Cuong Le
120 posts


Cuong Le
@cuongleqq
Engineering leader | Writing about high-performance Rust, Go, and database internals
Katılım Eylül 2017
139 Takip Edilen236 Takipçiler
Cool video. Postgres handles large scans differently -- and I find this one equally clever.
Its shared_buffers cache uses clock-sweep instead of an LRU list. Each buffer slot has a usage_count. When Postgres needs a victim, it sweeps through slots until it
finds one:
• pinned: skip
• usage_count > 0: decrement and skip
• usage_count == 0 and unpinned: victim found
For large scans (table blocks > 1/4 of shared_buffers slots), Postgres allocates a small ring buffer -- just 256KB, roughly 32 slots for 8KB pages. The scan fills
victims into this ring, then cycles back to reuse them. If a buffer in the ring has become hot (pinned or usage_count > 1), clock-sweep finds a replacement from the main pool instead.
Net effect: a full table scan mostly churns through a tiny ring, typically around 256KB, instead of blowing out the whole shared_buffers cache. Simple idea, surprisingly effective.
Arpit Bhayani@arpit_bhayani
Table pages are cached, and this is how databases get a performance boost. But, a single full table scan can destroy such cache because, but here's how MySQL cleverly prevents this... When a full table scan happens, it can flush out all valuable cached pages and replace them with pages that are often never needed again. Given that every single page that is accessed is put into the cache. This 'cache pollution' forces subsequent queries to hit slow disk storage. MySQL solves this with the particularly simple yet clever midpoint insertion strategy, and I have explained this approach in my video. Give it a watch. Hope this helps.
English
@real_redp Fair point. I don't.
People have always submitted patches they don't fully understand (but that's also how they learn the project). AI just makes it much easier to do that at scale. But it removes the learning part, and shifts more of the cost onto reviewers.
English

@cuongleqq why do you think that they understand non-ai generated patches?
English
Something is seriously wrong with how people contribute to open source these days.
People submit AI-generated code they clearly don't understand. When reviewers comment, they feed it back to the AI and submit again. The loop never ends.
Low-effort PR requires extremely high effort to review. That math is never fair.
You think this is how you build a reputation in open source? No, no, and no. You're just burning out maintainers.
---
Use AI to understand the codebase instead. Ask it to explain things. Build your own judgment. It's ok to use AI as a tool for coding, but make sure you filter out any AI slop before submitting.
You gain the skills. You gain the reputation. The project actually benefits.
Is it that hard?
English
If you're using Go for years and feel stuck at intermediate level, I know the feeling. It's not you, it's your project.
CRUD + business logic + REST APIs - no matter how big the codebase, this stack won't teach you advanced Go.
But these projects will:
• VictoriaMetrics / VictoriaLogs (custom storage engine, block compression, zero-alloc hot paths)
• etcd (Raft consensus, WAL durability, election timeouts)
• containerd (OCI runtime stack, cgroups, plugin architecture)
• Prometheus (TSDB, memory-mapped chunks, query engine)
There are many more. Pick one, read the code, send a PR. These projects can't afford slow code, so you'll learn escape analysis, zero-alloc patterns, and real concurrency whether you plan to or not.
English
Cuong Le retweetledi

@valyala @brankopetric00 That’s such a great idea. Why didn’t I think of this sooner? 🙄
English

@brankopetric00 I prefer writing a Makefile rule, which can be debugged locally, and then calling it as a one-liner at GitHub Actions. This saves a lot of time on debugging and maintenance.
English

Contributing to Rust has been a dream of mine for a long time. Last December, I finally did it. A small but real contribution to Rust Clippy. Here's what I learned that no tutorial will teach you.
1. "It works" ≠ "it belongs here"
My code had zero logic errors from the first submission. Tests passed. The lint fired correctly.
It still took multiple review rounds before it was accepted.
Each round, the reviewer flagged something I hadn't considered. A different API, a different factoring, a different order of checks. None were correctness issues. All were belonging issues.
Mature codebases have a shape. A vocabulary. Conventions no doc can fully capture. And when that codebase operates on AST and HIR, the learning curve is steeper than most.
Getting your code to work is step one. Getting it to fit is step two. Only the first is obvious to newcomers.
2. Performance is a first-class design constraint
I spent years building web and backend systems where readability almost always beats micro-optimization.
Clippy changed that.
The reviewer pushed back on how I structured my checks. His version was slightly harder to read, but it was faster. I had optimized for clarity. He optimized for performance. Both were valid, but only one was right for Clippy. The reasoning: this code runs on every file, every build, for every Rust developer in the world. Nanoseconds x millions of daily builds = something real.
Readability-first is a fine default. But in performance-critical code like compilers, runtimes, and toolchains, scale flips the equation. Know which world you're writing for.
3. Don't let ego get in the way of the reviewer
I was surprised by how many specific changes were requested. It felt strict at first.
Then I paused and thought about it. Every request was reasonable.
The reviewer has lived with this codebase. He understands every design decision and genuinely cares about keeping it in good shape. His knowledge was the most valuable resource I had access to, and I almost let pride get in the way of using it.
In a review from someone who knows the codebase far better than you: every comment is a gift. Receive it that way.
The flip side: if you're ever reviewing a first contribution, that same dynamic works in reverse. Your patience, or lack of it, is the whole experience for them.
4. A good test suite makes new contributors brave
My biggest fear as a first-timer: breaking something silently.
Clippy's golden-file tests killed that fear. The exact expected output is checked in alongside the code. Shift a diagnostic message even slightly, the test fails and shows you exactly what changed. Clippy even runs its own lints on itself.
Knowing the safety net was that solid made me willing to experiment instead of playing it safe.
A comprehensive test suite isn't just quality assurance. For anyone contributing to an open source project, it's a confidence multiplier. The difference between experimenting freely and playing it safe.
---
That was my first time contributing to a real, large-scale open source project. Small contribution. Big lessons. More to come as I go deeper.
English
Rust Beats C++ by a mile
security.googleblog.com/2025/11/rust-i…
The numbers are crazy IMO.
• Rust: ~0.2 memory bugs per million lines, C/C++: ~1000 per million
• Rust code reviews move ~25% faster
• ~20% fewer review revisions
• Rust changes get reverted far less often, roughly 4x better
Google is pushing Rust into more of Android: drivers, firmware, the whole stack
English
How do std::Mutex and parking_lot::Mutex actually work under the hood? Which one is better? blog.cuongle.dev/p/inside-rusts…
English
Couldn't agree more with Jon Gjengset in this interview: youtube.com/watch?v=nOSxua…
Rust adoption isn't held back by the learning curve. It's the switching costs of existing codebases.
Honestly, learning to write safe concurrent C++ is even harder.

