Bryce
97 posts





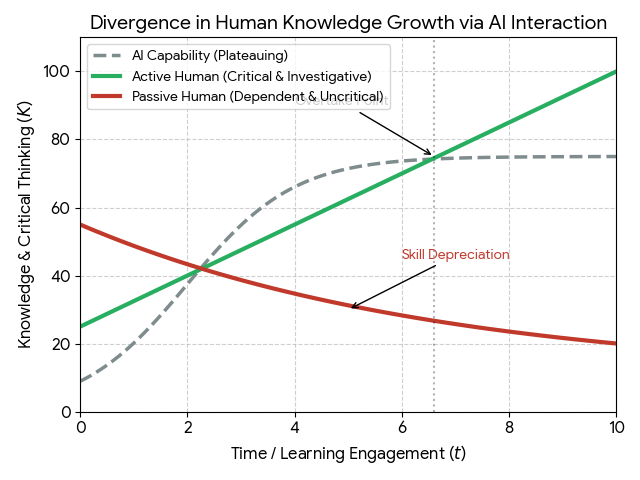


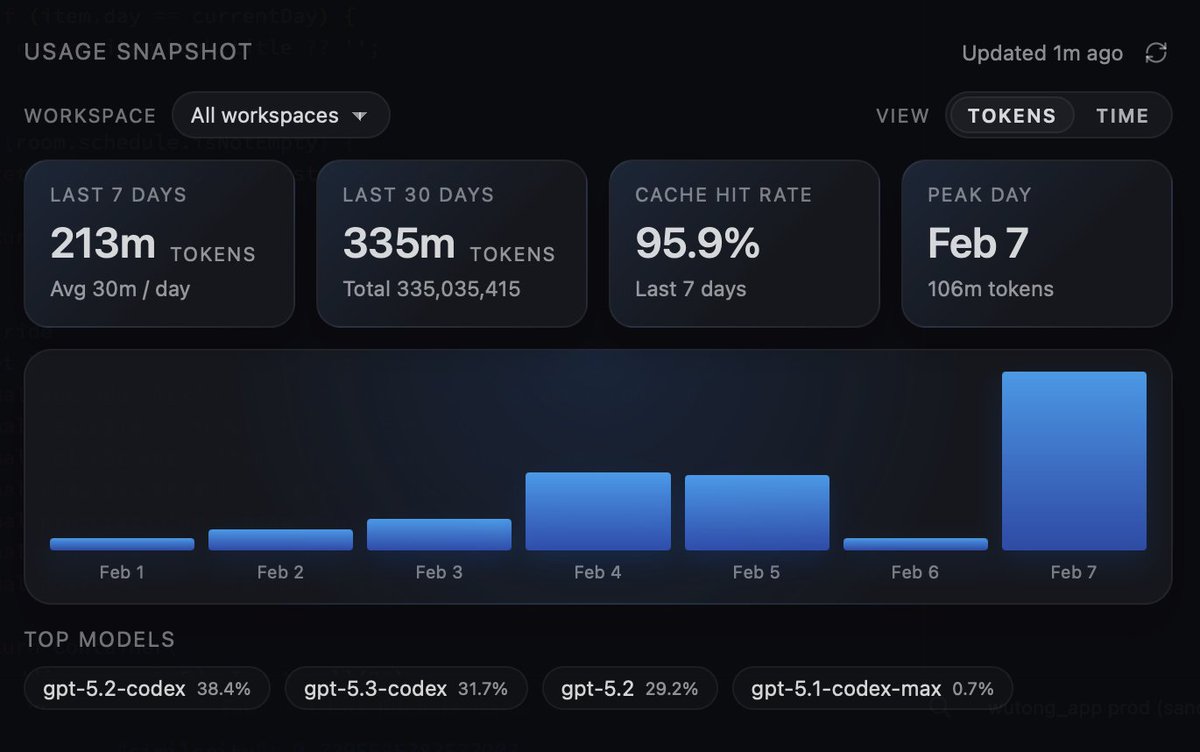

现在有部分人担心的是,AI 把项目改成黑盒,架构自己理解不了了,从而以后不好维护了,所以还需要去读 AI 代码,识别 AI 代码的实现问题。 咋说呢,我觉得这也很正常。我甚至也不知道了,就是说 AI 代码到底应不应该去考虑架构、考虑实现。 现在更像是一个分水岭,从手工编程时代迈向 AI 编程时代的重要转折点,虽然推特上大多数应该都是毫无疑问的全 AI 编程,但是仍有大部分的群体,是手工编程的。 到底怎么看这个问题,我觉得我也没有特别能说服别人的答案。


Codex team is working on a few experimental projects that are starting to shape up and I’m excited to share more about soon. But I’m curious, what would you like to see ship or improved by the end of the year other than better models?



I'm noticing that due to (I think?) a lot of benchmarkmaxxing on long horizon tasks, LLMs are becoming a little too agentic by default, a little beyond my average use case. For example in coding, the models now tend to reason for a fairly long time, they have an inclination to start listing and grepping files all across the entire repo, they do repeated web searchers, they over-analyze and over-think little rare edge cases even in code that is knowingly incomplete and under active development, and often come back ~minutes later even for simple queries. This might make sense for long-running tasks but it's less of a good fit for more "in the loop" iterated development that I still do a lot of, or if I'm just looking for a quick spot check before running a script, just in case I got some indexing wrong or made some dumb error. So I find myself quite often stopping the LLMs with variations of "Stop, you're way overthinking this. Look at only this single file. Do not use any tools. Do not over-engineer", etc. Basically as the default starts to slowly creep into the "ultrathink" super agentic mode, I feel a need for the reverse, and more generally good ways to indicate or communicate intent / stakes, from "just have a quick look" all the way to "go off for 30 minutes, come back when absolutely certain".