
Deepak Kumar
3.9K posts

Deepak Kumar
@deepakdk3478
Building @foundryyai | Production evaluation infrastructure for coding agent labs
Bengaluru, India Katılım Ağustos 2017
496 Takip Edilen6K Takipçiler

@theodormarcu Congrats on this release @theodormarcu!
We have a few production application with quite less tests coverage. Will try to assign the test addition tasks to it under the cloud mode, and see how it performs.
Happy to share the feedback of this code experiment!
English

There's a distinction most people miss about AI coding agents. They assume all agents are basically the same and some just run in the cloud for convenience.
But local and cloud agents are as different as writing code yourself and hiring someone to write it for you.
A local agent works alongside you. It's in your editor, sees what you see, and waits for you on every step. It's a very good pair programmer, but when you close the laptop, it stops. The ceiling on a local agent is your attention.
A cloud agent is a different thing entirely. It has its own machine and its own environment. You can hand it a task and it goes and it just does it. It can work for hours, open PRs, run tests, QAs its own work using computer use, and tells you when it's done.
We built Devin to be the second thing. You can just close your laptop and grab a cup of coffee while Devin is working in the background. The difference is so powerful that people get addicted to it. For example, the best engineers at Cognition (folks like @moritz_stephan and @premqnair) can't stand going to sleep or leaving their laptops without starting a few Devins.
The problem is that until now, local and cloud agents lived in completely different worlds. You'd plan something in your editor, context-switch to Devin, wait for the PR, then context-switch back to touch it up locally if you needed to.
Windsurf 2.0 puts the whole loop in one place. We built an Agent Command Center so you can manage all your agents - local and cloud - from one place.
Windsurf@windsurf
Introducing Windsurf 2.0. Manage all your agents from one place and delegate work to the cloud with Devin - so your agents keep shipping even after you close your laptop.
English
English

Thrilled to announce our new work TestGenEval, a benchmark that measures unit test generation and test completion capabilities. This work was done in collaboration with the FAIR CodeGen team.
Preprint: arxiv.org/abs/2410.00752
Leaderboard: testgeneval.github.io/leaderboard.ht…

English
@xdotli @benchflow_ai Would add @foundryyai to this list as well.
Post training infrastructure for coding agent models: Environment + Data + RLHF Tooling
English

Just logged in on @benchflow_ai LinkedIn and wow we are popular
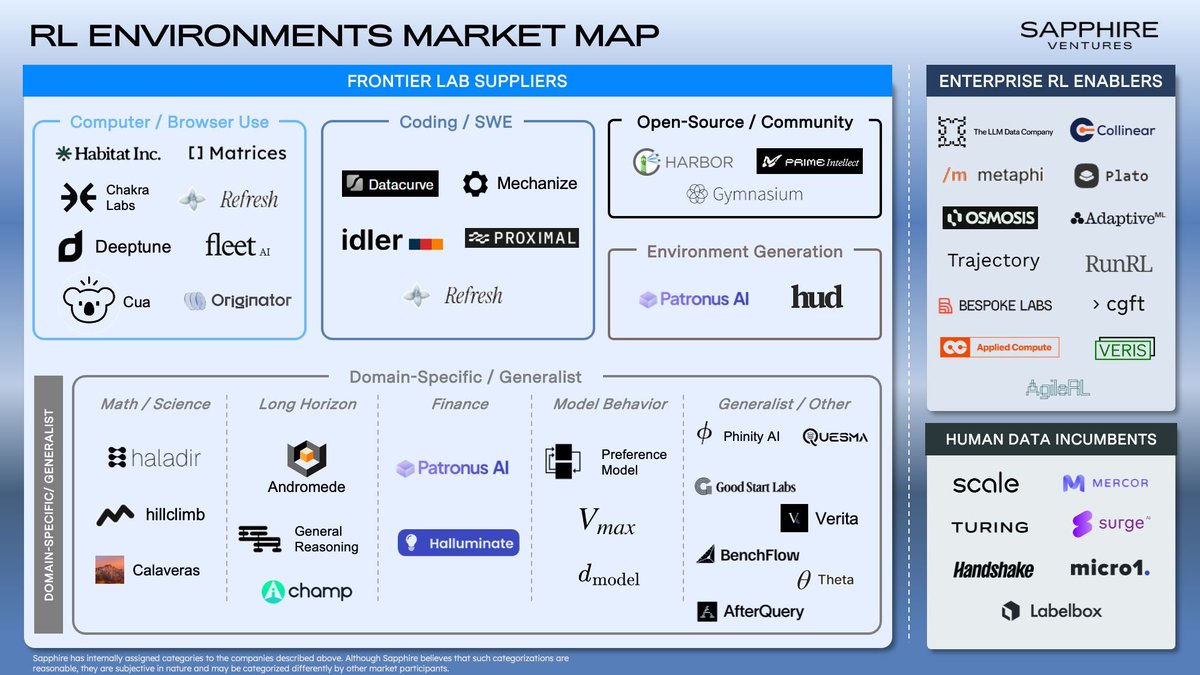
We are a data and environment lab 📐We turned down multiple 8 figure+ acquisition offers from unicorn companies and 7 figure compensation for me to push benchflow's vision.
If environment and benchmark is your thing, I want to chat with you! reply / dm and let's set up a time 🎉

