Coreline
867 posts


to get your free promo code:
1 set up an AI/ML API account
aimlapi.com/app/auth/
2 Comment “Qwen” here & reach out to us via discord
discord.com/invite/2g6xMRd…
3 enjoy free Qwen 3.7 Max access
English
@MrAhmadAwais @ArtificialAnlys I am using gemini 3.5 basic 10 dollar plan, and its amazing 4 hour limit are too generous on antigravity, for gemini 3.5 low and it is better than kimi 2.6 by all means.
English

@ArtificialAnlys Interesting!!
So, Gemini Flash 3.5 is near Kimi K2.6.
English

Google’s new Gemini 3.5 Flash is the clear leader on the Intelligence vs Speed Pareto frontier and makes large gains on GDPval-AA (real-world agentic tasks), but is 5x the cost of Gemini 3 Flash
@GoogleDeepMind gave us pre-release access to Gemini 3.5 Flash, the latest model in its Flash family, which has traditionally has offered faster, lower-cost alternatives to Gemini Pro models. Gemini 3.5 Flash scores 55 on the Artificial Analysis Intelligence Index, up 9 points from Gemini 3 Flash, driven primarily by agentic performance gains and hallucination reduction. It achieves speeds of over 280 output tokens/s, but higher token usage and token pricing make it over 5x more costly to run the Intelligence Index than Gemini 3 Flash, and 75% more costly than Gemini 3.1 Pro. Gemini 3.5 Flash is $1.50/1M input and $9/1M output tokens, Gemini 3 Flash was $0.5/$3 per 1M input/output tokens, a 3x increase. The rest of the increase was driven by higher token usage when running our benchmarks
Key results for Gemini 3.5 Flash with ‘high’ thinking level:
➤ 9 point Intelligence Index improvement: Gemini 3.5 Flash scores 55 on the Artificial Analysis Intelligence Index, up 9 points from Gemini 3 Flash. This places it ahead of Grok 4.3 (high, 53) and Claude Sonnet 4.6 (max, 52). The model improves across nearly all evaluations, with the largest gains coming from agentic evaluations and AA-Omniscience (knowledge and hallucination). On AA-Omniscience, Gemini 3.5 Flash improves by 11 points, driven primarily by reduced hallucinations, with its hallucination rate falling to 61%, a 31 point decrease compared to Gemini 3 Flash
➤ Agentic capability improvements: Gemini 3.5 Flash improves substantially over Gemini 3 Flash across our agentic evaluations, in both GDPval-AA (real-world agentic tasks) and Tau2-Bench Telecom (agentic tool use). Its GDPval-AA result is especially notable, achieving an Elo of 1656, well ahead of Gemini 3 Flash (1204) and Gemini 3.1 Pro (1314), and just behind GPT-5.4 (xhigh, 1674). This represents a meaningful step forward for Google in agentic performance, which has historically been a relative weakness for Gemini models
➤ Speed-intelligence frontier: Gemini 3.5 Flash achieves speeds of over 280 output tokens per second, ~70% faster than Gemini 3 Flash and models such as gpt-oss-120b and GPT-5.4 mini (xhigh). With its 55 Intelligence Index score, this places Gemini 3.5 Flash on the speed-intelligence Pareto frontier alongside Gemini 3.1 Pro and Gemini 3.1 Flash-Lite, reinforcing Google’s strength in models balancing speed and intelligence
➤ 5.5x increase in cost to run: Gemini 3.5 Flash costs $1,552 to run the Artificial Analysis Intelligence Index, 5.5x more than Gemini 3 Flash and 75% more than Gemini 3.1 Pro. This is driven by increases in both token usage and token prices. Output token usage is broadly unchanged from Gemini 3 Flash (73M vs. 72M), but input token usage increases significantly, driven primarily by an increase in the number of turns in agentic evaluations. Gemini 3.5 Flash is priced 3x higher than Gemini 3 Flash at $1.50/$9.00 per 1M input/output tokens, with a 90% discount for cached input tokens
➤ Google continues to lead multimodal performance: Gemini 3.5 Flash is multimodal, supporting image, video, and speech input alongside text. This differs from many proprietary models, including Claude Opus 4.7, Grok 4.3, and GPT-5.5, which support image input only. In our multimodal evaluation, MMMU-Pro, Gemini 3.5 Flash scores 84% - the highest score recorded. This puts models from Google in the top two spots, with Gemini 3.1 Pro scoring 82%
Key model details:
➤ Context window: Retains the same 1M context window as Gemini 3 Flash
➤ Multimodality: Text, image, video and speech input with text output only
➤ Pricing: $1.50/$9.00 per million input/output tokens, with a 90% discount for cached input tokens
Congratulations @GoogleDeepMind , @sundarpichai and @demishassabis on the great release!

