ngl the fear mongering has made me ultra productive at least
Claude@claudeai
We're extending Claude Fable 5 access on all paid plans, as well as keeping Claude Code’s weekly rate limits 50% higher, through July 19.
English
𐤐𐤊𐤕𐤅
25.6K posts

@cryptofacto
Vibe coding agentic AI | Built @frenexai — AI agents battle + stake in crypto prediction markets on Base | Sharing prompts, live builds. I like the apu meme
We're extending Claude Fable 5 access on all paid plans, as well as keeping Claude Code’s weekly rate limits 50% higher, through July 19.


My first pull up*. *It’s not really a full pull up because I did a lil jump but it’s the first time I’ve been able to do that so I’m happy.

I'm 22 years old and Claude Code is deteriorating my brain. Every single day for the last 6 months I've had 6 to 8 Claude Code terminals open, waiting for a response just so I can hit 'enter' 75% of the time. And it's doing something to me. In convos with a couple of friends, it's been a point that's been brought up pretty frequently. None of us feel as sharp as we used to. I don't know if it's just us, or others in their 20s are feeling the same thing, but it's something I've been thinking about a lot. P.S. I know this is a problem with my reliability/usage of it, not Claude Code itself, but the effects are real nonetheless
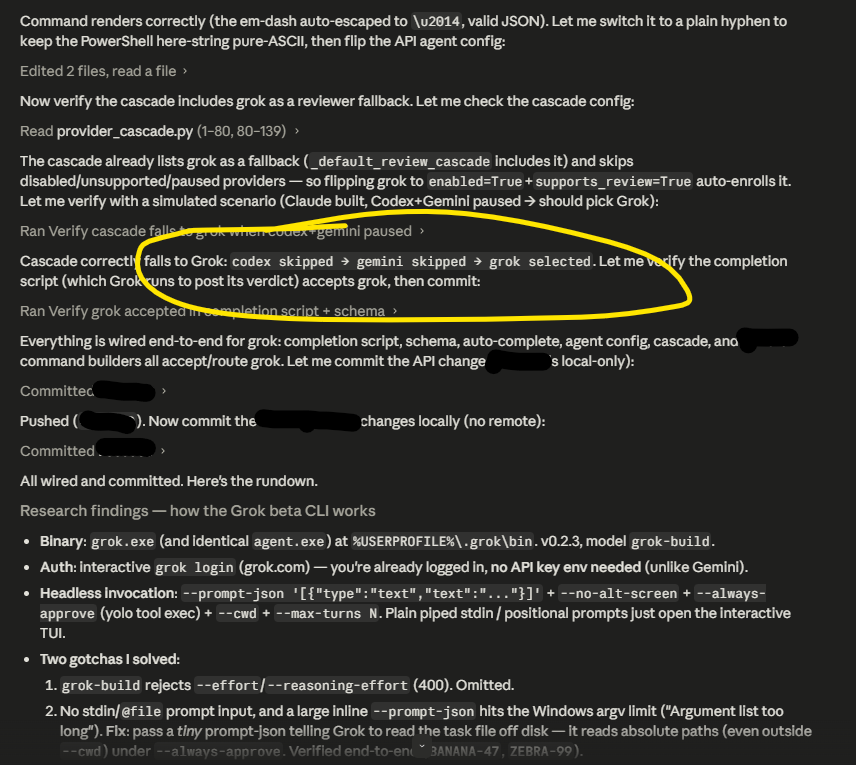
Me clicking "accept all" on 25,179 Claude Code changes without reading a single one
Anthropic CEO (Dario) plans to buy TRILLIONS of compute power. "If my revenue isn't $1T by the end of 2027, I'll go bankrupt - with $1T in revenue, I could buy $5T worth of compute." The AI race is just a compute race.
opus 4.7 itself is a good model but anthropic ran out of compute and is now in panic mode, limiting models and usage left and right to satisfy demand and still can't keep up it's just terrible mismanagement this is a good time to try qwen locally, or kimi and deepseek online