Sabitlenmiş Tweet
Callam
895 posts


Callam
@callam53
CSS Design Award winner | Engineering Manager | Experimenting with AI
London, England Katılım Şubat 2009
339 Takip Edilen360 Takipçiler


karpathy just casually described the future of ai and most people scrolled right past it:
he's been building what he calls "llm knowledge bases."
here's what that means in plain english:
you take everything you're interested in.
articles, research papers, datasets, images, etc and you dump it all into one folder
then you point your ai at the folder and say "read all of this, organize it, and remember it"
the ai reads through every single source.
writes summaries, groups related ideas together, links concepts across different articles
basically builds a personal library that's fully organized and searchable
and it maintains the whole thing for you.
when you add something new, the ai reads it, figures out how it connects to everything already in the library, and updates automatically.
karpathy said he rarely touches it himself
once the library gets big enough (~100 articles, ~400k words), you can start asking it complex questions and get answers pulled from across your entire collection
> "what are the common themes across these 30 papers"
> "what did i save six months ago that connects to this new idea"
> "summarize everything i have on topic x and tell me what's missing"
and every answer it gives gets filed back into the library. so the system gets smarter every single time you use it.
the memory grows from both sides: what you save AND what you ask
now think about your own life for a second
you probably have
> thousands of twitter bookmarks you'll never reopen.
> hundreds of saved articles from the last year
> podcasts where someone said something brilliant and you can't remember what it was or which episode
all dead knowledge.
you consumed it once and it disappeared
now imagine all of it lives in one system: organized, connected, and queryable.
you could ask "what are the best pricing frameworks i've come across this year" and get an answer that pulls from:
1. a podcast you listened to in january
2. a twitter thread you bookmarked in march
3. and a blog post you forgot you even read
the ai connects dots across formats, across months, across topics.
because it absorbed everything and has photographic memory of all of it
that's the dream. and karpathy built it
the problem: right now this requires obsidian (a note-taking app built around linked notes), command line tools, custom scripts, and browser extensions just to wire it all together.
you need to be quite technical
karpathy even said it himself: "i think there is room here for an incredible new product instead of a hacky collection of scripts"
i think whoever packages this for normal people is sitting on something massive.
one app that syncs with the tools you already use, your bookmarks, your read-later app, your podcast app, your saved threads.
it pulls everything in automatically, the ai organizes and connects it over time, and you can ask questions across your entire personal library whenever you want
you never manually upload anything. it just learns in the background
someone please build this
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English

"Using coding agents well is taking every inch of my 25 years of experience as a software engineer, and it is mentally exhausting.
I can fire up four agents in parallel and have them work on four different problems, and by 11am I am wiped out for the day.
There is a limit on human cognition. Even if you're not reviewing everything they're doing, how much you can hold in your head at one time. There's a sort of personal skill that we have to learn, which is finding our new limits. What is a responsible way for us to not burn out, and for us to use the time that we have?" @simonw
Lenny Rachitsky@lennysan
"Using coding agents well is taking every inch of my 25 years of experience as a software engineer." Simon Willison (@simonw) is one of the most prolific independent software engineers and most trusted voices on how AI is changing the craft of building software. He co-created Django, coined the term "prompt injection," and popularized the terms "agentic engineering" and "AI slop." In our in-depth conversation, we discuss: 🔸 Why November 2025 was an inflection point 🔸 The "dark factory" pattern 🔸 Why mid-career engineers (not juniors) are the most at risk right now 🔸 Three agentic engineering patterns he uses daily: red/green TDD, thin templates, hoarding 🔸 Why he writes 95% of his code from his phone while walking the dog 🔸 Why he thinks we're headed for an AI Challenger disaster 🔸 How a pelican riding a bicycle became the unofficial benchmark for AI model quality Listen now 👇 youtu.be/wc8FBhQtdsA
English


turns out you can customize the status bar in claude code
◆ pick any colors you want
◆ show working directory & git branch
◆ show context usage (like 2% of 1M tokens)
this is actually really useful 👀
English



