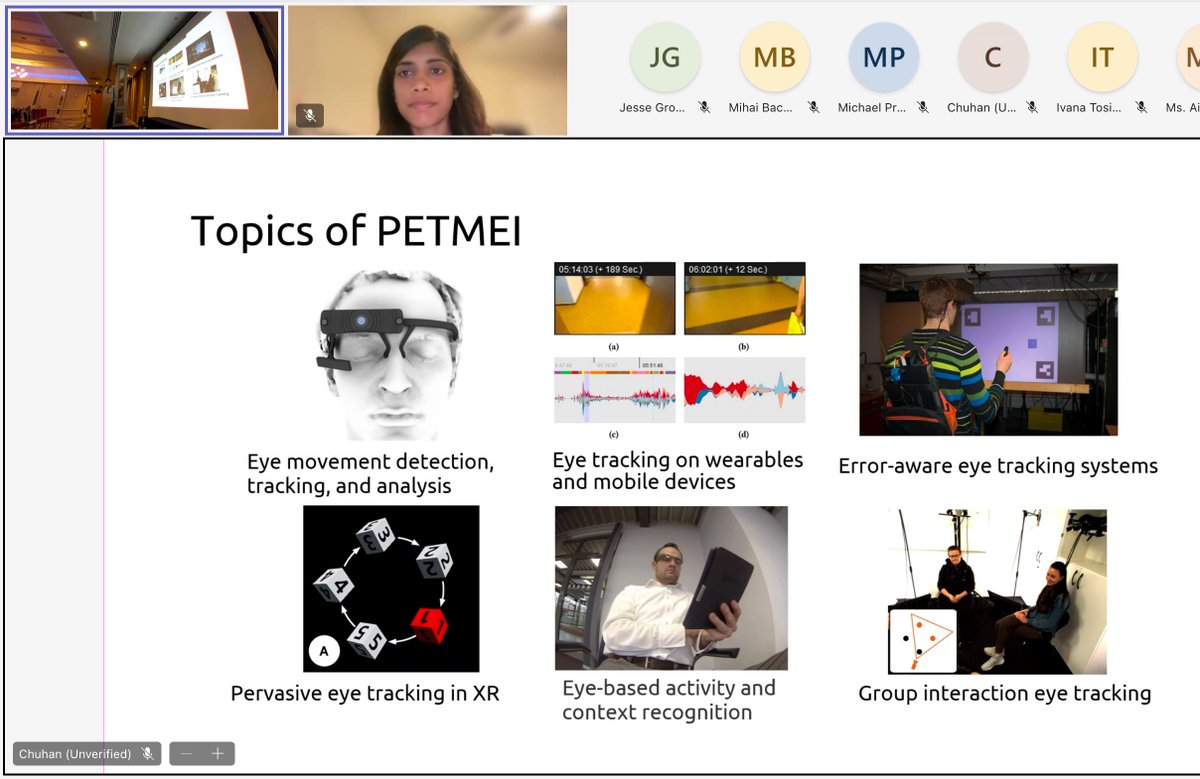
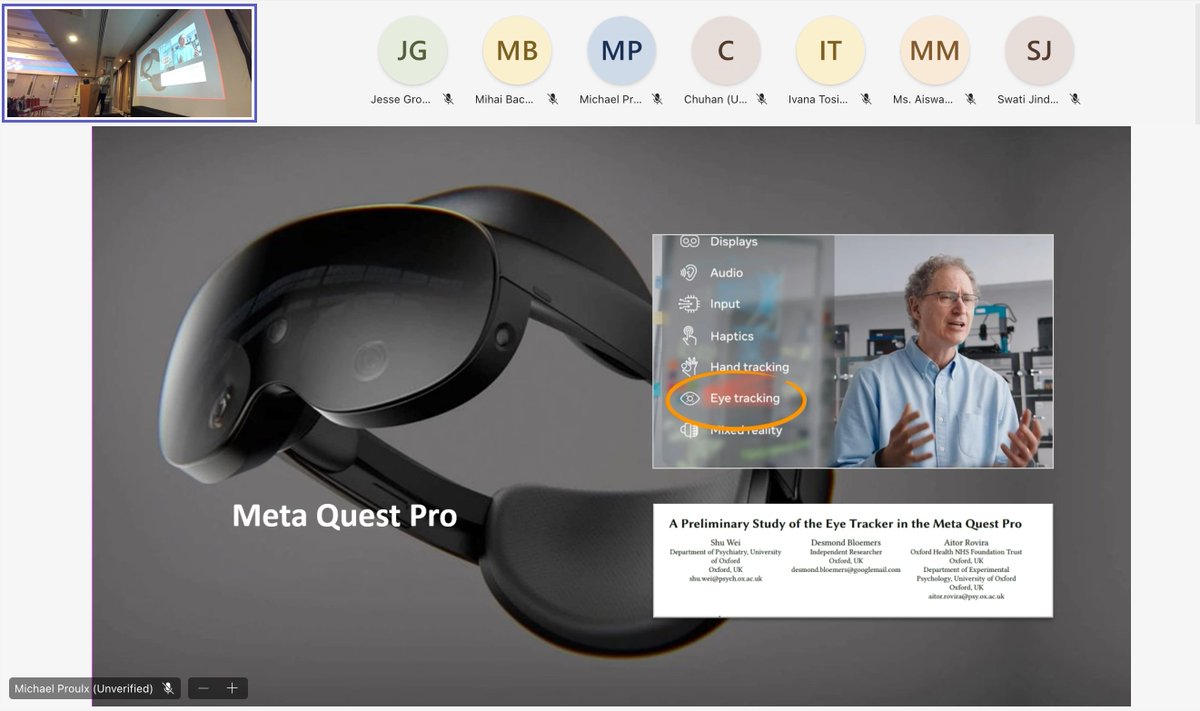
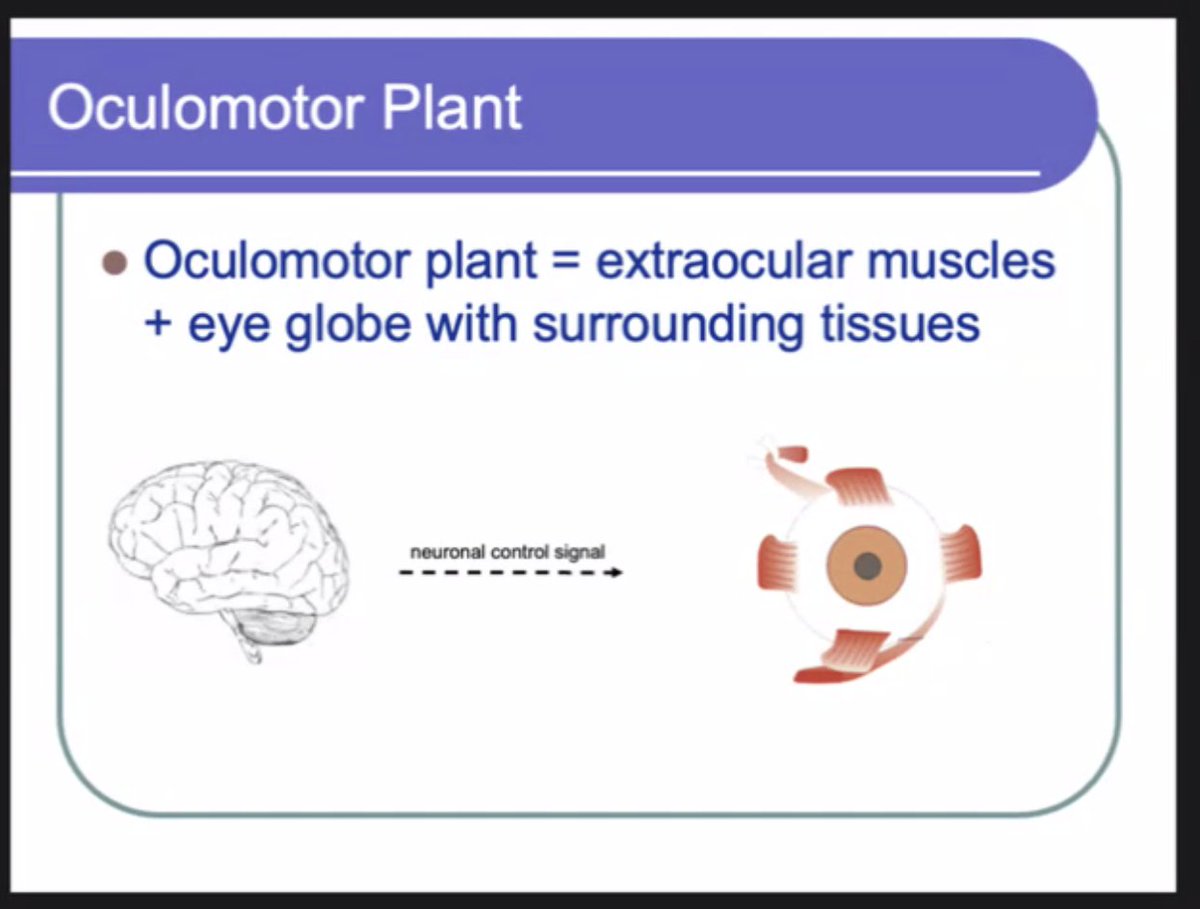
Sabitlenmiş Tweet

🏖️ Headed to St. Pete Beach for VSS!
Presenting new work Monday morning with Phil Guan, Ian Erkelens & Oliver Cossairt @RealityLabs.
Come say hi!
📄 Abstract: visionsciences.org/presentation/?…
🔬 More from Meta Reality Labs:
visionsciences.org/presentation/?…
visionsciences.org/presentation/?…
#VSS2025

English