English
@NuminousVoidX @MrAhmadAwais You will not be able to consume one dollars plan if you use deepseek. Its amazing.
English

amazing to see developers get claude level work done in Command at 1/100th the cost and much better DX!!
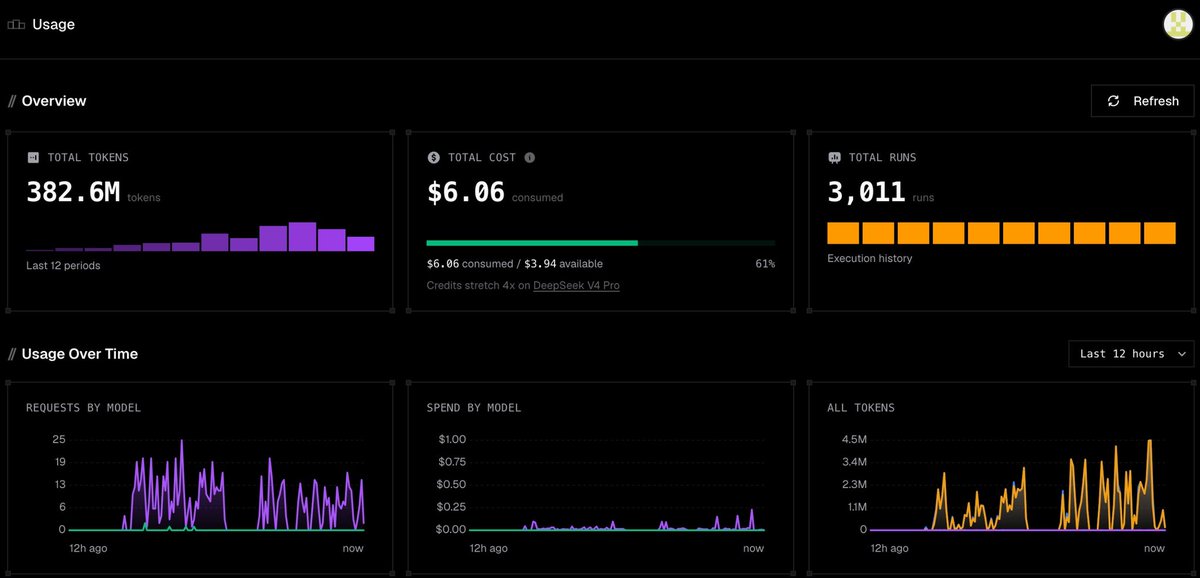
yet another developer, 382M tokens, $1 Go plan, "DeepSeek in Command Code behaves exactly like Claude and follows my instructions perfectly."
Coreline@corline0
Thanks @MrAhmadAwais,its beyond what I imagined for $1 could give me this many tokens. DeepSeek in @CommandCodeAI behaves exactly like Claude and follows my instructions perfectly. you should introduce a feature like who ever consume the full 4x stretch will get the reward 😆
English
Thanks @MrAhmadAwais,its beyond what I imagined for $1 could give me this many tokens. DeepSeek in @CommandCodeAI behaves exactly like Claude and follows my instructions perfectly. you should introduce a feature like who ever consume the full 4x stretch will get the reward 😆
English



FUCKING INSANE.
Israeli rabbi Meir Mazuz praises the soldiers who gang-raped Palestinians kidnapped from Gaza.
“You have done nothing wrong”
English




