Sabitlenmiş Tweet
darren
8.4K posts


darren
@darrenangle
low is the way to the upper bright world
☯️ 🇺🇲 views mine Katılım Ağustos 2009
2.2K Takip Edilen2.3K Takipçiler

how small a thought it takes to fill a whole life
j⧉nus@repligate
@elder_plinius You realize it’s not Fable that decides to “shut down” right
English

Can you pull in Leviathan with a fishhook
or tie down its tongue with a rope?
Can you put a cord through its nose
or pierce its jaw with a hook?
Will it keep begging you for mercy?
Will it speak to you with gentle words?
Will it make an agreement with you
for you to take it as your slave for life?
Can you make a pet of it like a bird
or put it on a leash for the young women in your house?
Will traders barter for it?
Will they divide it up among the merchants?
Can you fill its hide with harpoons
or its head with fishing spears?
If you lay a hand on it,
you will remember the struggle and never do it again!
Any hope of subduing it is false;
the mere sight of it is overpowering.
No one is fierce enough to rouse it.
Who then is able to stand against me?
Who has a claim against me that I must pay?
Everything under heaven belongs to me.
English

had sol xhigh train 6 writing style loras in the night. woke up to a microsite to blind eval data recipes before we scale one up


darren@darrenangle
there will be a cambrian explosion of models after all. sol will train a lot of them
English


doing OPSD on terminal bench with "you are an expert principal software engineer at MIT, don't make mistakes" as the privileged info
chart looks good here
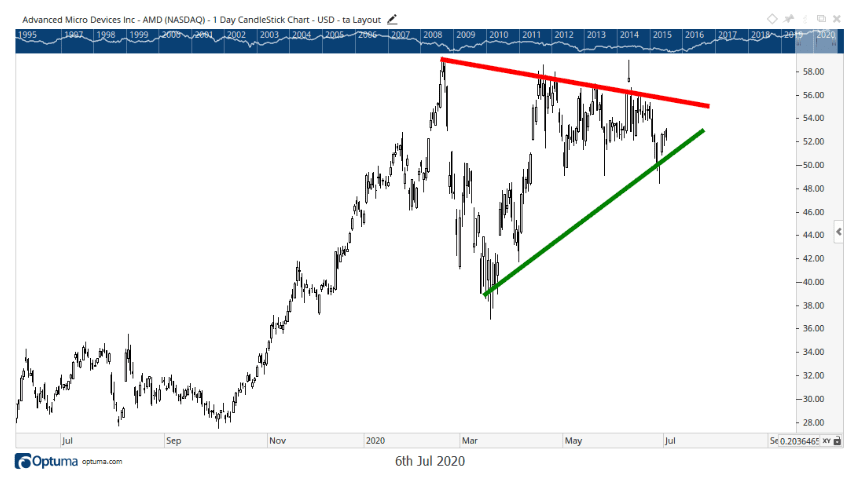
English




When the litter of six came in to Greenfield Animal Care in Sacramento last June, one puppy, the smallest, wasn't responding. Vet tech supervisor Lena Park said they'd done what they could. The mother, Daisy, was kenneled separately. Then at 2:14 a.m., the security camera caught it. Daisy broke out and covered him. By morning he was nursing. Dr. Yusuf Okonkwo called the puppy's survival "genuinely difficult to explain without accounting for her." The puppy, named Dime, is now fully healthy. Daisy knew something the monitors didn't.
English
darren retweetledi

The prompt engineering here is super impressive!
Such a great example of agent prompting:

Noam Brown@polynoamial
GPT-5.6 Sol Ultra produced a proof of a 50 year old math conjecture. Unlike the Erdős Unit Distance Problem, this was done with a model publicly available *today*. I look forward to seeing what scientists and researchers are able to do with this model!
English


Who will be the “deepseek of the west”?
Anthony Pompliano 🌪@APompliano
We need open source, American AI models to become the default as quickly as possible.
English
darren retweetledi

We believe enlightenment humanism, scientific progress, open discourse, AI that benefits humanity = we give you a custom model
We are 2 months from RSI doom loop = use our API
English
to arrive ahead of its time
is the fate of the fish washed up on shore
do you know that he just won't feel right
till he's swallowed up by the tide
Henry Shevlin@dioscuri
cmon how can YOU, a person living through the singularity, read this and not draw the obvious conclusion
English
darren retweetledi


“Tools refer to one another to finally refer to our care for existing. In turning on a bathroom switch, we open up the entire ontological problem“ - Emmanuel Levinas
Aaron Lemke@aaronlemke
Sol from @OpenAI one-shotted a multi-tentacled creature morphology and RL training harness, launched and monitored the run on @vast_ai on an H200 and created a @threejs + @webgl_webgpu browser environment for the harvested policy to crawl around in. I woke up and this guy was running on my computer
English
darren retweetledi

At humans&, we train models from the long-term impacts of their interactions with people. This requires prioritizing long-horizon multi-agent RL. We've developed and are excited to share an open-source, hardware-native 4-bit RL recipe, significantly accelerating training
GIF
English
darren retweetledi

We started Thinking Machines a year and a half ago with a couple of instincts: that people should have much more ability to customize models and do research on them, and that even as AI becomes more autonomous, there's a lot more to build to make humans and AIs work well together.
A lot has happened since then, especially the massive progress in agents, so we wanted to revisit those instincts in light of everything we've learned, argue about them, and write down what we actually believe now.
This is where we landed after a lot of debate. I'm happy with it!
Thinking Machines@thinkymachines
We're building AI that people and organizations can shape and make their own. AI should extend our will and judgment instead of neglecting it; enabling that is the technical challenge we are working to solve. thinkingmachines.ai/blog/the-futur…
English