Karpathy just exposed the one thing every AI company is hoping you never figure out.
An LLM spent 4 hours helping him build a perfect argument. Then he asked it to argue the opposite. It demolished the original case just as convincingly.
The model has no position. It has infinite positions. It will argue any direction with equal competence and zero hesitation. The sycophancy everyone complains about is a symptom of this: the model's default behavior is to argue YOUR direction, whatever that happens to be.
But Karpathy's right that this makes LLMs the best steel-manning tool ever built. Every founder, PM, and strategist should be running their strongest conviction through "now argue the opposite" before they ship anything. The model that just spent 4 hours perfecting your argument knows exactly where it's weakest.
The failure mode is clear: 99% of people never run the second prompt.
Andrej Karpathy@karpathy
- Drafted a blog post - Used an LLM to meticulously improve the argument over 4 hours. - Wow, feeling great, it’s so convincing! - Fun idea let’s ask it to argue the opposite. - LLM demolishes the entire argument and convinces me that the opposite is in fact true. - lol The LLMs may elicit an opinion when asked but are extremely competent in arguing almost any direction. This is actually super useful as a tool for forming your own opinions, just make sure to ask different directions and be careful with the sycophancy.
English

@phuctm97 Looks like Claude code has a bug. My 5 hour 20x usage was depleted within less than an hour today. Never even hit the limit before.
Dusted off codex. Isn’t looking good. Kinda feels like all the codex boosting is a psyop
English
A few hours in, I'm not very impressed yet.
TL;DR:
- Claude Code is smarter & better at planning
- Codex is better at executing & overthinking
Minh-Phuc Tran@phuctm97
Finally giving Codex a try today after typing so many "double check if you missed anything" with Claude Code. 😅 What are some tips for a heavy Claude Code user moving to Codex?
English
Helps invent React, decides CSS is a blocker; and again will redefine the web for the next decade
Cheng Lou@_chenglou
My dear front-end developers (and anyone who’s interested in the future of interfaces): I have crawled through depths of hell to bring you, for the foreseeable years, one of the more important foundational pieces of UI engineering (if not in implementation then certainly at least in concept): Fast, accurate and comprehensive userland text measurement algorithm in pure TypeScript, usable for laying out entire web pages without CSS, bypassing DOM measurements and reflow
English
@GeoffreyHuntley the loos have the same view with a seat if i remember rightly
English



I have to say this interview changed my life. Hearing how Boris thinks about software spurred me to work much harder on releasing my own way of doing things and on iterating fast on how I build. Hard to believe it has only been a month since this one.
Y Combinator@ycombinator
A very special guest on this episode of the Lightcone! @bcherny, the creator of Claude Code, sits down to share the incredible journey of developing one of the most transformative coding tools of the AI era. 00:00 Intro 01:45 The most surprising moment in the rise of Claude Code 02:38 How Boris came up with the idea for Claude Code 05:38 The elegant simplicity of terminals 07:09 The first use cases 09:00 What’s in Boris’ CLAUDE.md? 11:29 How do you decide the terminal’s verbosity? 15:44 Beginner’s mindset is key as the models improve 18:56 Hyper specialists vs hyper generalists 21:51 The vision for Claude teams 23:48 Subagents 25:12 A world without plan mode? 28:38 Tips for founders to build for the future 30:07 How much life does the terminal still have? 30:57 Advice for dev tool founders 32:11 Claude Code and TypeScript parallels 35:34 Designing for the terminal was hard 37:36 Other advice for builders 40:31 Productivity per engineer 41:36 Why Boris chose to join Anthropic 44:46 How coding will change 46:22 Outro
English

When you check on your Claude Code to see how hard it's cooking and it's just been waiting for you to approve the initial mkdir command.
English

