Sabitlenmiş Tweet

Unlock the Hidden Diversity in Your Language Model.
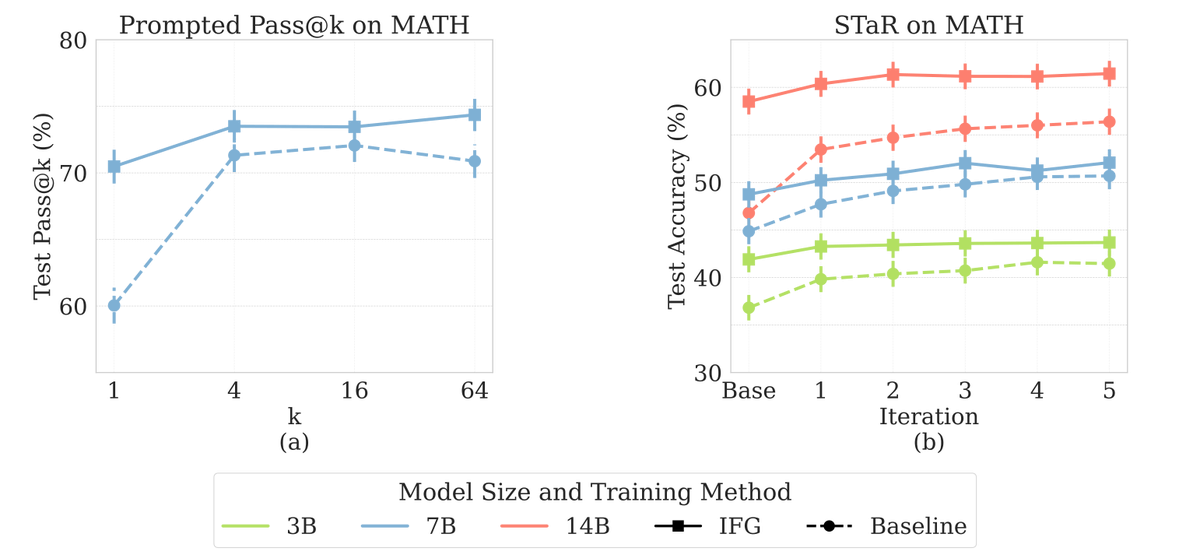
In our new paper, Intent Factored Generation (IFG), we propose an inference time method to increase the diversity of generations from LLMs. IFG leads to improvements in searching for solutions to maths and code problems. (1/6)
Uljad@uljadb99
Unlock real diversity in your LLM! 🚀 LLM outputs can be boring and repetitive. Today, we release Intent Factored Generation (IFG) to: - Sample conceptually diverse outputs💡 - Improve performance on math and code reasoning tasks🤔 - Get more engaging conversational agents 🤖
English