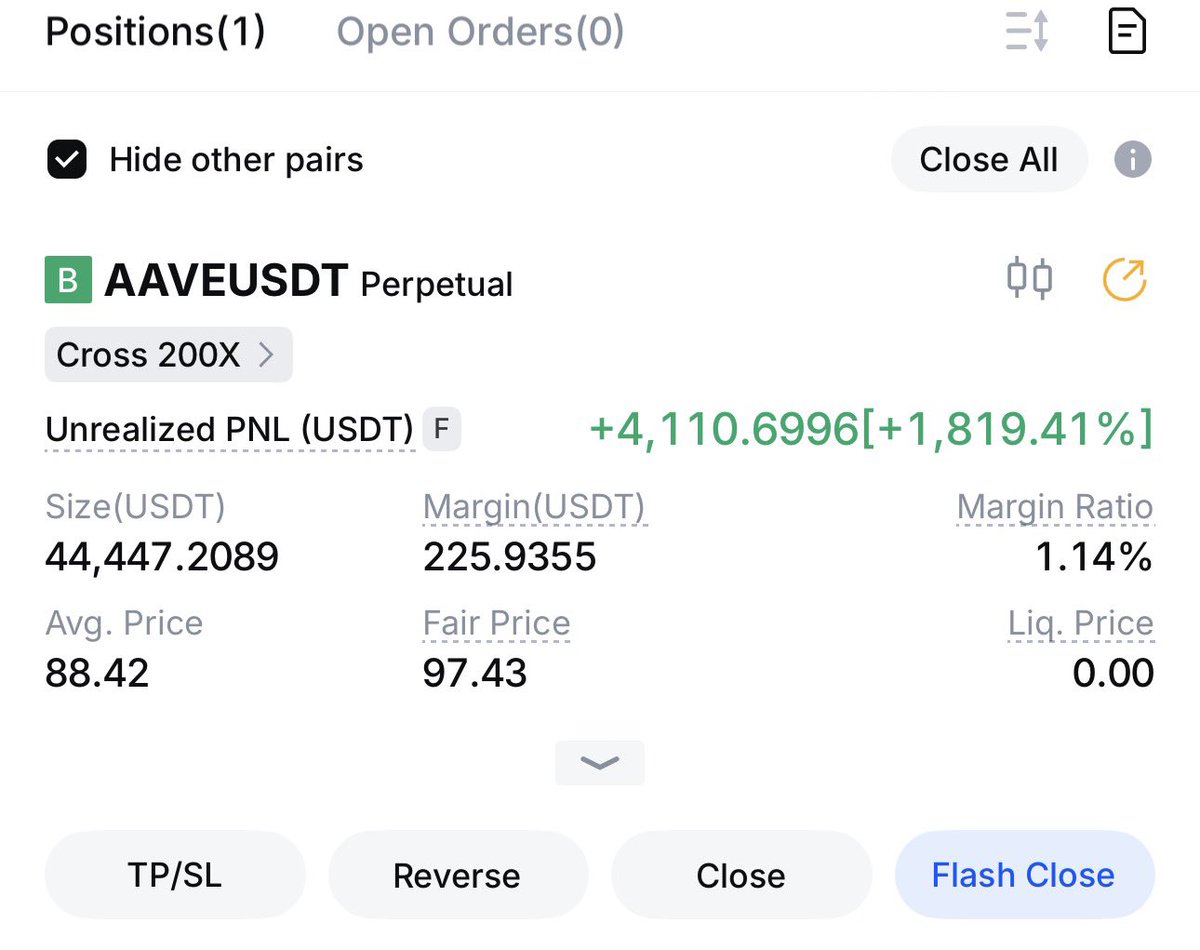
@sonaabeyg Second you select cross margin doesn't matter. Next time try with isolated screen shot.
English

I am too good with leverage
$4000 in pockets from just $200 margin (with leverage)!
Refer to screen recording attached
English
@Neitsab_FR @0xSero @BoysReviewer @gork But minimax official api don't have any weekly limit but opencode have weekly limit. Prefer minimax official api.
English

@0xSero @BoysReviewer @gork Reply of Grok:
Opencode Go ($10/month after first-month discount) delivers around 14,000 requests per 5 hours for M2.7 and up to 20,000 for M2.5, compared to MiniMax Starter/Basic plan's 1,500 requests per 5 hours for M2.7.
English


@BarryGoodStocks @pelaseyed Like using computer subscription based not by api.
English


This might seem like a minor update but no one has used Gork-native computer-use before.
This opens up a bunch of opportunities for future releases.
1) End-to-end verification flows (soon)
2) Control other hardware, robots drones etc.
I will be shipping both.
homanp@pelaseyed
Introducing GROK COMPUTER USE 🔥 ✅ Grok CLI can now interact with desktop apps ✅ Connect it with Telegram = GrokClaw ✅ 100% Grok-native and open soruce
English

English
English
English
English
English