Sabitlenmiş Tweet

🔥Download the Science of Science book for FREE🔥
We're VERY excited to make the whole book freely available: dashunwang.com/book/the-scien…
Please help us RT & let everyone know of this resource!
#ScienceOfScience

English
Dashun Wang
3.2K posts
@dashunwang
Kellogg Chair of Technology at Kellogg, Founding director, Center for Science of Science and Innovation, Northwestern University

Matt Marx (@marxmatt), professor of entrepreneurship and innovation in the SC Johnson College of Business, is @Cornell’s new vice provost for entrepreneurship, innovation and external engagement. His appointment begins July 1. @CornellDyson news.cornell.edu/stories/2026/0…


✨New paper out @SpringerNature✨ For 8 weeks around the 2024 US election, we randomly assigned 2,000 people to use social media algos we custom-built. Do engagement-based algorithms amplify intergroup, moral & emotional content + does that distort how we see political norms? 🧵
New paper in Nature. The more a government controls its domestic media, the more it dominates AI training data, the more pro-regime outputs we get from AI. By scraping the open web, LLMs are unwittingly laundering state-coordinated narratives into seemingly objective answers.
📄 Excited to share our latest preprint: the first cross-field audit of LLM-hallucinated citations in science ⚠️ Across arXiv, bioRxiv, SSRN & PMC, we estimate 147K fake citations in 2025 alone — threatening both the quality and equity of scientific work.


Excited to announce the 2026 iteration of the Communication & Intelligence Symposium at UChicago! We have an amazing lineup of speakers @Diyi_Yang @johnhewtt @dashunwang @TomerUllman We have a simple call for abstract that is due on Apr 15 (links 👇). Please come and share your research! Co-organized with the awesome @universeinanegg and @divingwithorcas

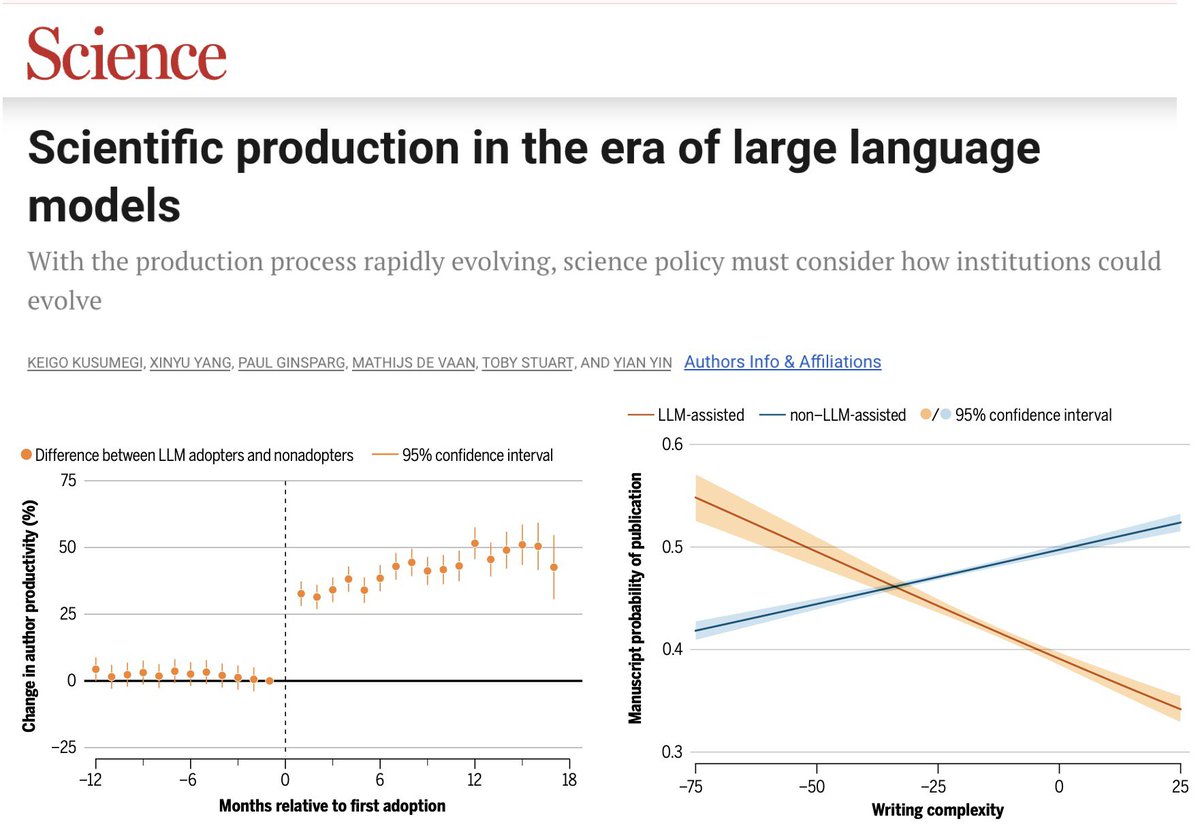
How are large language models impacting the submission and review process at high-impact journals? Severely. Since the release of ChatGPT in 2022, AI-generated and AI-assisted papers, identified by Pangram, drove a 42% increase in submission volume at Organization Science (figure below). While the journal rejected the majority of these submissions, there is a human cost to reviewing papers, which volunteer reviewers are shouldering. AI-generated content is also showing up in reviews, which similarly suffer in quality because of it -- editors at Organization Science found that AI-generated reviews are lower quality, less specific, and less topically diverse than human-written ones. The problem is not isolated. Earlier this year, ICML desk-rejected 497 papers from authors who submitted AI-generated reviews, after those authors opted into a policy that disallowed the use of AI. Grant funders also saw a surge in applications: the Marie Skłodowska-Curie Actions, a set of major research fellowships for the EU, received 142% more proposals in 2025 compared to 2022. Many scientific and academic systems implicitly rely on friction as a barrier to entry. LLMs have removed that friction, allowing for a deluge of AI slop that is straining the capacity of these institutions.
A belated self-promotion of our new paper in @PNASNexus. We ask how the interdisciplinarity of a supporting grant and that of the focal paper jointly shape the paper's scientific impact (academic.oup.com/pnasnexus/arti…). Much assumed, rarely tested; so we tested it at scale! (1/n)

