
@ZeMariaMacedo speaking of independent thinking - guess I could’ve done better last week highlighting kimi (Moonshot AI) team’s original research 😆

English
Dana
490 posts

@DanaBuidl
exploring and scaling the frontier. committed to being the change I wish to see. seeking pmf & deep self-awareness. views are my own. NFA.


Jensen Huang on the future of coding: “Every engineer is going to have 100 agents.” Jensen: “Everything that's too big, too heavy, takes too long, those ideas are all gone.” Chamath: “You're reduced to creativity. Like, what can you come up with?” Jensen: “Exactly.” “Now the question is, how do you work with these agents?” “Well, it's just a new way of doing computer programming.” “In the past, we code.” “In the future, we're going to write ideas, architectures, specifications. We're going to organize teams. We're going to help them define how to evaluate the definition of good versus bad. What does it look like when something is a great outcome? How to iterate with you, how to brainstorm.” “That's really what you're looking for.”

Congrats to the @cursor_ai team on the launch of Composer 2! We are proud to see Kimi-k2.5 provide the foundation. Seeing our model integrated effectively through Cursor's continued pretraining & high-compute RL training is the open model ecosystem we love to support. Note: Cursor accesses Kimi-k2.5 via @FireworksAI_HQ ' hosted RL and inference platform as part of an authorized commercial partnership.

Every single one of the 103 companies Jensen called AI Native today.

@_avichawla Impressive work from Kimi
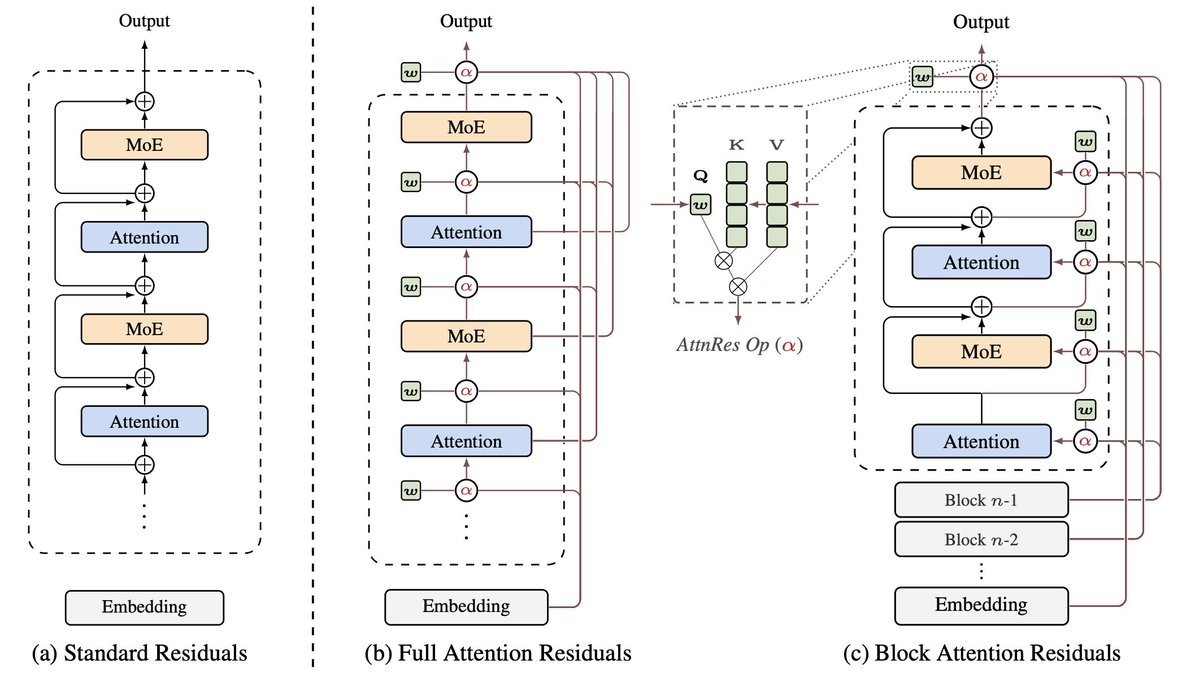
The idea of rotating attention by 90° is sooooooo cool (credits to @Jianlin_S 's insights), and it surprisingly works. We (w/ the amazing @nathan) are so excited about this— been working on the paper for months and couldn't stop. Go give it a try. It's a drop-in replacement for standard residuals, born in 2015. really like the figs btw :-)
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: github.com/MoonshotAI/Att…


Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: github.com/MoonshotAI/Att…