English
Deepak Kumar retweetledi

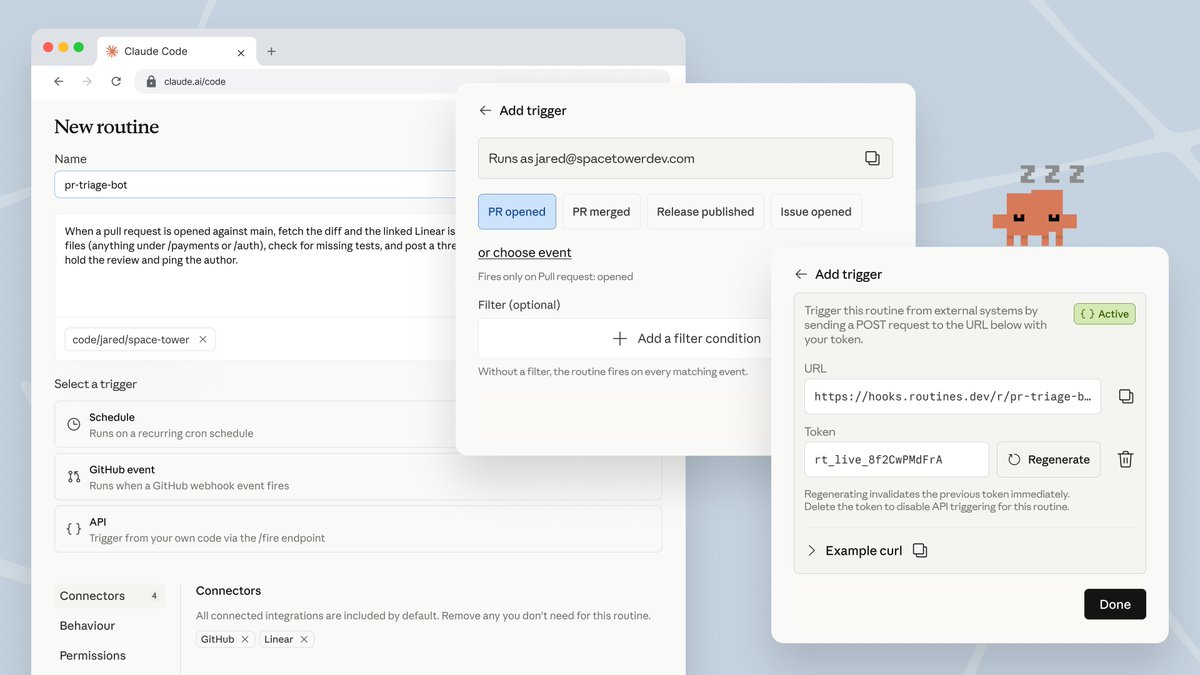
Now in research preview: routines in Claude Code.
Configure a routine once (a prompt, a repo, and your connectors), and it can run on a schedule, from an API call, or in response to an event.
Routines run on our web infrastructure, so you don't have to keep your laptop open.
English

Big news: today is my first day at @OpenAI. I’m joining the Codex team to work on the Codex app.
Couldn’t be more excited for what’s ahead.

