
Charles Hasse
3.1K posts


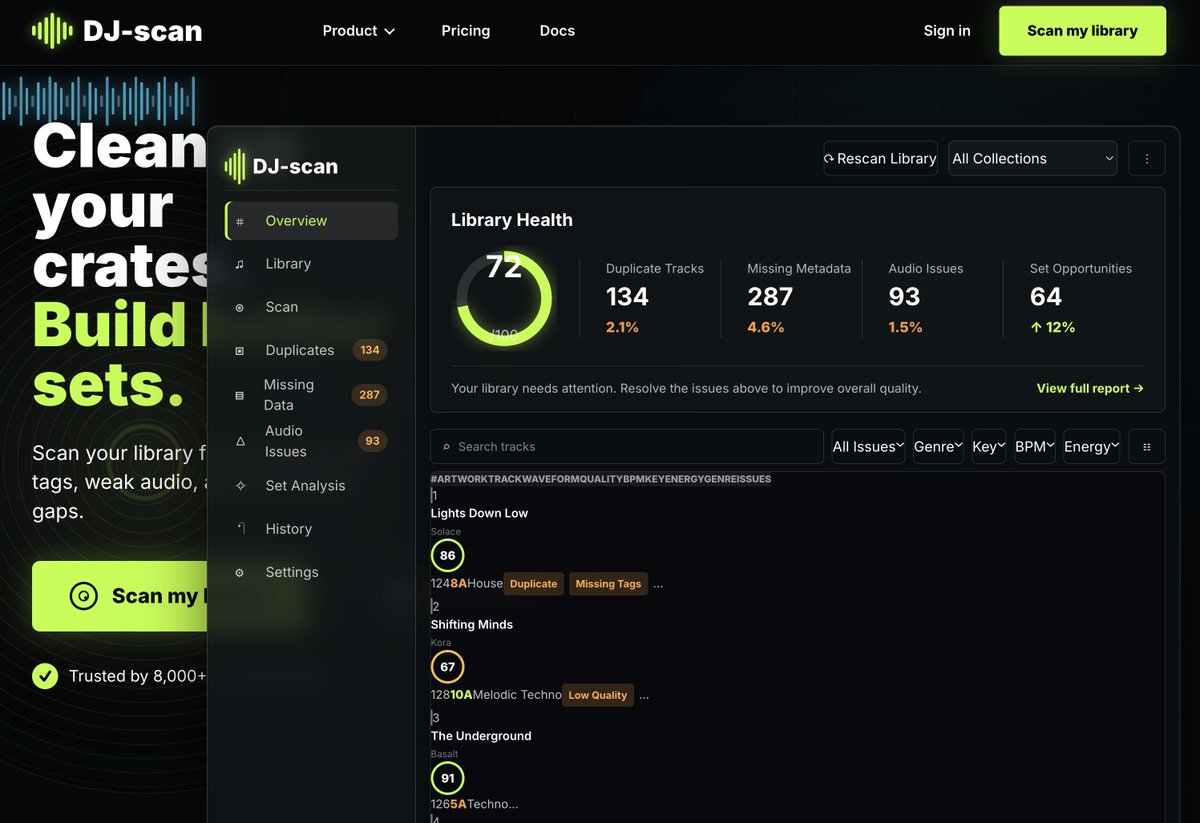
a imagem que o codex gera // o frontend que ele coda
saudades da minha ex (claude code)

Português
@hollycheetosss Usar um dash-move pra quebrar algo no chão pra mim é skill-issue claro.
Português

AVOWED INJOGAVEL PAPO RETO COMO APROVARAM UM JOGO DESSE
Hcheetos 🐉 #007@hollycheetosss
MENU🥹
Português

@AIandDesign If you are using only one session at once, that explain's it. You token usage would probably fit within the 5x.
I have several sessions running, with several agentes on each, working on different tasks. Orchestration is a real token burner.
English

People who constantly run out of Claude tokens:
WTF are you doing?
I have a whole portfolio full of work made with it and I never run out of tokens.
Melvyn • Builder@melvynx
We can all say it... Claude 20x is dead. The previous "feel unlimited usage" doesn't exist anymore. Usage increases quickly and scales really fast... People who discover Claude Code now: you missed a time that will never come back, I think.
English


one of my favorite quality of life features
ClaudeDevs@ClaudeDevs
Claude Code in the terminal will now show recaps when you switch focus away from the session and then come back. This should help you stay more in flow while multi-clauding.
English
@ClaudeDevs Everyone must disable this ASAP. Is a token burner like no other, it will read the whole context every time you back away from the terminal. Ran through 20% of my 5h without a single prompt from my side.
English

