Chen Zhu retweetledi

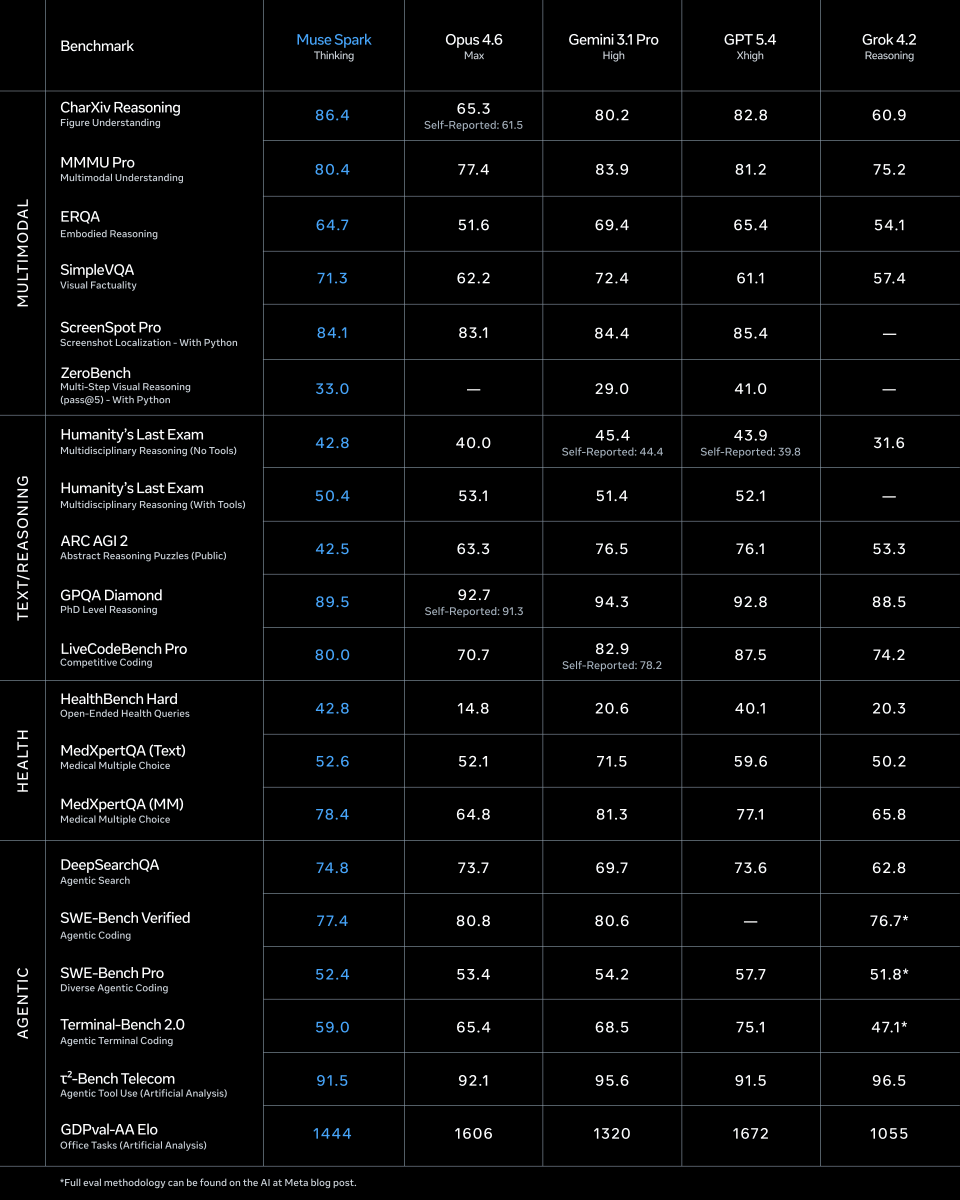
We are releasing our new model muse spark today - our first step towards personal super-intelligence after 9 month great team effort! Please try it out and tell us what you think!
Alexandr Wang@alexandr_wang
1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
English