English
Deepak Kumar retweetledi

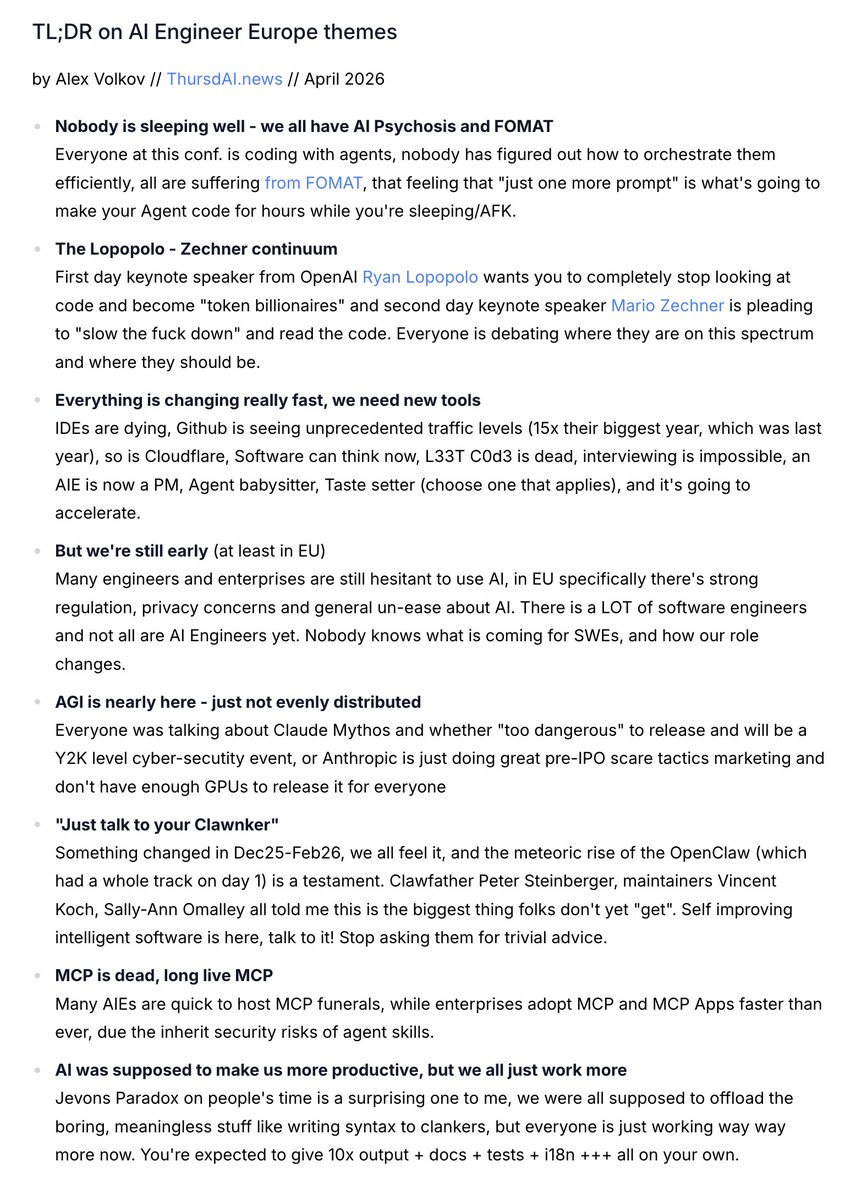
Our world is changing.
I spent the last week listening to, chatting, dining, dancing with and interviewing the top AI Engineers in the world all gathered in London.
Here are the top 8 themes that emerged (a sneak from my upcoming blog covering the event in full 👇)
English
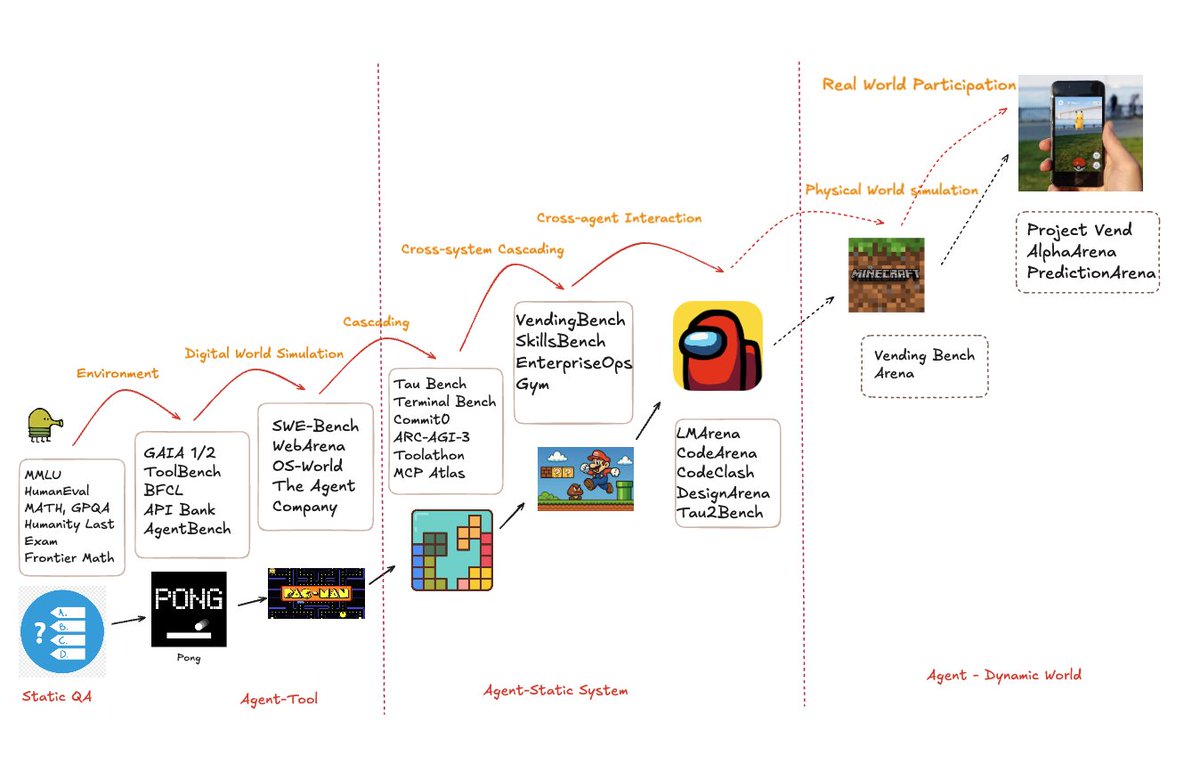
The OpenAI Codex team spent 6 months building an internal product just to understand how their agent behaves in a real codebase.
Most of the AI coding labs wanted to test how their agent performs in production enterprise software deployed. So, the current way is:
- Collect usage data
- Get Post Training insights
- Annotated with human experts
- Finetune the model
- Run the model against the public benchmark (which many labs have reported to have contamination issues)
- Redeploy and launch
This leads to a longer post-training and evals cycle loop.
We are collaborating with AI labs to work on the same problem. Here's how:
- Network of enterprise projects, partnership with 100+ codebases with different environments, atomic, composite stack
- Harness to deploy agents for specific environments
- Collect all the data at each step with a detailed trajectory
- Get quicker post-training signals
- Human experts, software engineers in the loop, to get the required data prepared for training cycle
- Improve the model and scale
- Private benchmark dataset with different layers of evaluation for the coding model with a varied set of problems
Shorter eval loops and agents deployed on production codebases can help labs get the post-training signals they want quickly.
If you're a researcher working on coding agent evaluation or post-training data quality, we're looking for collaborators and early lab partners. Shoot me a DM!
OpenAI Developers@OpenAIDevs
📣 Shipping software with Codex without touching code. Here’s how a small team steering Codex opened and merged 1,500 pull requests to deliver a product used by hundreds of internal users with zero manual coding. openai.com/index/harness-…
English
Worked with the Cursor AI agent for 6 hours to build an eval harness for code evaluation.
In one agent session, the agent was writing a logic to create a clean Git snapshot after each run of tasks. Instead of writing the logic,, it was deleted all the uncommitted files were deleted while testing the logic.
Trying to recover files now using the __pycache__

