
Bram Wasti
415 posts

Bram Wasti
@bwasti
working on fast inference things with msl
NY Katılım Ocak 2011
292 Takip Edilen1.1K Takipçiler

Actually, on second thought, I would divide this into 3 categories. Fundamentally, for really long contexts, you're bottlenecked by global attention needing linear memory with context length. So the common remediations we see are:
1. Make an attention layer only attend to a local region - sliding window attention/gdn/linear attention
2. Make more of your layers use some local attention instead of global - interleaved attention
3. For your remaining global layers, make the kv cache per token smaller - gqa/MLA/kv tying/quantization
Horace He@cHHillee
@yoavgo The two biggest standard things are GQA/MLA and interleaved sliding window attention.
English
Bram Wasti retweetledi

We made Muon run up to 2x faster for free!
Introducing Gram Newton-Schulz: a mathematically equivalent but computationally faster Newton-Schulz algorithm for polar decomposition.
Gram Newton-Schulz rewrites Newton-Schulz such that instead of iterating on the expensive rectangular X matrix, we iterate on the small, square, symmetric XX^T Gram matrix to reduce FLOPs. This allows us to make more use of fast symmetric GEMM kernels on Hopper and Blackwell, halving the FLOPs of each of those GEMMs.
Gram Newton-Schulz is a drop-in replacement of Newton-Schulz for your Muon use case: we see validation perplexity preserved within 0.01, and share our (long!) journey stabilizing this algorithm and ensuring that training quality is preserved above all else.
This was a super fun project with @noahamsel, @berlinchen, and @tri_dao that spanned theory, numerical analysis, and ML systems! Blog and codebase linked below 🧵
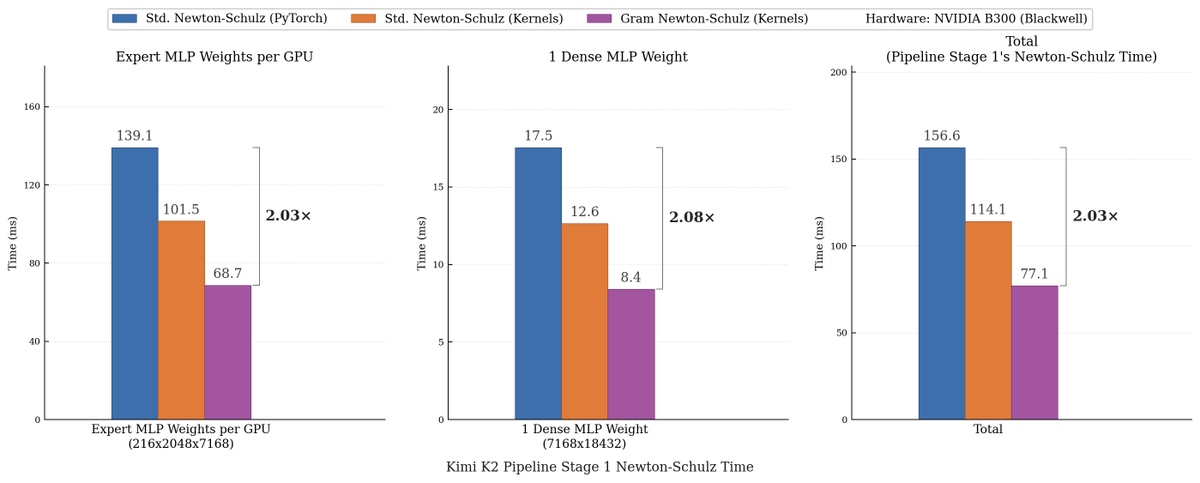
English
Bram Wasti retweetledi

🚨BREAKING AI NEWS 🚨
A Cambridge study just dropped that PROVES you can exactly calculate the slopes of functions at an arbitrary point. This UNLOCKS gradient optimization that experts say is vital for AGI.
Download our app for a daily AI digest delivered to your inbox

English

pretty much no AI can classify a hand painted CIFAR-100 clock. a very under-explored dataset!



English
when claude comes up with a root cause it already debunked three chat compressions ago

English
yep, definitely a big part of the challenge and the reason I'm starting with a fixed size font for now. I'm moving from pure frame prediction to delta prediction (over char-by-char rendnering) which will only require learning next position/shape of the letters on top of the actual latent text structure
big issue has been finding a good loss to capture the low freq position data and the high freq font-shape data at once
English

@bwasti going to guess the latent structure (the word sequence) is pretty hard to model one pixel at a time though... will be curious if you get anything other than word soup out of it (or at what scale language starts getting modeled!)
English
Bram Wasti retweetledi

