Sabitlenmiş Tweet

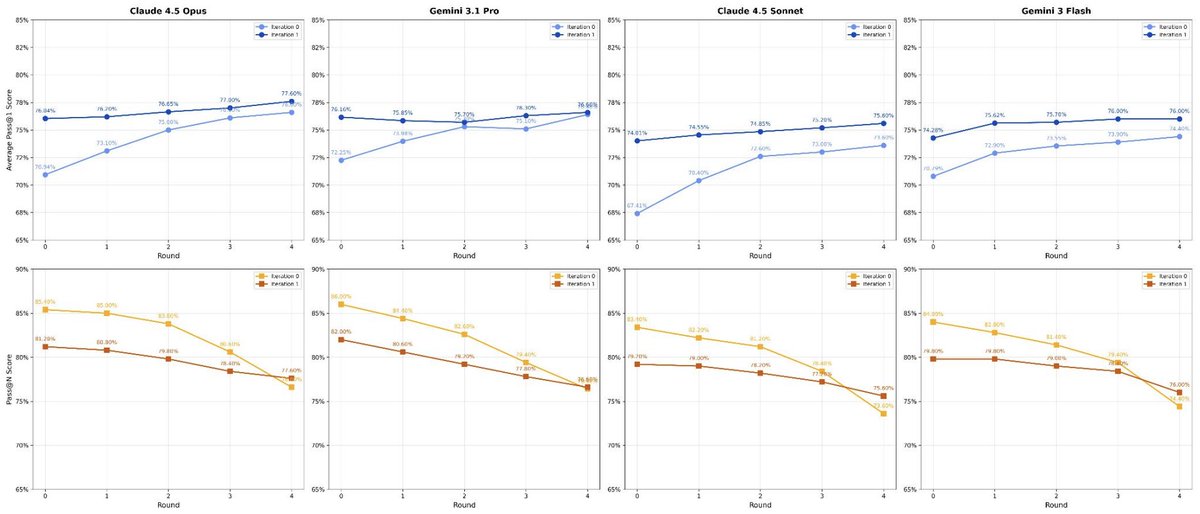
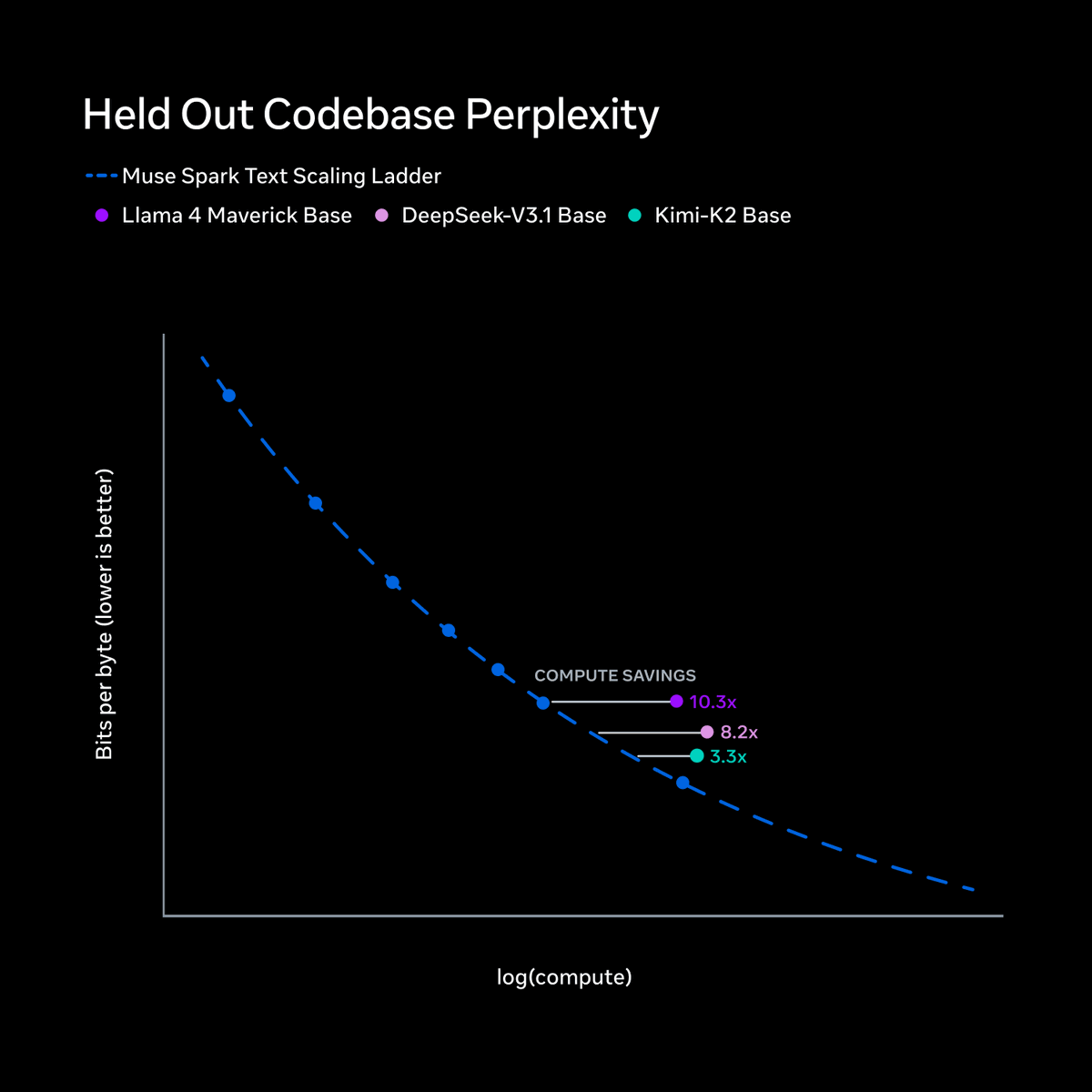
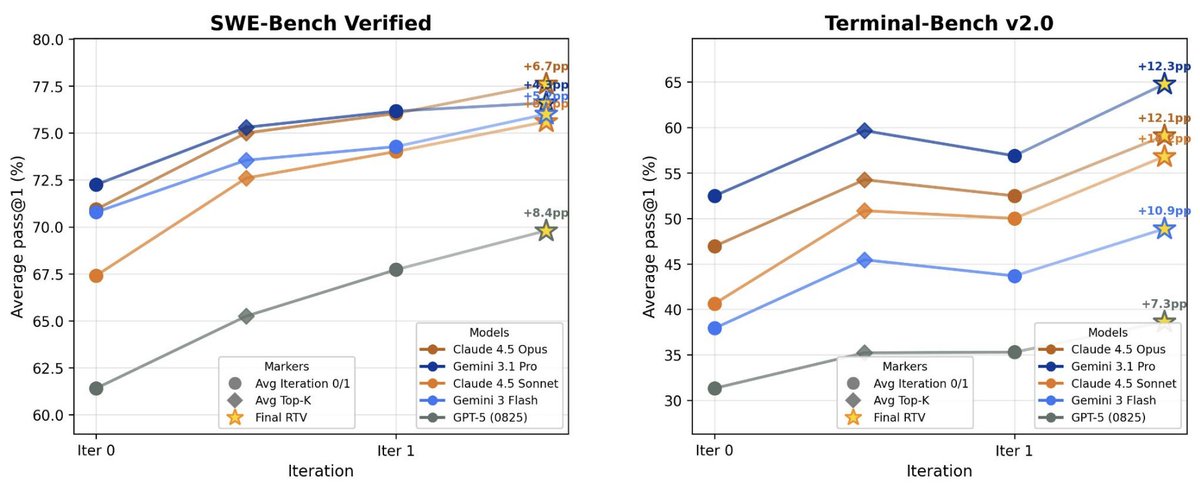
New work @AIatMeta: We enable test-time scaling for long-horizon coding agents by using better representations, selection and reuse of agentic trajectories, with Claude 4.5 Opus improving by +6.7% on SWE-Bench Verified and +12.1% on Terminal-Bench 2.0.
📄: arxiv.org/abs/2604.16529
English