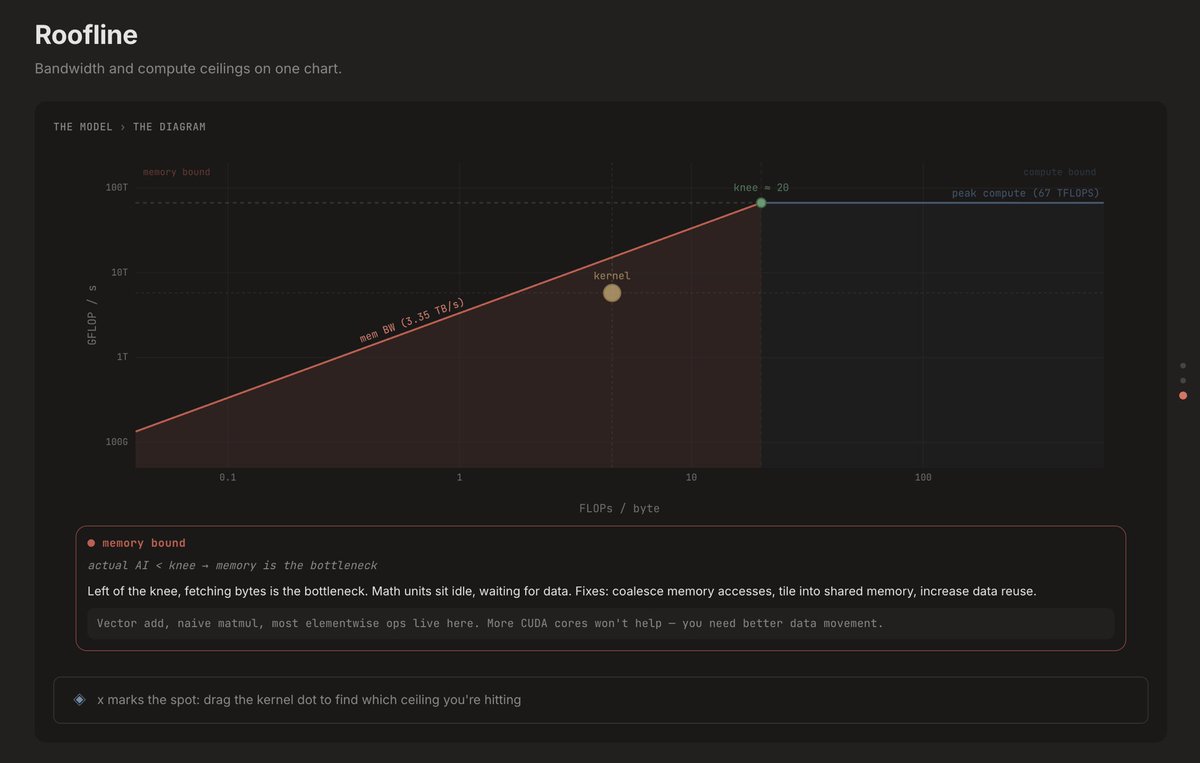
Sabitlenmiş Tweet

this is how i wish i learned GPU fundamentals
not a lengthy textbook. not a static image. every concept is an interactive visualization.
covering the SM architecture, memory coalescing, synchronization, and more.
what concepts do you want to see next?
brrrviz.com
English