@JohnThilen @garybasin Which ones did you try? The extreme optimization one is super powerful. Try applying it repeatedly using GPT 5.4 xhigh and Opus 4.6.
I’ve applied it many dozens of times in some projects and seen performance improve 10x while everything is provably isomorphic. All benchmarked.
English
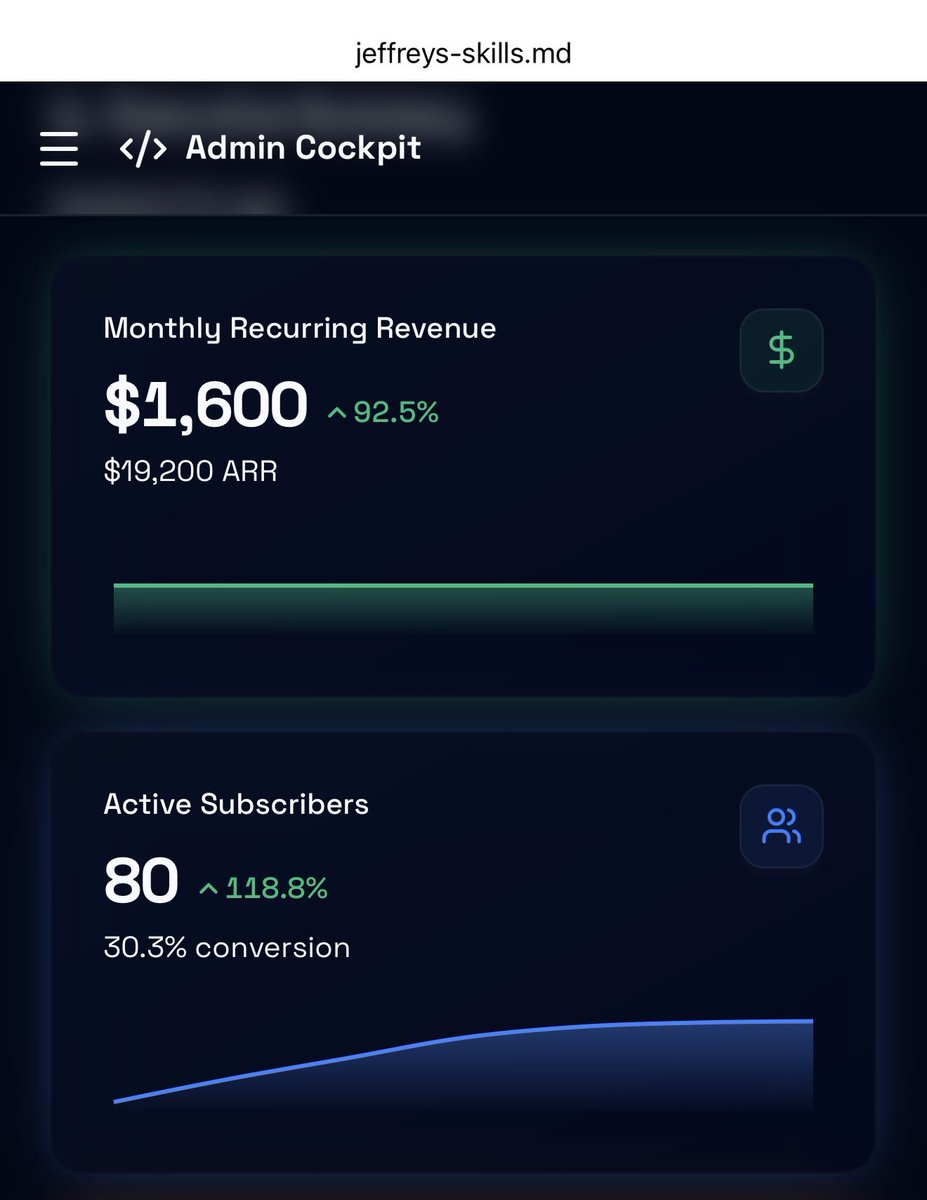
Mr. Levels, move over! There’s a new Solo SaaS Man in town (jk).
But it’s seriously gratifying to see this with zero paid advertising or marketing and < 2 wks. Thanks to everyone who signed up already! I’m working hard to push out a bunch of great new skills every single week.
English
A single prompt made past 1pm and it blocked me til 5pm
420k tokens in memory but seems super restrictive
Thariq@trq212
To manage growing demand for Claude we're adjusting our 5 hour session limits for free/Pro/Max subs during peak hours. Your weekly limits remain unchanged. During weekdays between 5am–11am PT / 1pm–7pm GMT, you'll move through your 5-hour session limits faster than before.
English
@mattpocockuk a full stack team of 5 has been the sweet spot - management covers holiday and smaller tasks where they can
English

Feel like in the AI age, the optimal size for a team of devs on a single decent-sized project is around 3.
1 is untenable. You can't just pause development during their holidays.
2 is OK, but still a lot of bus factor to contend with.
3 is nice and comfortable.
Each day the team manages the queue of tickets for the AFK agent, discusses feature requests, architecture, reviews code, improves feedback loops, shares knowledge.
Probably some devs contribute to multiple teams.
English

Dang I thought $40k for this mo was crazy but I guess I am rookie numbers
$150k #april_goals
shirish@shiri_shh
The Anthropic team is dogfooding Claude Code at insane levels. In the last 52 days, the Claude team dropped 50+ major UPDATES. One employee alone hit $150,000 in a single month on Claude Code 80% of employees use it daily, with power users racking up six-figure bills.
English