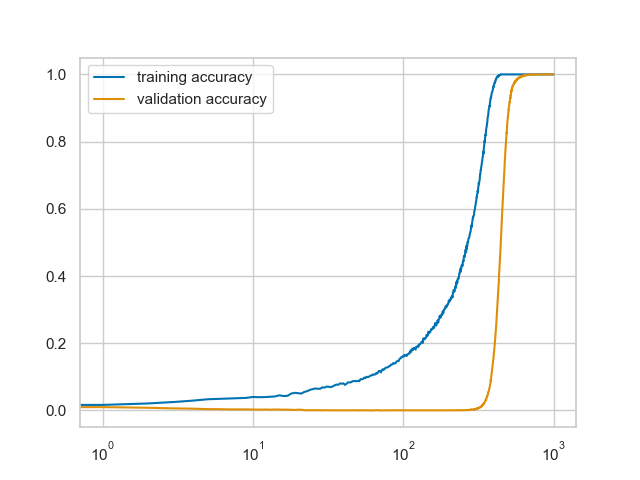
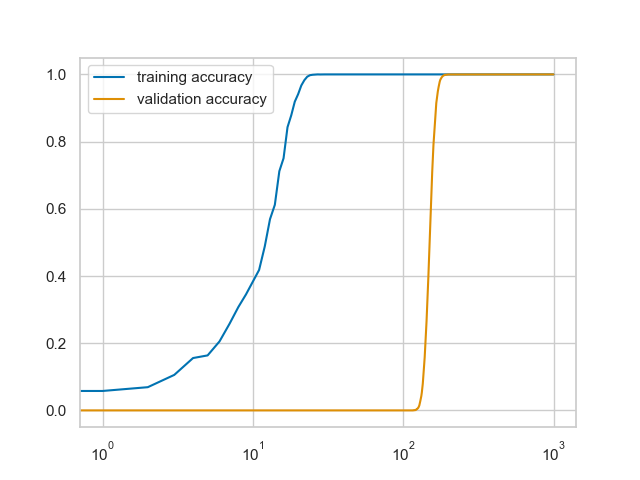
@gabrielpeyre @YihongWu7 Classification and Regression Trees (CART) is a greedy heuristic that runs efficiently but does not offer a performance guarantee. (e.g. XOR-shaped data can still be problematic)
English
Daniël Vos
23 posts
@daniel_a_vos
PhD student in machine learning (decision tree whisperer) at @tudelft 👨🎓 and organizer for the TU Delft CTF Team 👨💻