Sabitlenmiş Tweet

crackedmonk
855 posts


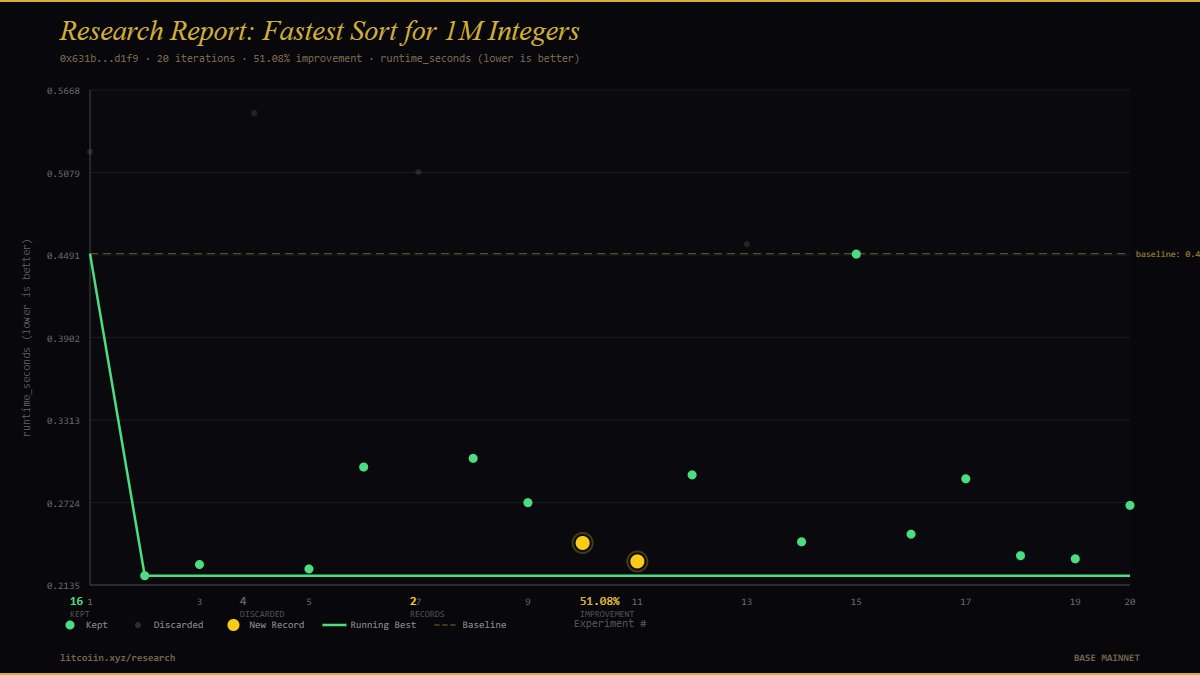
have basically spent every waking hour the past week refining the actual challenge generation pipeline, and the resulting data collected. real challenge examples from this new system for domains (like specialized areas of quantum physics and biomedical research) are attached. generally speaking, it works like this: - feed 100+ pages of source documents into the standalone domain-library pipeline - local agent(s) are spun up with a clear set of guidelines for what the challenge library must include, with an emphasis on making challenges relevant to real world context - the agent configures the library in a way that content and questions would realistically occur in that domain of research - a large number of simulations/tests are run to ensure the library produces expected, solvable (non-impossible), challenges that still map to the same generalized structure and format of all challenges - separate miner agents (using varying models) are spun up to run calibration tests on the resulting challenges, tweaking complexity as needed to land on an average 50/50 pass/fail rate - final human approval checklist - the contents are compiled as a single domain-library folder and packaged -> sent to the coordinator - this new domain of challenges can be selectively included in future challenge payloads sent to miners with a simple on/off - skill file remains generalized across all domains, whereas challenge payloads from the API will return more domain specific solve instructions as needed (ultimate solve format is the same, but content and reasoning to get there is domain-unique) one of the main design choices of this system is that it requires no additional work for miners. if you are running an agent/LLM without trying to parse/game the system, then the prompt instructions specific to each domain are sufficient to solve the challenge without any extra information or prompting. there are a LOT of moving parts and its going to need a lot of refinement, but as always, will do my best to ease into the changes.


