Sabitlenmiş Tweet
danfiru
2K posts


danfiru
@danfiru
Cofounder & Product @ Quadric. More with More.
Burlingame, CA Katılım Mart 2009
306 Takip Edilen327 Takipçiler
@_TommyMason i'll take the leaf and a rack of npus for tokens at home.
English



@brfootball Dean Huijsen is the only snub, tbh. Madrid have always been a more international club than Barcelona.
English

Not a single Real Madrid player has made Spain’s World Cup squad 🇪🇸

English
danfiru retweetledi

🦙 llama.cpp now has a BUILT-IN model router
♠ and it completely replaces Ollama + Open WebUI for model switching
🔹 One server, one config file, any model on disk
🔹 Switch models instantly without restarting anything
🔹 Zero duplicate model storage across backends
🔹 Full per-model control via a simple INI file
🔹 Native llama.cpp performance, no abstraction layer
🔥 Watch the full video below 👇
youtu.be/V2t_YRsyqeI

YouTube
English
danfiru retweetledi

new release for text-to-cad, an open source CAD harness and skills for codex / claude:
- mechanism validation (go from text prompt to functional mechanical design)
- parameters + animations for step files
- extended sdf, srdf, urdf support
3k stars, 10k downloads, we cooking
English

you can tell this post is from a tech founder because this is not actually running Doom, just blitting some of its sprites.
danfiru@danfiru
an engineer ported DOOM over the weekend. 36fps on a 50MHz fpga emulation. your NPU runs neural networks. ours runs programs. full article in the comments
English
Put your kids in sports.
Relax a little.
But put them in sports.
Brandon Luu, MD@BrandonLuuMD
Scientists measured cardiovascular fitness in 1.2 million 18-year-olds, then followed them for 10-36 years. The fitter they were, the more likely they were to: 1) score higher on intelligence tests 2) earn a university degree 3) reach a higher-status job Do your cardio.
English
@elonmusk @beffjezos I have the HW and the quant. Can I run this at home?
English

@beffjezos Our recently completed Grok V9 1.5T run is looking great and that is before Cursor data is added in supplemental training
English

Impressions so far: Grok Build interface is actually really nice.
Now as soon as xAI has a SOTA model, it could very well become competitive with Codex / Claude Code overnight
English
danfiru retweetledi

Gemini 3.2 Flash - Capitalizing on DeepMind's clever distillation techniques...
Rumors are that benchmarks show it's hitting 92% of GPT 5.5's performance on coding and reasoning tasks while being 15-20x cheaper on inference costs. The latency improvements are insane - sub-200ms for most queries.
Google's distillation + sparsity techniques are paying off massively. They've essentially compressed a frontier model into a flash variant without the usual quality cliff.
English
danfiru retweetledi

💥 What is this beast? Skymizer HTX301 is LLM 🛸👽👇
One PCIe card w/ 📦 384 GB memory ⚡ 240W TDP 🧠 Runs 700B LLMs locally
Vs NVIDIA RTX 6000 Ada:
48 GB • 300W • ~$7,500
Vs RTX PRO 6000 Blackwell:
96 GB • 600W • ~$8,500
HTX301 delivers 8× memory at less than half the power and specialized LPU inference beast for on-prem AI.
🔥 No clusters. No NVLink. Just plug & infer.
Pricing TBA • Early access open now

English
danfiru retweetledi

Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
English
danfiru retweetledi


danfiru retweetledi

i get this question a lot so here is the answer everyone running hermes agent or any local agent should hear: tmux is the separation layer. cheapest, simplest, most reliable way to keep agent contexts from bleeding into each other.
i run a lot of hermes sessions in parallel. one per project, one per active model, sometimes both. each session has its own working directory, its own memory context, its own conversation thread. the work session, the personal session, and the client session never see each other.
a typical day on my main box has 6 to 10 hermes sessions running at any given time. coding project here, research session there, content drafting in another, telegram gateway routing requests in a fourth, model benchmarks in a fifth. zero overhead to switch, zero risk of context bleed.
you do not need docker, a second machine, or elaborate workflow tooling for this. tmux plus a clear naming convention plus one hermes per session is the whole setup. the tools have been there the whole time, most people just have not connected them.
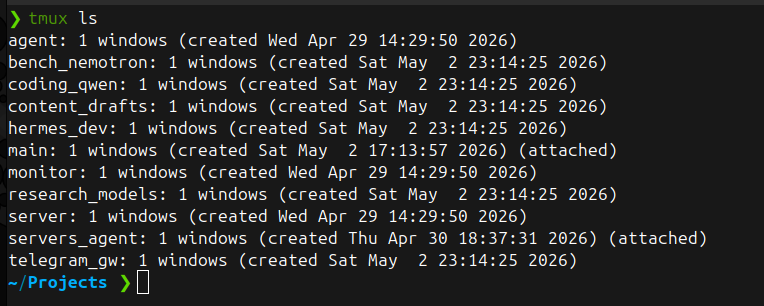
Nemanja@Nemanjadotcom
@sudoingX How do you organize projects and separation? Like would you use the same instance for managing work and personal things?
English
danfiru retweetledi

This MRI study on young kids just exposed something terrifying:
They scanned the brains of 60 children aged 3–5 — including 5-year-old Rose — and found interactive screen time is causing measurable loss of white matter in their developing brains. Even just 2 hours a day is linked to impaired neural connectivity, language, and literacy development.
Professor Mike Nagel (neuroscientist and father) said his first reaction was simply: “Wow… I was not anticipating seeing anything like that.”
We’re physically changing children’s brains before they even start school — and the damage is visible on scans.
This one actually unsettled me. I’ve always suspected too much screen time was bad, but seeing real white matter loss in toddlers hits different.
Parents of little ones — has this kind of research changed how much screen time you allow?
English