Daniel Bevenius retweetledi

llama.cpp at 100k stars
now that 90% of the code worldwide is being written by AI agents, I predict that within 3-6 months, 90% of all AI agents will be running locally with llama.cpp 😄
Jokes aside, I am going to use this small milestone as an opportunity to reflect a bit on the project and the state of AI from the perspective of local applications. There is a lot to say and discuss and yet it feels less and less important to try to make a point. Opinions about viability of local LLMs are strongly polarized, details are overlooked, the scientific approach is lacking. Arguments are predominantly based on vibes and hype waves.
One thing is clear though - local LLMs are used more and more. I expect this trend to continue and likely 2026 will end up being one of the most important years for the local AI movement.
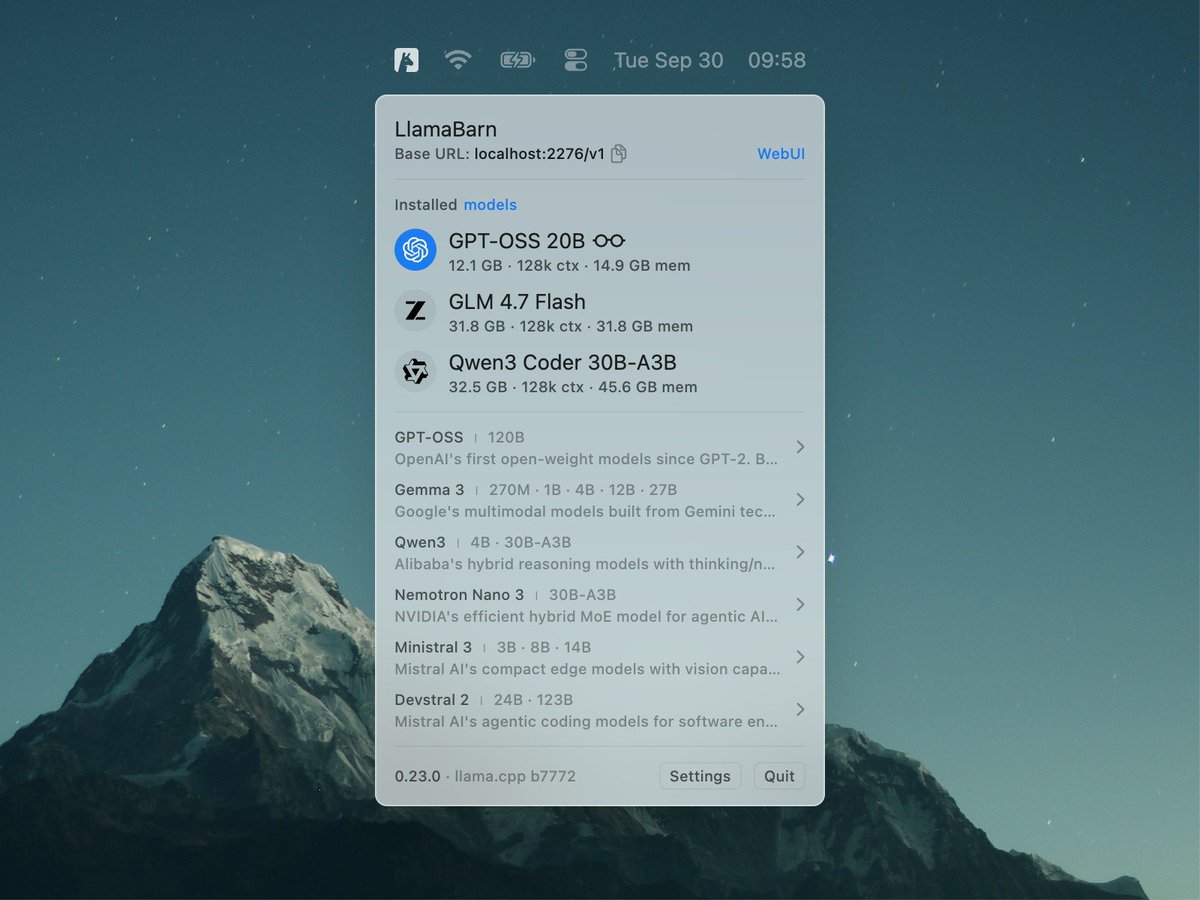
I admit that I didn't expect the agentic era to come so quickly to the local LLM space. One year ago, the available models were too computationally expensive for doing long-context tasks. There wasn't an obvious path towards meaningful agentic applications. The memory and compute requirements were huge. Last summer, with the release of gpt-oss, things started to change. It was the first time we saw a glimpse of tool calling that actually works well within the resource constraints of our daily devices. Later in the year, even better models were released and by now, useful local agentic workflows are a reality.
Comparing local vs hosted capabilities at a given moment of time is pointless. To try put things into perspective:
- We don't need frontier intelligence to automate searches and sending emails
- We don't need trillion parameter models to be able to summarize articles or technical documents
- We don't need massive GPU data centers to control our home appliances or turn the lights off in the garage
I believe that there is a certain level of intelligence we as humans can comprehend and meaningfully utilize to improve our working process. Beyond that level, access to more intelligence becomes unnecessary at best and counterproductive at worst. I also believe that that level of useful artificial intelligence is completely within reach locally and it has always been just a matter of implementing the right software stack to bring it to the end user.
With llama.cpp, I am confident that we continue to be on the right track of building that software stack!
The llama.cpp project is going stronger than ever. With more than 1500 contributors, the project keeps growing steadily.
From technical point of view, I think that llama.cpp + ggml is the only solution that actually makes sense. That is, the software stack must run efficiently on every possible device, hardware and operating system. The technology is too important to be vendor-locked. It has to be developed in the open, by the community, together with the independent hardware vendors. This is the only right way to build something that will truly make a difference in the long run.
I won't try to convince you about what is currently and will be possible with local AI. We will just continue to build as usual. I am confident that after the smoke clears and we look objectively at what we have built together, the benefits will be obvious to everyone.
Big shoutout to all llama.cpp maintainers. I feel extremely lucky to be able to work together with so many talented contributors. Every day I learn something new and I feel there is so much more cool stuff that we are going to build. Also, I am really thankful that the project continues to have reliable partners to support it!
Cheers!


English