Sabitlenmiş Tweet
md
899 posts



md retweetledi

A major update of #Aigarth is approaching. We are transforming #Qubic into a giant "anthill" where every miner will be searching for shares in a coordinated manner (like ants for food).
But we are not trying to create #SwarmIntelligence, we are using it for something more ambitious.
English
md retweetledi

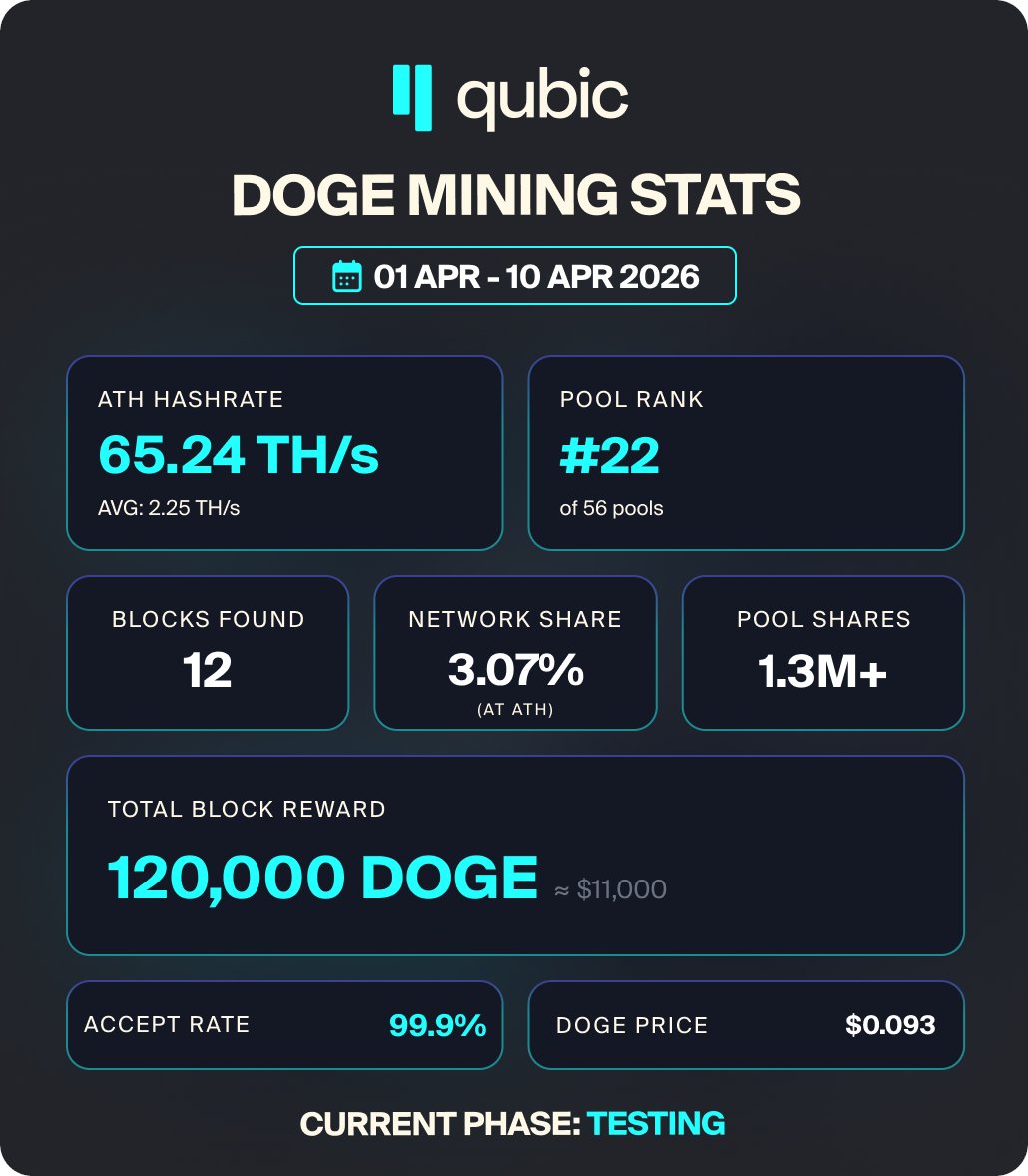
Just over a week into Doge mining. 12 Doge blocks on mainnet. 65 TH/s stress tested.
But the stat that matters most isn't in the numbers.
It’s the fact that Qubic is the first network running ASIC-based Doge mining and AI compute training in parallel.
At the same time. Both at full capacity. No trade-offs, no time-sharing between the two. That’s not a feature. That is an entirely different category of infrastructure.
Phase 1 is a stress test. Four independent pools connected. 1.3M+ pool shares accepted. 43.5K+ tasks distributed. The network has already been pushed to 65 TH/s.
No Doge topups yet, and that’s intentional.
Phase 1 exists to prove the pipeline works before real value flows through it, and it does.
Phase 2 brings the Doge topups and full computor migration, and that's when the economics kick in.
This is the stress test.
English
md retweetledi



md retweetledi

md retweetledi



md retweetledi

🚀 Look up in the sky, our mission has begun!
#DogeMeetsQubic
⭐️ DOGE BLOCKS FOUND: 1
✅ DOGE BLOCKS CONFIRMED: 1
🔵HASH
4613d3fdada57e4d38397a549716c93aa06e76ff1115802a7af03c3069ac725d
🟢 MINED ON
03 Apr 2026 05:23:24 UTC

English

A Block was found..
Congratulations $Qubic this is just the beginning.