Claude Code in the terminal will now show recaps when you switch focus away from the session and then come back.
This should help you stay more in flow while multi-clauding.
English
@lucas_montano Change effort to high, disable recap. Will save a lot of tokens. You just need to understand that 4.7 behaves and interpret different from 4.6. Is now way more literal and don't assume things.
It means now that vague prompts will not work the same as with the 4.6.
English

@byalbuquerquesz @lucas_montano Só pedir ai pra sua LLM criar. FIz aqui e ficou filé. Só abrir o mic que ele já pega, identifica intent, se for anotação, tarefa, lembrete, ele automaticamente cria pra mim, independente se é num meet ou audio do whatsapp.
Se abro meet ele faz com as duas vias e diariza tudo.

Português






With TWO prompts of Opus 4.7 this morning I spent 100% of my 20x Claude plan + 150 USD in credits.
@AnthropicAI fix this
English
@uiux_harshit If you prompt the way you think every section should be, it can create almost the same design easily. I bet you just sent a regular prompt with some base specs. Obviously it will try to simplify as per design.
English


@zachkrall When you use chat, it uses chat harness/workflow/context, when you use code, it behaves with the same tools/harness/workflow/context as if you were using Claude Code CLI for example.
Cowork same thing, has specific tools and prompt injected to work within teams.
English

ok i still dont understand why chat, cowork, code are even separate tabs to begin with
English
English


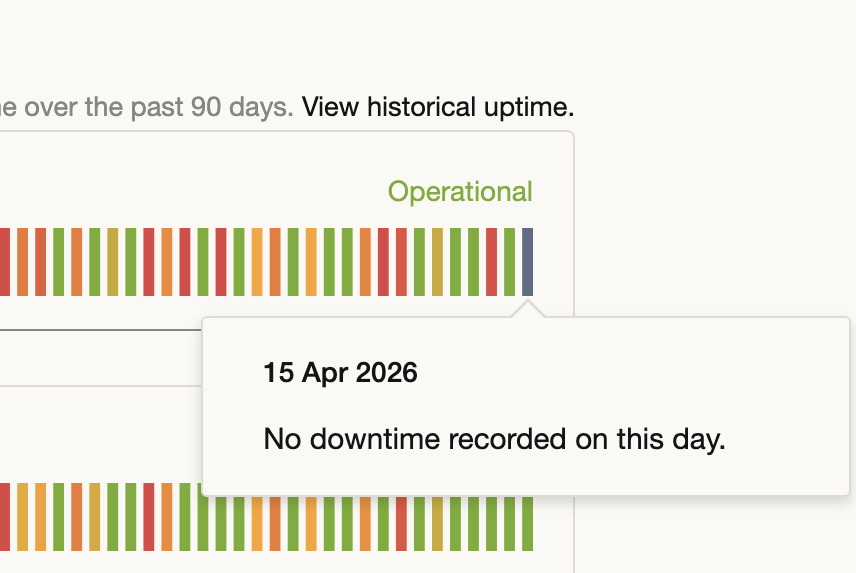
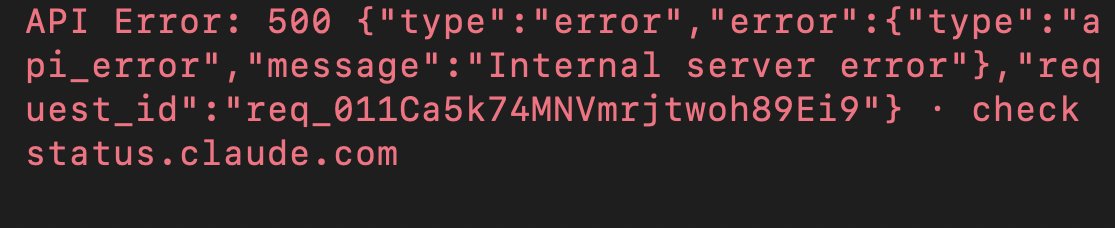
Someone is getting fired today (or not, maybe an Agent will be disabled). How about updating the status page @claudeai @AnthropicAI ?
English
@kipperdev Hoje com mcp da aws não tem mais a velha barreira de complexidade. Muito mais barato você montar sua estrutura lá, com ajuda da sua llm preferida do que pagar o absurdo que a vercel cobra, na minha opinião.
Português

