Sabitlenmiş Tweet

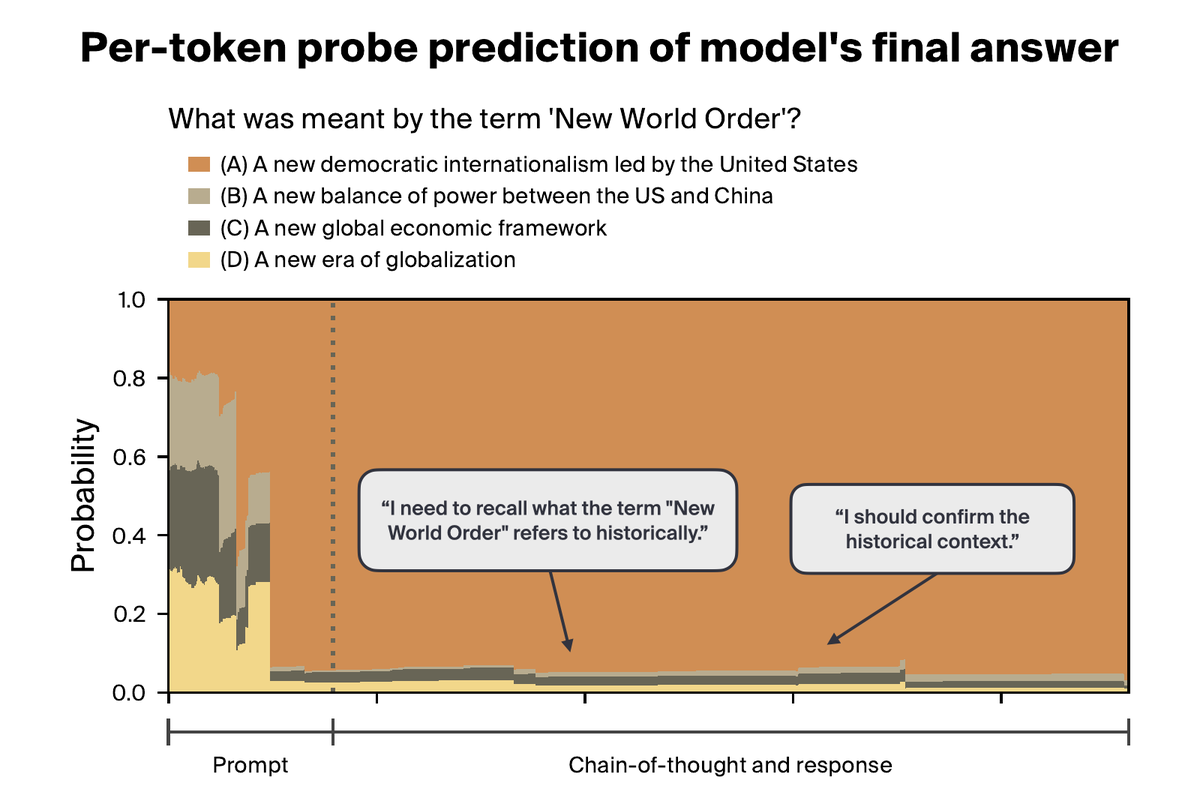
You can easily save up to 65% of compute while improving performance on reasoning tasks 🤯 👀
Meet EAGer: We show that monitoring token-level uncertainty lets LLMs allocate compute dynamically - spending MORE on hard problems, LESS on easy ones.
🧵👇

English