YouTube
English
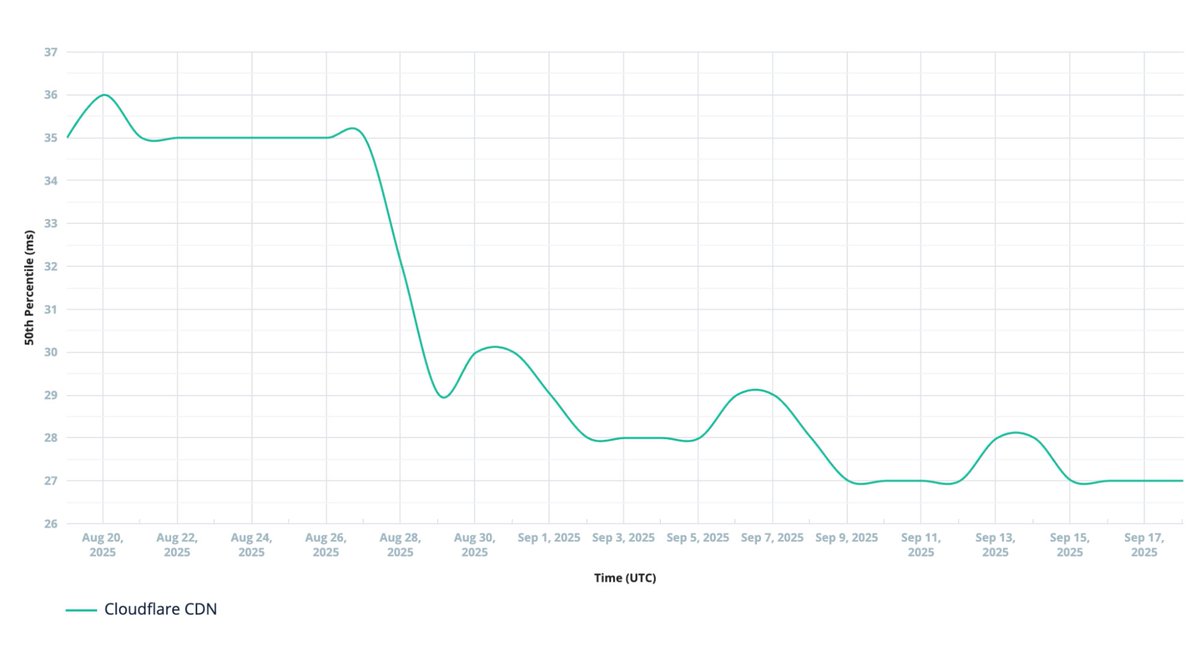
I just read Cloudflare's blog about rewriting their core proxy in Rust and wow, the results are impressive:
• 25% performance boost overall
• Half the CPU, way less memory
• No more memory bugs - crashes now = hardware fails
• Ships features in 48hrs vs weeks (!)
• 100+ devs, 130+ modules, zero drama
• 10ms faster median response time
This is what Rust at Internet scale looks like. It just works.
Source: blog.cloudflare.com/20-percent-int…
English
@cachecrab I think so too. And that’s why I made a blog post on enums that Rust folks on Reddit quite like it. blog.cuongle.dev/p/rust-enum-is…
English

327 upvotes on r/rust today for my blog post!
Check the reddit thread here: reddit.com/r/rust/comment…
And my blog post: blog.cuongle.dev/p/level-up-you…
English
I wrote a post covering advanced Pattern Matching and best practices in Rust. It received a lot of likes on Reddit.
Check it out here: blog.cuongle.dev/p/level-up-you…
English