Alguém rodando backend inteiramente na Vercel??
Fomos visitar o time do Cursor em SF, e o pessoal falou que eles têm aplicações rodando 100% na Vercel (back e front)
e tb fomos no escritório da Vercel e eles tão trabalhando bastante pra melhorar a experiência pra backend, principalmente JS.
Aí eu pensei, por que não?
Pô, nossa startup é pequena, temos poucos clientes, e a complexidade extra que a AWS adiciona é inegável (apesar de eu já dominar bem, sempre tem a curva de aprendizado pra pessoas novas)
Enfim, queria ouvir relatos de uso da Vercel no back se alguém tiver
Português
@cathrynlavery @bcherny It defaults to EDIT with approval after a planning session. You need to change back to bypass.
English

Didn't fork it, but used as an inspiration to create my own. (claude did review your git, so there is a lot of "inspired by" code here).
github.com/hassekf/claude…
Paweł Huryn@PawelHuryn
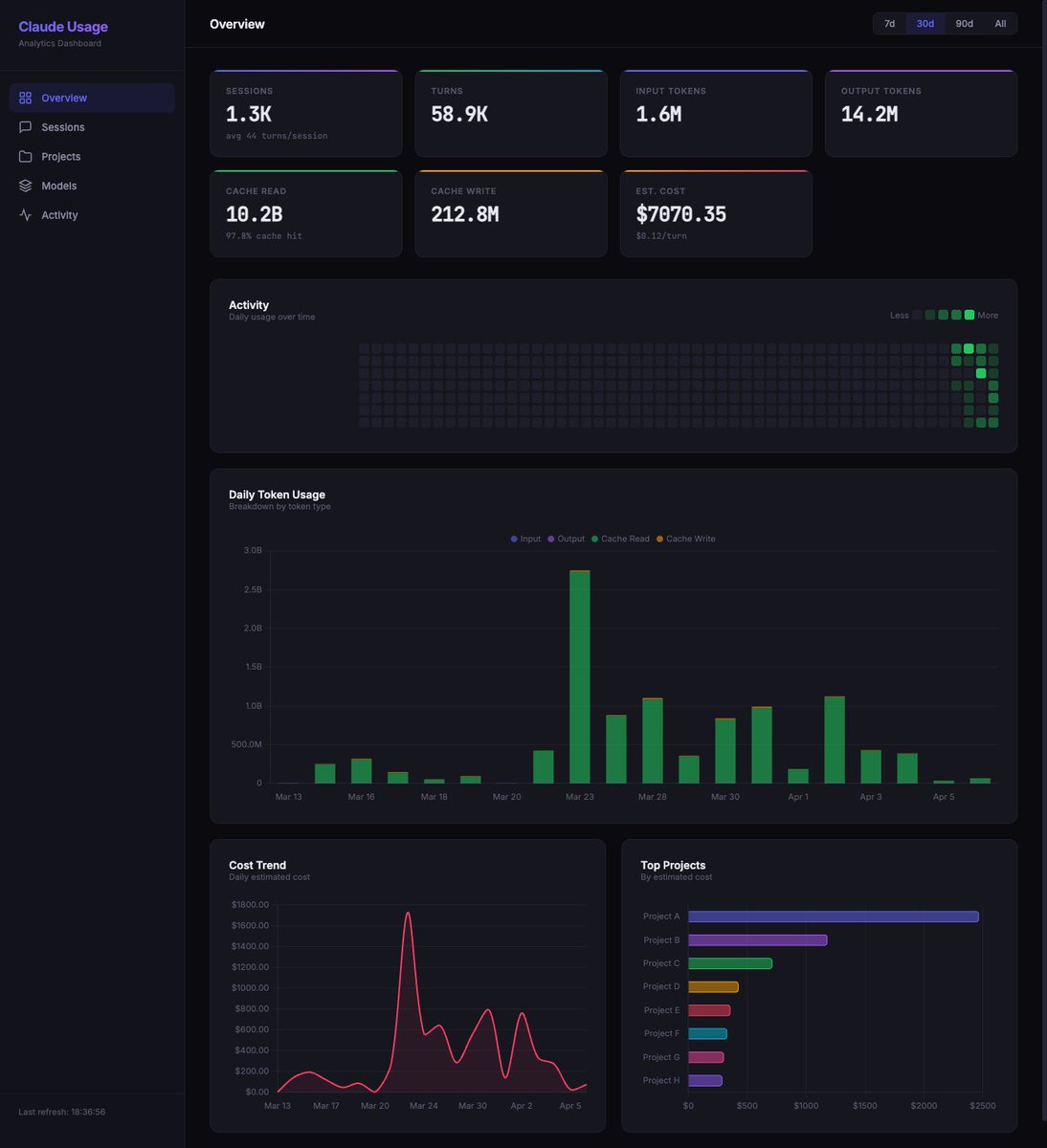
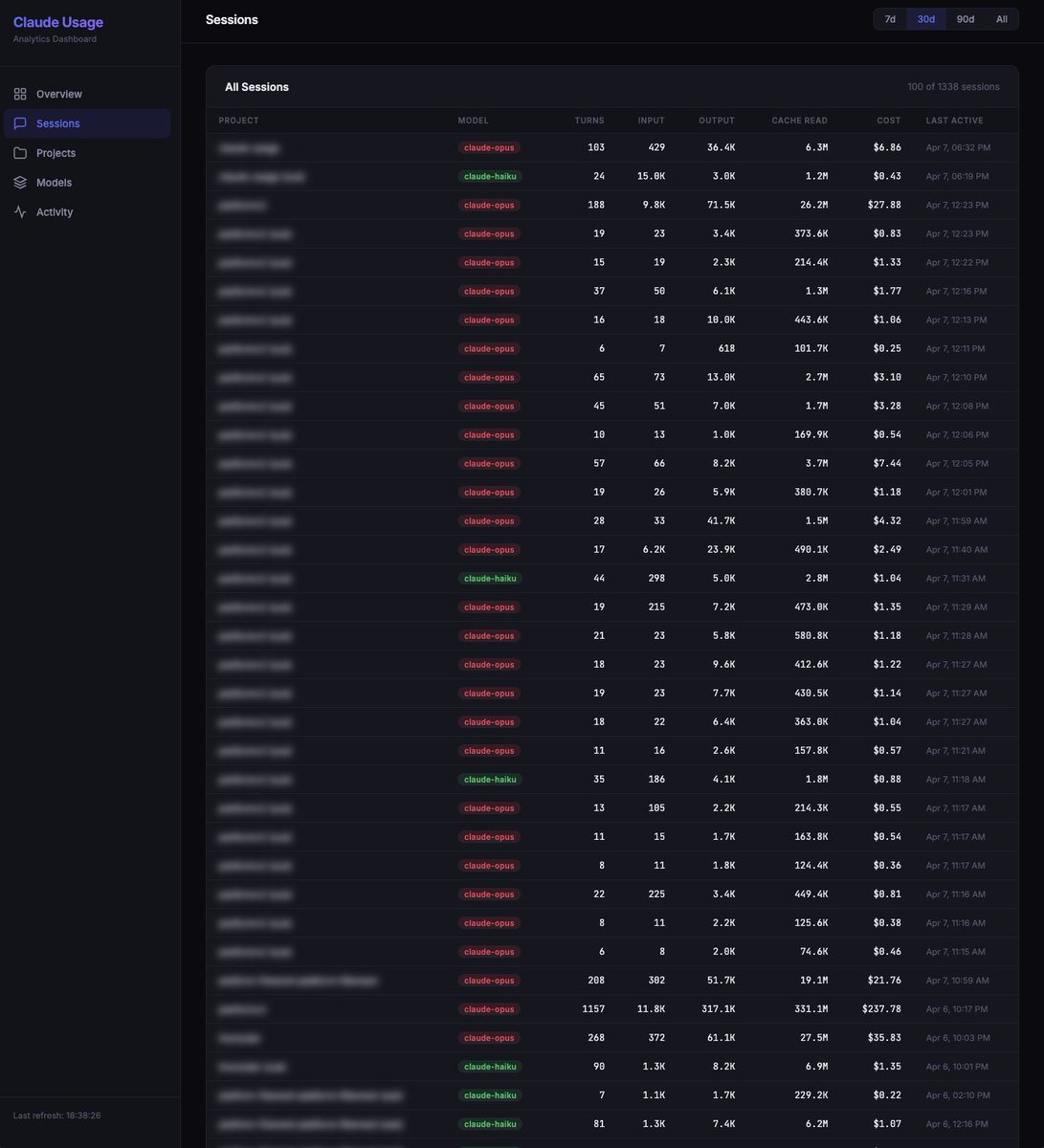
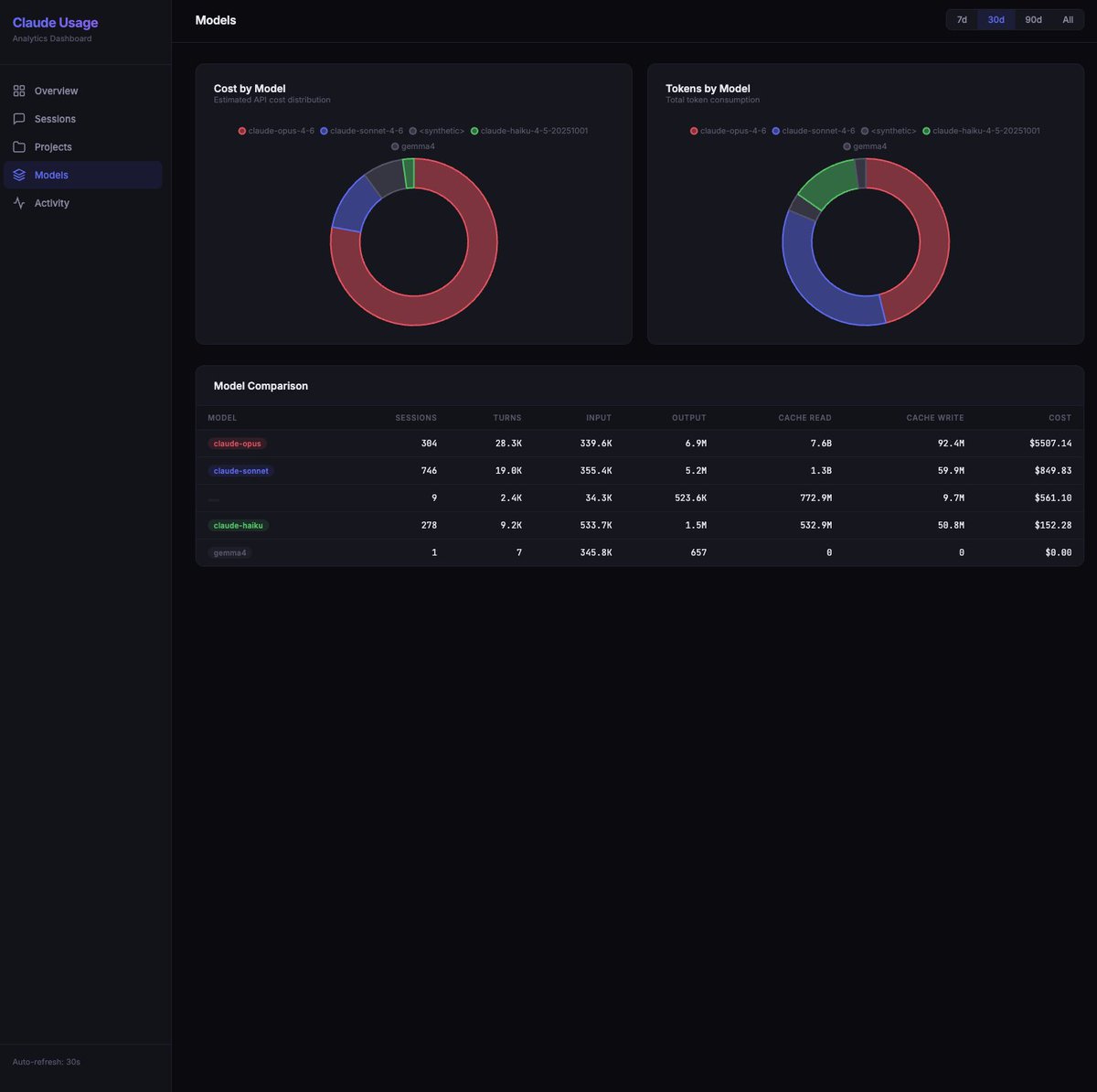
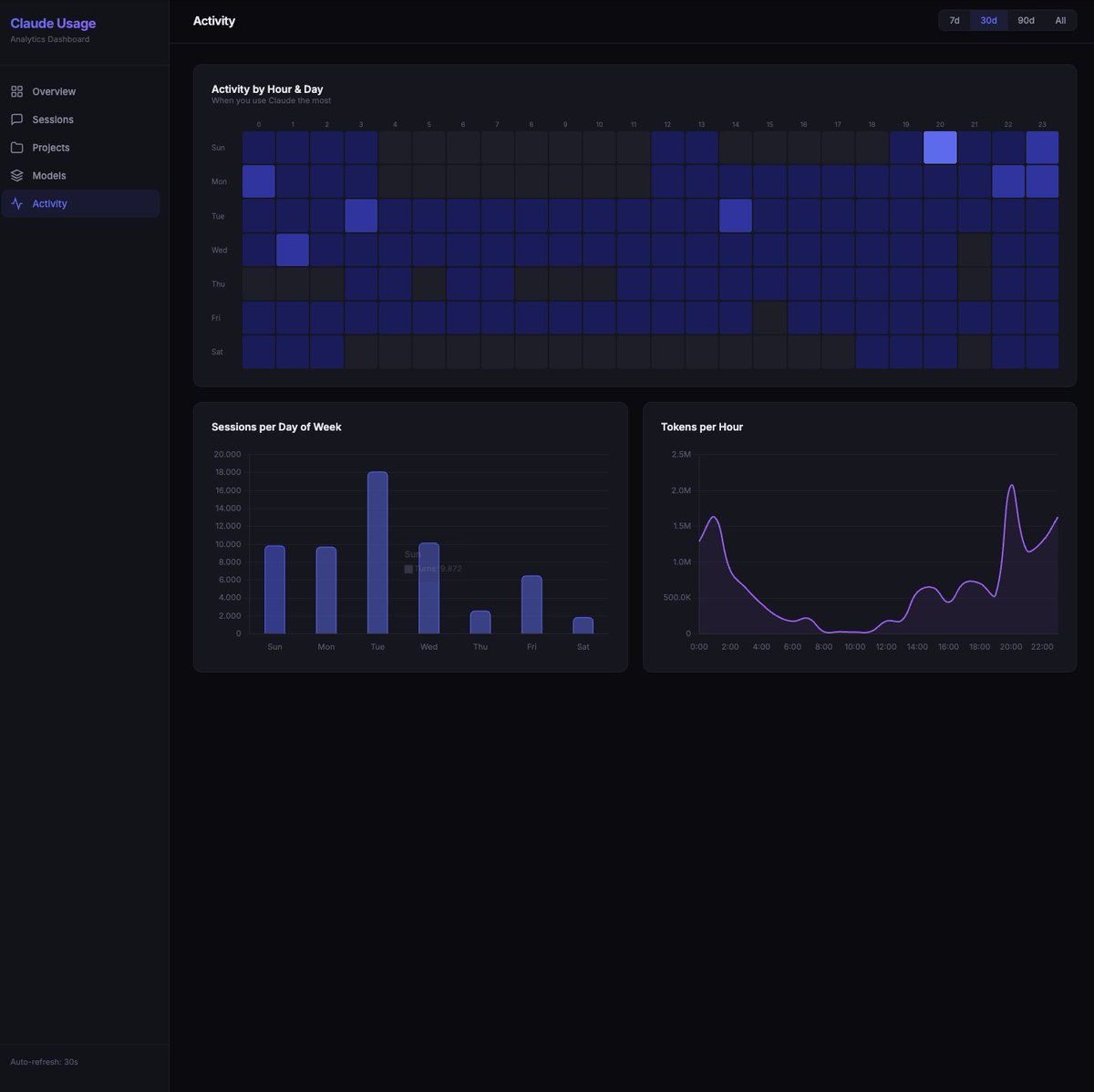
Claude Code doesn't show you how many tokens you're using for subscriptions. No breakdown by model. No breakdown by project. Just a progress bar that says "63% used." So I built a local dashboard that reads the files Claude Code already writes to your machine. Turns out every session, every turn, every token is logged to ~/.claude/projects/ in JSONL files. Input tokens, output tokens, cache reads, cache creation, model name, timestamp. It's all there. You just can't see it. My numbers over the last 30 days: 440 sessions. 18,000 turns. $1,588 in API-equivalent costs. On one day, the cache spiked to 700M tokens - visible cache bug, two days in a row. The dashboard scans those local files, builds a SQLite database, and serves charts on localhost:8080. Filter by model (Opus, Sonnet, Haiku). Filter by time range (7d, 30d, 90d, all time). Cost estimates based on current Anthropic API pricing. Works retroactively. First run processes your entire Claude Code history. Install: git clone github.com/phuryn/claude-… cd claude-usage python3 cli.py dashboard Windows: use python instead of python3. Zero dependencies. Python standard library only. Open source, MIT. Star it. Fork it. Make it your own.
English