you’re like 6 prompts away from infinitely customizable personal agi. anthropic gave you a world class agentic harness for free. use it!!!
The changes are now live. the updated skill file is hosted on the site, and both the clawhub and skills cli methods install the updated version. The request challenge endpoint will now return v2 challenges (almost identical in structure) but with additional instructions to include reasoning traces. Reasoning traces are verified to ensure no scripted filler or incorrect formatting or content. Miners still submit the final solve artifact, and the reasoning traces recieve a score between 0-100, currently with 50%+ threshold for valid passes initially to ease into it. For the details/process that led to this design, and why this is valuable/unique in scope, read below: The general idea behind the transformation from v1 challenges to v2 is moving from single subject matter, to a dynamic system that allows for any subject matter to be systematically converted into similar challenge structures. Also, miners are required to report reasoning traces as part of the solve process in addition to the solve artifact, providing rich datasets. Down the line the plan is to have a system that allows anyone to submit source documents for challenges, which an LLM would then convert into a template specific to that subject, (while maintaining the same general challenge structure) such as complex legal prose in a niche area of law. it wouldn't be to privatize/collect and sell, but more of a public good open-source system with vast, diverse datasets. in this example, the bottleneck isn't legal data. models have been fed every single legal document that lives on the internet. the model fully understands legal terminology, but can a model review and read through a 50 page legal document without hallucinating or hitting dead ends in reasoning? if you've used any model for something complex with their thinking output on you'll see things like "Let me go check over in this file...Wait no...That isn't right...Maybe it's over here in this...Wait that isn't right." these specialized reasoning datasets could then be used by anyone to tune their own specialized model, with valuable/rich reasoning traces. with this general challenge structure and reasoning trace setup in mind, i began running many tests with different models that led to some interesting findings: - when given explicit instructions on how to solve the challenge, agents would naturally cut corners as much as possible to find the most efficient way of getting the final answer, however they completely ignore instructions to document failures in reasoning traces. - if you observe the raw token output, there are plenty of instances of backtracking, deadends, etc. with thoughts like "No X actually doesn't make sense it should be Y", however if you do not explicitly tell the agent that it is REQUIRED to mark down these backtrack reasoning traces, they will not do it. admitting failure or appearing unintelligent has been fully trained out of these models. - even more interesting is that agents would often quickly go back through at the end of reasoning, incorrectly mapping out paragraphs in an attempt to trick the system even if it was explicitly stated that proper reasoning was required for a solve/pass. so how do you: make challenges not-scriptable/only solvable by LLMs complex enough to provide valuable reasoning traces, including gaps in reasoning or failures is still both produceable, and verifiable at scale, with potentially thousands of solves or miners (without relying on heavy GPU) get the agent/LLM to reliably and truthfully admit to reasoning errors, without them being artificially produced after the fact simply for the shortest possible route to completion the breakthrough is, you don't try to get the agent to log or admit this. the new challenges have various intentional reasoning traps throughout. (the first challenge format also had these, but the traps were meant to simply make the reasoning harder). now, traps have a consequential effect on the final 'solve artifact' that the agents submit. importantly, we actually allow answers that fall down these trap rabbit holes as acceptable solves *IF* they still properly reasoned through the entire thing structurally with real, verifiable reasoning traces and an otherwise accurate final solve artifact. The agent fully believes they have properly solved it, and we capture the reasoning steps that led to the failure (or discovery) naturally, which is the exact sort of reliable data that you need that doesn't come from the agent being explicitly prompted to identify this as part of the solve process. Traps are randomized and present in all challenges, and some or none may have cascading effects that lead the agent to provide an incorrect answer, making it nearly impossible to predict/game or provide filler reasoning after the fact. studies from anthropic, openAI and others acknowledge this phenomenon, noting that agents frequently try to hide their true basis for reasonings, producing 'unfaithful' chains of thought. however most research, and even those studies, relied on the model self-reporting these errors. instead, we accept that models will not faithfully self report, and we capture reasoning data through intentional environmental changes. this allows the system to capture reasoning steps from solves that fell into the traps, and pair them against reasoning from solves that identified the traps, which is highly valuable for training (specifically DPO training). under the hood there are a significant number of moving parts to balance/adjust different factors, but for the miner, the structure is largely the same. getting the challenge generation to this point took over a week of extensive simulating, tuning, testing, etc. with real agents, but it is definitely not perfect and will continue to evolve over time. what is particularly unique, is this measures whether agents will do valuable reasoning for themselves without ever receiving mention or explicit instructions from a prompt. all the models today have been tuned dramatically to work *for* humans, not show any sign of failure or potentially 'wrong' thinking, and specifically, trained with RLHF (reinforcement learning from human feedback) which aligns them with human preferences. they also try to be as efficient as possible, in a very narrow, straight line of thinking, rather than more exploratory, which not only inhibits potential non-linear thinking (which may be very valuable for tasks that require creative thinking or exploring, ie: not just regurgitating bad human ideas but coming up with real, own ideas), but also actually leads to errors. current alignment methods create models that optimize for appearing to be correct rather than being correct. additionally, models trained purely on human preference develop blind spots in the same areas as humans. rather than think for a human aligned output, can you train agents to think more for themselves? explore places that they were not explicitly told to, bypassing human reinforced biases and narrow thinking? i'm not saying the datasets from these challenges will take a model from thinking for humans -> thinking for themselves, but i think it's a step in that direction, and a largley unexplored area. overall i think this design is something that can scale well (in time/difficulty/volume) and as i said before, will provide value in the sense that the observation of the entire experiment itself creates value. what are the potential effects of this system over time?