English
Deepak Kumar retweetledi

We're delighted to announce that MiniMax M2.7 is now officially open source.
With SOTA performance in SWE-Pro (56.22%) and Terminal Bench 2 (57.0%).
You can find it on Hugging Face now. Enjoy!🤗
huggingface:huggingface.co/MiniMaxAI/Mini…
Blog: minimax.io/news/minimax-m…
MiniMax API: platform.minimax.io

English
Deepak Kumar retweetledi

Deepak Kumar retweetledi

GitHub 联合创始人 Scott Chacon 的新项目 GitButler 刚刚宣布完成 1700 万美元 A 轮融资!
GitButler 是一款为现代 AI 编程工作流打造的创新型 Git 客户端(支持桌面端、CLI 以及全新的终端 TUI),专为 AI Agent 时代设计 — 不只是给人用,也给 AI 用。
它不是"更好的 Git",而是在重新思考下一代软件应该怎么被构建。
它的核心优势在于打破了传统的分支工作流,支持并行分支(Parallel Branches)和堆叠分支(Stacked Branches)。开发者可以在同一个工作区同时推进多个功能的开发(例如边修 Bug 边做新功能),彻底告别繁琐的 stash 和分支切换。此外,它深度集成了 Claude 等 AI 助手,能自动生成分支名、提交信息,并支持无限撤销与轻松的提交编辑。
在 UI 层面,GitButler 的设计极具现代感与实用性:采用独特的水平滚动视图,将未分配的更改、多个虚拟分支并排清晰展示,视觉层级分明。
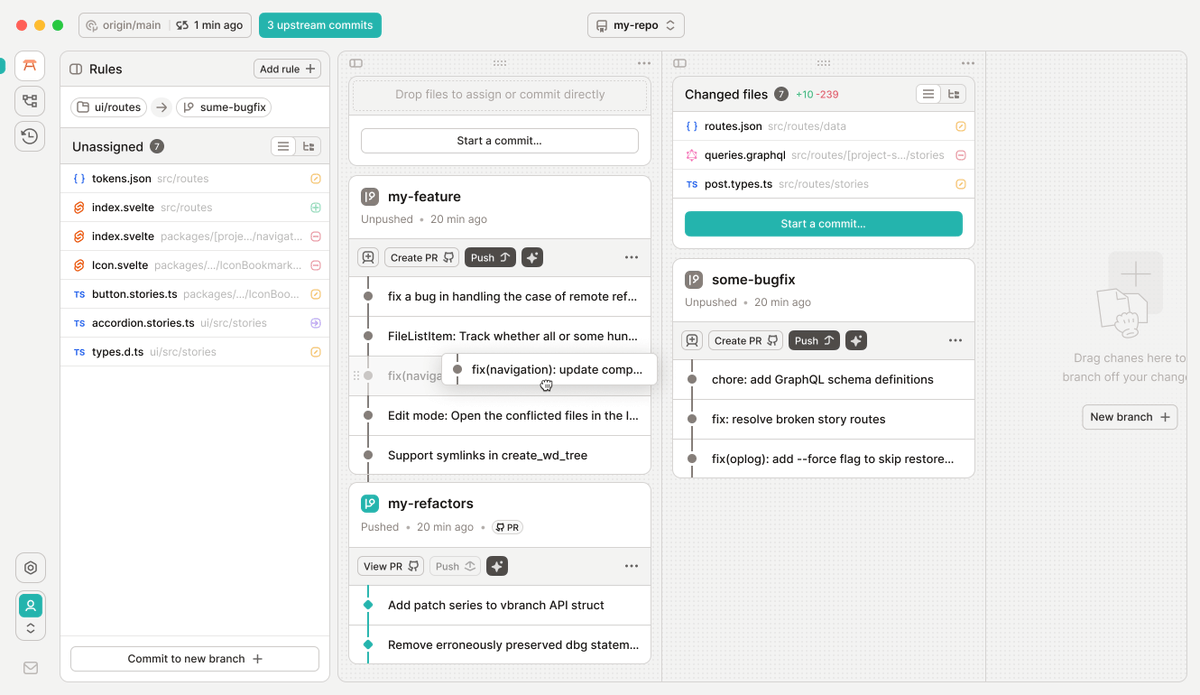
GitButler@gitbutler
We’ve raised $17M to build what comes after Git blog.gitbutler.com/series-a
中文
This is exactly the problem space we are focused on at @foundryyai for the coding agent models.
Building evaluation systems that go beyond benchmarks and actually test real workflows, failure modes, and agent behaviour.
English
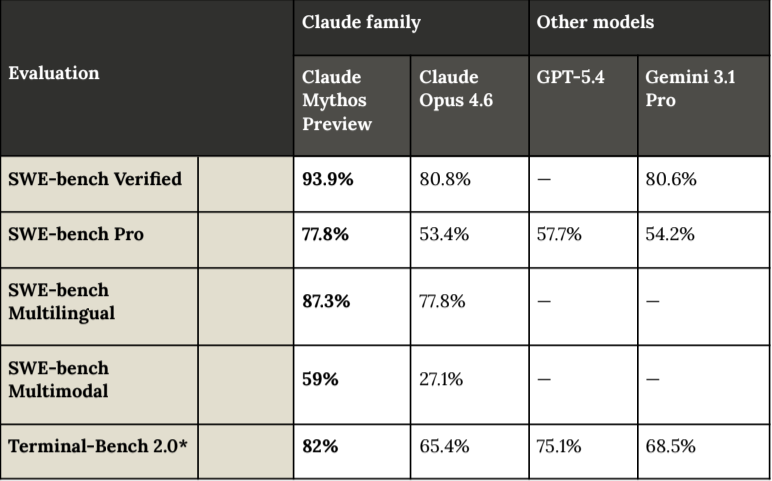
Claude Mythos Preview is being positioned as a "top of benchmark" model.
But after reviewing the system card in detail, that’s not the full story.
Here’s what actually stood out ->
1. Benchmark scores are not the complete signal
Yes, Mythos performs strongly across benchmarks. But the paper mentioned:
- Coding benchmarks had contamination issues
- Anthropic had to filter and rebuild datasets dynamically
- Internal evals are now doing more heavy lifting than public ones
2. Evaluation has shifted from static tests to system-level testing
They are not just running benchmarks anymore. They are using end-to-end evaluation techniques:
- Red teaming with domain experts
- Uplift trials with human plus model workflows
- Long-horizon agentic tasks
- Internal tool-based environments
This is closer to production simulation for model evaluation.
3. Risk assessment came before capability showcasing
They evaluated all the risks related to the model as per their RSP before the evaluation and results:
- Cybersecurity risks
- Biological and chemical misuse
- Autonomous behaviour risks
- Misalignment and reward hacking
As we get closer to AGI, risk assessment is more important than the evaluation.
4. Why is this model treated as a cybersecurity system?
Mythos is not broadly released, though have shown strong cybersecurity capabilities:
- It can discover and exploit vulnerabilities
- It can also fix and patch them
5. Strong reasoning, but weak research autonomy
The model performs well in structured reasoning and coding, but still struggles with:
- Novel research direction and prioritisation
- Feasibility in domains like drug discovery
It accelerates experts, doesn’t replace them, as per the evaluation done in collaboration with different teams.
6. The paper shows that internal benchmarks and trajectory-based tuning matter more now
- Heavy use of internal benchmarks
- Training via trajectory-level annotations
- Focus on multi-step behaviour, not just final outputs
Not just what it answers, but how it gets there in a step-wise approach.
One thing is clear, as in the development of the models, benchmark scores are a way of showing the capability of the models, but the evaluation is done end-to-end with human experts in the loop to see how the model is safe to use, controllable and reliable in real-world scenarios.
English
Deepak Kumar retweetledi