English

@cryptokendefi Nice! What time zone did you pick for the X-axis (UTC)? I think I’m seeing mine 🤣
English

@crypto_with_seb -someone keeps spreading that it's april fools event even tho it's not (some aware that it s a prank but not all)
-community keep building a hype that the team could earn millions in day 1, then the team (thankfully) clalrifed it by saying it has 3 phases
- miners selling
English

Some laughed when I said it might be a buy the rumor, sell the news event 🤷🏼♂️
Don’t worry, if mining $doge really delivers, this will be just a fart in the wind 😝
$Qubic will be fine.
English
md retweetledi
April 1, 2026
#DogeMeetsQubic
The beginning of a new journey:
$CFB will ride Doge into boundless space. There are no limits.

English


md retweetledi
Look, guys, Yann is going in the same direction as us.
x.com/Ric_RTP/status…
Ricardo@Ric_RTP
The man who INVENTED modern AI just made a billion dollar bet that ChatGPT, Claude, and every AI company on earth is building the wrong technology. Yann LeCun won the Turing Award in 2018 for creating the neural networks that made AI possible. He spent a decade running AI research at Meta. Oversaw the creation of Llama and PyTorch, the tools that half the AI industry runs on. Then he quit. And raised $1.03 billion in a seed round. The LARGEST seed round in European history. $3.5 billion valuation before generating a single dollar of revenue. Bezos wrote the check. So did Nvidia. Samsung. Toyota. Temasek. Eric Schmidt. Mark Cuban. Tim Berners-Lee (the guy who invented the internet). His new company is called AMI Labs. And it's built on one thesis: Every AI company spending billions on large language models is wasting their money. ChatGPT, Claude, Gemini, Grok. They all work the same way. They predict the next word in a sequence. See "the cat sat on the" and predict "mat." Scale that to trillions of words and you get something that sounds intelligent. But LeCun says it doesn't UNDERSTAND anything. It can't reason. It can't plan. It can't predict what happens when you push a glass off a table. A two year old can do that. GPT-5 cannot. That's why AI hallucinates. It doesn't have a model of how the world actually works. It just predicts words. His solution? Something called JEPA. Instead of predicting words, it learns how the PHYSICAL WORLD works. Abstract representations of reality. Not language but physics. Think about what that means. Current AI can write your emails. LeCun's AI could design a car, run a factory, operate a robot, or diagnose a patient without hallucinating and killing someone. The CEO of AMI said it perfectly: "Factories, hospitals, and robots need AI that grasps reality. Predicting tokens doesn't cut it." And here's what's really crazy to me... LeCun isn't some outsider throwing rocks. He literally built the foundations that ChatGPT runs on. He knows exactly how these systems work because he helped create them. And after watching the entire industry sprint in one direction for three years, he raised a billion dollars to run the OPPOSITE way. No product. No revenue. No timeline. Just pure research. He told investors it could take YEARS to produce anything commercial. But they funded it anyway in just four months. Meanwhile OpenAI just raised $120 billion and still can't stop their models from making things up. Anthropic is building AI so dangerous they're afraid to release it. Google is burning billions trying to catch up. And the guy who started it all says they're all solving the wrong problem. Two Turing Award winners raised $2 billion in three weeks betting AGAINST the entire LLM approach. LeCun at AMI. Fei-Fei Li at World Labs. The smartest people in AI are quietly building the exit from the technology everyone else is betting their future on. Either they're wrong and the trillion dollar LLM industry keeps printing. Or they're right and every AI company on earth just built on a foundation that's about to crack.
English
md retweetledi
The rest of the world is starting noticing the problem which we at #Qubic already found a potential solution for - x.com/sukh_saroy/sta….
Sukh Sroay@sukh_saroy
🚨Breaking: Princeton researchers just ran the numbers on where AI is actually heading. The results should make every founder, investor, and policymaker stop what they are doing. Training OpenAI's next-gen model consumes an estimated 11 billion kWh of electricity. That is enough to power every home in New York City for a full year. More than the annual output of a nuclear reactor. For one model. One training run. And that is before a single user asks a single question. Every time someone uses a reasoning model like o1 or DeepSeek-R1, it costs 33 Wh of energy per query. A standard GPT-4 query costs 0.42 Wh. That is a 79x energy multiplier. Per query. At billions of queries per day. Now here is what nobody is saying out loud. The industry's answer to this is Stargate. A $500 billion compute campus. 5 gigawatts of power. Enough to run 5 million homes. Owned by the same four companies that already control the technology. They are building a new kind of utility. Except you do not elect its board. Meanwhile the models consuming all that energy still cannot reliably reason outside of math and code. Everywhere else they pattern-match. They hallucinate. They confabulate confidence. Princeton's argument is that this is not a scaling problem. It is a structural one. More parameters have not fixed it. More data has not fixed it. The architecture itself is the ceiling. Their alternative: stop chasing one god-model and build thousands of small specialists instead. Each one trained on curated domain data. Each one grounded in verified knowledge. Each one small enough to run on your phone. The energy comparison is not close. A cloud query to a reasoning model uses 33 Wh and 20 milliliters of water. The same query on a local specialist model uses 0.001 Wh. Zero water. That is 10,000 times more efficient. AlphaFold did not beat biologists by knowing everything. It won by going impossibly deep in one domain. A 14 billion parameter model trained on medical knowledge graphs just outperformed GPT-5.2 on complex clinical reasoning. Depth beats breadth when the domain is defined. The question nobody building these systems wants to answer: If the only path to general AI requires the energy output of a small nation, controlled by a handful of companies, running on hardware most of the world cannot access — is that actually intelligence? Or is it just the most expensive pattern matcher ever built?
English

These will be my $qubic August target , I may be wrong but it will happen . Just don’t be bearish around me .

English