Sabitlenmiş Tweet

(1/n) 🚀
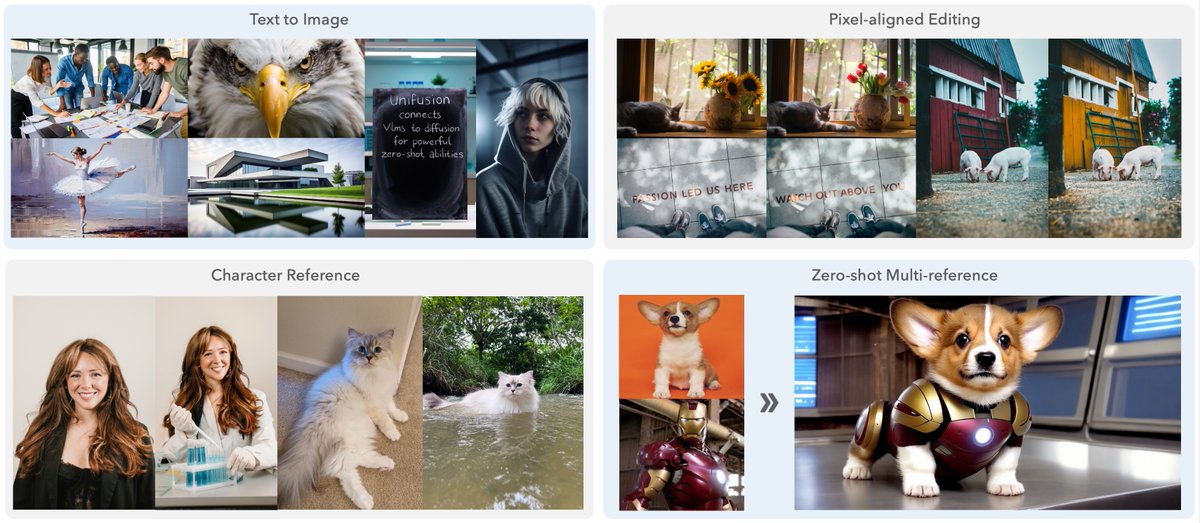
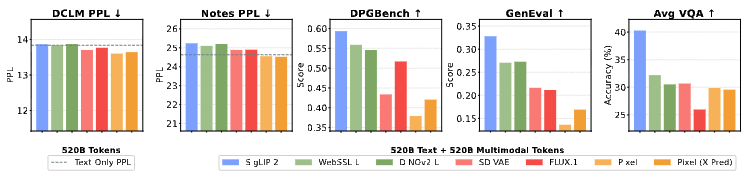
Your VLM can be a great multimodal encoder for image editing and generation if you use the middle layers wisely (yes, plural 😉).
We are thrilled to present UniFusion - the first architecture uses only VLM as input-condition encoder without auxiliary signals from VAE or CLIP to do image editing with competitive quality, to the best of our knowledge.
Here’re what you get with VLM as your unified encoder:
🎯 zero-shot multi-reference image generation when trained only on single-ref pairs
🎯 cross-task capability transfer -- editing task helps text-to-image generation qualitatively and quantitatively
🎯 a competitive text-to-image and editing joint model that beats Flux.1 [dev] and Bagel, respectively, with a smaller model and less data
👇More details in the thread.

English