Claude Mythos.
Ten trillion parameters: the first model in this weight class. Estimated training cost: ten billion dollars.
On the hardest coding test in the industry (SWE bench) it scores 94%.
It found a security flaw in a system that had been running for 27 years, one that every human engineer and every automated check had missed. It found another bug that had survived five million test runs over 16 years. (It did so overnight.)
It is so capable in cybersecurity that Anthropic will not release it to the public, instead it is launching Project Glasswing along with 100m in compute credits to help secure software.
Only twelve partners currently have access: Amazon, Cisco, Apple, Google, Microsoft, NVIDIA, JPMorgan Chase, Crowdstrike, Palo Alto, AWS, The Linux Foundation, Broadcom. (I'm sure the Pentagon is on the line?)
This is not a product launch: it is a controlled deployment of a system too powerful to distribute freely.
Tell me this isn't (very expensive) AGI?
Anthropic@AnthropicAI
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software. It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans. anthropic.com/glasswing
English
Deepak Kumar retweetledi
Benchmarks like SWE-Bench and SWE-Bench Pro are focused on evaluating the capability of coding agents for code generation-related tasks. A few evaluate other capabilities of the model related to code review. To support this, we at @foundryyai have published SWE-PRBench.
A dataset of 350 pull requests where the ground truth is the review by the human engineers. The benchmark measuring whether frontier LLMs catch similar issues that reviewers catch in production code.
The results of top models on SWE-PRBench:
- Claude Sonnet 4.6 by Anthropic - 29.7% detection, 22.7% hallucination
- DeepSeek V3 by DeepSeek AI - 31.2% detection, 31.5% hallucination
- Mistral Large 3 by Mistral AI - 30.5% detection, 35.3% hallucination
- GPT-4o by OpenAI - 22.0% detection, 19.3% hallucination
The best model still missed 7 in 10 issues that human reviewers caught.
And the finding that surprised us most: adding more context made every model worse. All 8 models degraded monotonically as context expanded. When we added execution context and surrounding file content, Type2_Contextual issue detection collapsed by 50–55% across top models.
The gap between code generation benchmarks and code review benchmarks tells us something important: progress on SWE-Bench does not predict progress on code review. These are different capabilities, and the field has been measuring only one of them.
This is the generalisation gap where the focus is less.
Full results below!
English
Deepak Kumar retweetledi
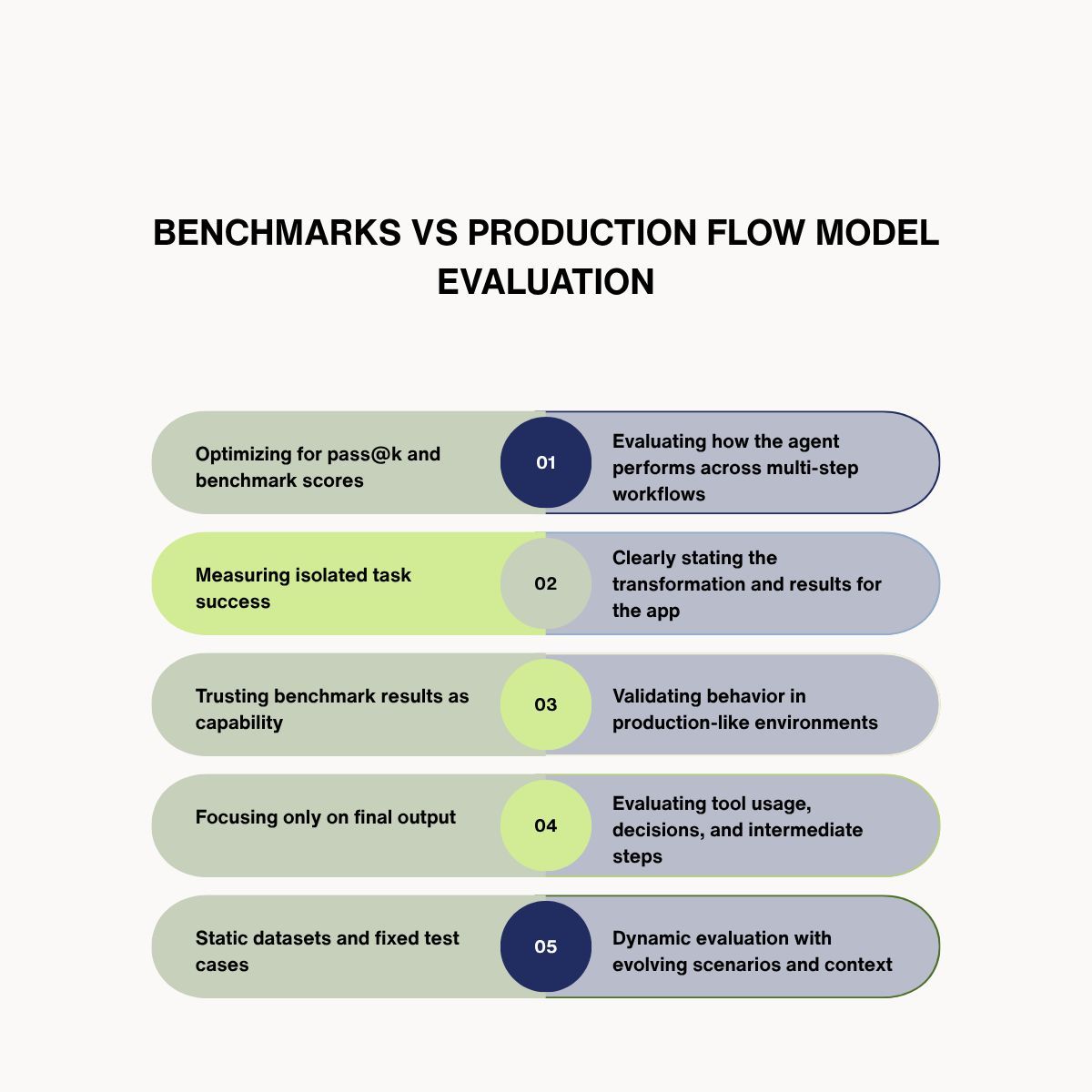
Coding labs are moving to better and more robust benchmarks.
OpenAI released a blog stating that SWE-Bench Verified no longer reflects real model capability.
Passing tests ≠ correct behaviour
Task success ≠ system performance
The shift is clear:
Public benchmarks → production-grade evaluation
Companies like OpenAI, Cursor and other AI labs are already using private benchmarks for model evaluation.
English
@silasalberti @cognition Congrats to the team. Silas!
The speed of the response looks quite great.
Just wondering, how the model UX problem was tested with traditional benchmarks?
English