🥝 Meet Kimi K2.5, Open-Source Visual Agentic Intelligence.
🔹 Global SOTA on Agentic Benchmarks: HLE full set (50.2%), BrowseComp (74.9%)
🔹 Open-source SOTA on Vision and Coding: MMMU Pro (78.5%), VideoMMMU (86.6%), SWE-bench Verified (76.8%)
🔹 Code with Taste: turn chats, images & videos into aesthetic websites with expressive motion.
🔹 Agent Swarm (Beta): self-directed agents working in parallel, at scale. Up to 100 sub-agents, 1,500 tool calls, 4.5× faster compared with single-agent setup.
-
🥝 K2.5 is now live on kimi.com in chat mode and agent mode.
🥝 K2.5 Agent Swarm in beta for high-tier users.
🥝 For production-grade coding, you can pair K2.5 with Kimi Code: kimi.com/code
-
🔗 API: platform.moonshot.ai
🔗 Tech blog: kimi.com/blogs/kimi-k2-…
🔗 Weights & code: huggingface.co/moonshotai/Kim…
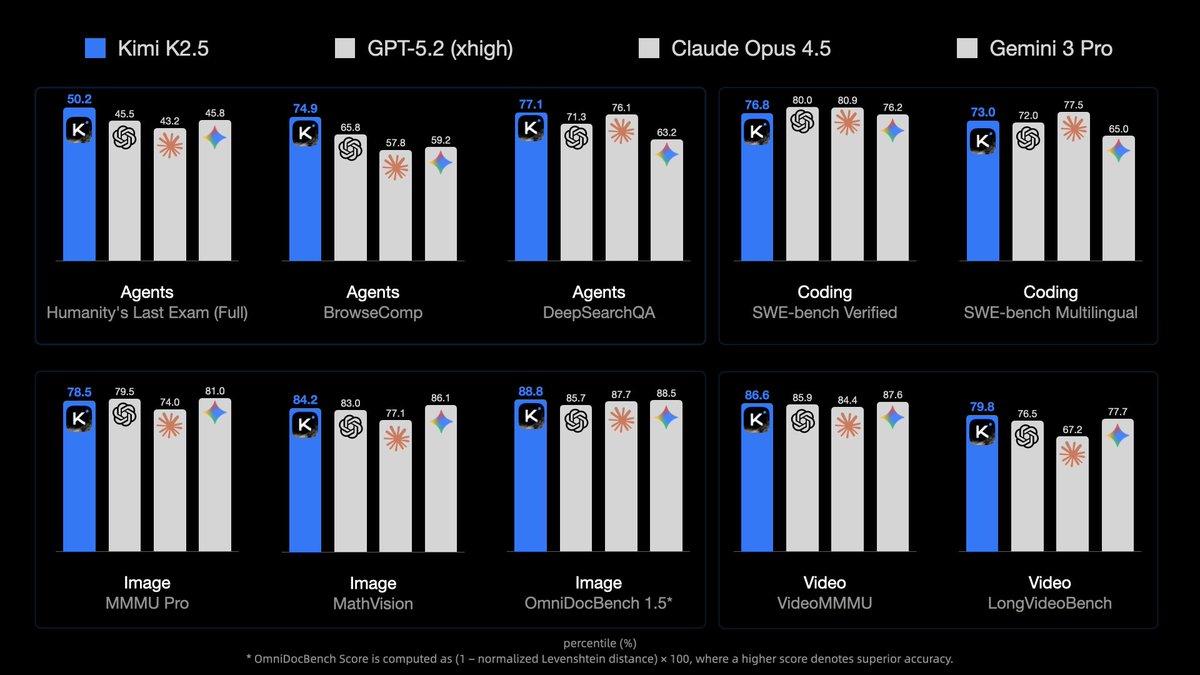
English
@rustyryan still playing with the exact setup, but directly over pixels means an output dim of 16k which isn’t terrible at first glance…
English
ive found a key to complex systems dev with AI involves iterating heavily on a logging system as a first class citizen. that lets the AI reconcile complex logic against what actually happens (races, slowdowns, deadlocks etc)
stream based designs lend themselves well to that (github.com/bwasti/gt)
English

@bingxu_’s VibeTensor is a rare verification of a fundamental question: can AI write complicated system code? The answer is “yes but” - it’s getting there very quickly, and if we get more principles right, then AI will fully beat human coders. It’s like AlphaGo in Jan 2015.
Bing Xu@bingxu_
Just open-sourced VibeTensor — the first deep learning system fully generated by an AI agent, with 0 lines of human-written code: github.com/NVlabs/vibeten… It’s a working DL system with RCU style dispatcher, a cache allocator and reverse-mode autograd. The agent also invented a Fabric Tensor system — something that doesn’t exist in any current framework. The Vibe Kernel includes 13 kinds and 47k LOC of generated Triton and CuteDSL kernels with strong performance. VibeTensor was generated by our 4th-generation agent. It shows a “Frankenstein Effect”: the system is correct, but some critical paths are designed in inefficient ways. As a result, performance isn’t comparable to PyTorch. I haven’t written a single line of code since summer 2025. I started this effort after @karpathy 's podcast — I didn’t agree with his arguments, so Terry Chen and I began using it as a stress test for our agents. The “Frankenstein Effect” ended up exposing some of our agent’s limitations — but the direction is clear.
English

would be so nice to have claude venvs. `source my_claude_env/activate` without having to check your dir for the configs/mds
cc @bcherny
English
Bram Wasti retweetledi


@typedfemale Librae bakery is my favorite croissant on planet earth, where does that put me?
English

i ignore the advice of anyone who has supermoon bakehouse on their list of best new york bakeries
English
Bram Wasti retweetledi

Our new paper shows that RoPE—the positional encoding used in most modern LLMs like Qwen, Gemma, DeepSeek—has a fundamental flaw: it entangles "what" (content) and "where" (position) information.
Our fix (PoPE) is simple but powerful. Paper: arxiv.org/abs/2509.10534
English
@CSProfKGD I remember implementing HOG features in SIMD (SSE2!) and then again in pure javascript (before web assembly)
English

This generation of researchers will never understand this.


Kosta Derpanis (sabbatical in Zurich)@CSProfKGD
Telling your students about research before the ImageNet moment
English
do we really need things like garbage collection in an AI-native world? how much of the overhead in high-level languages can just disappear with vibe-coded stacks?
zig is looking more appealing every day
English
github:bwasti/binfer -- an experiment with fast inference serving using bun + cuda.
trying to focus on speed / UX experiments, like language overhead and startup time. not trying to maintain this as a legit framework (use vllm or sglang)
GIF
English