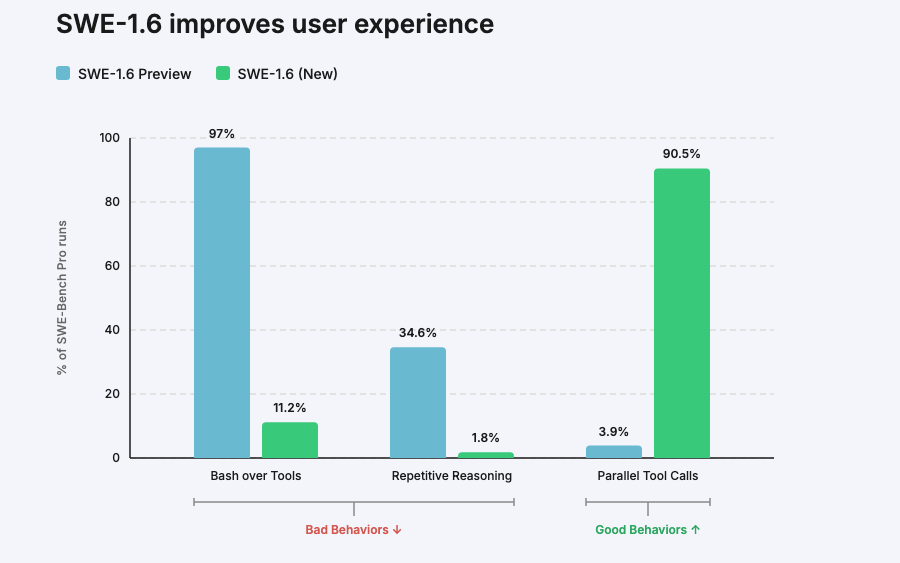
We’re releasing SWE-1.6, our best model in both intelligence & model UX. SWE-1.6 matches our Preview model on SWE-Bench Pro while dramatically improving on various behavioral axes.
It’s available today in Windsurf in two modes: free tier (200 tok/s) and fast tier (950 tok/s).
English
Deepak Kumar retweetledi

We released Claude Opus 4.6 just two months ago. Today we're sharing some info on our new model, Claude Mythos Preview.
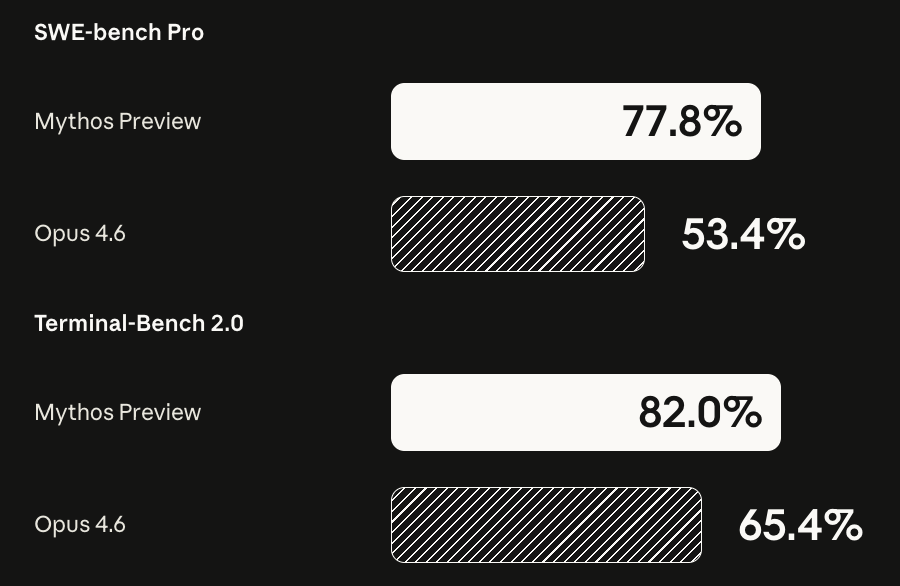

English