BenchFlow retweetledi

the first update on the SkillsBench paper has been made available on arXiv
English
BenchFlow
37 posts

@benchflow_ai
frontier evals and rl environments









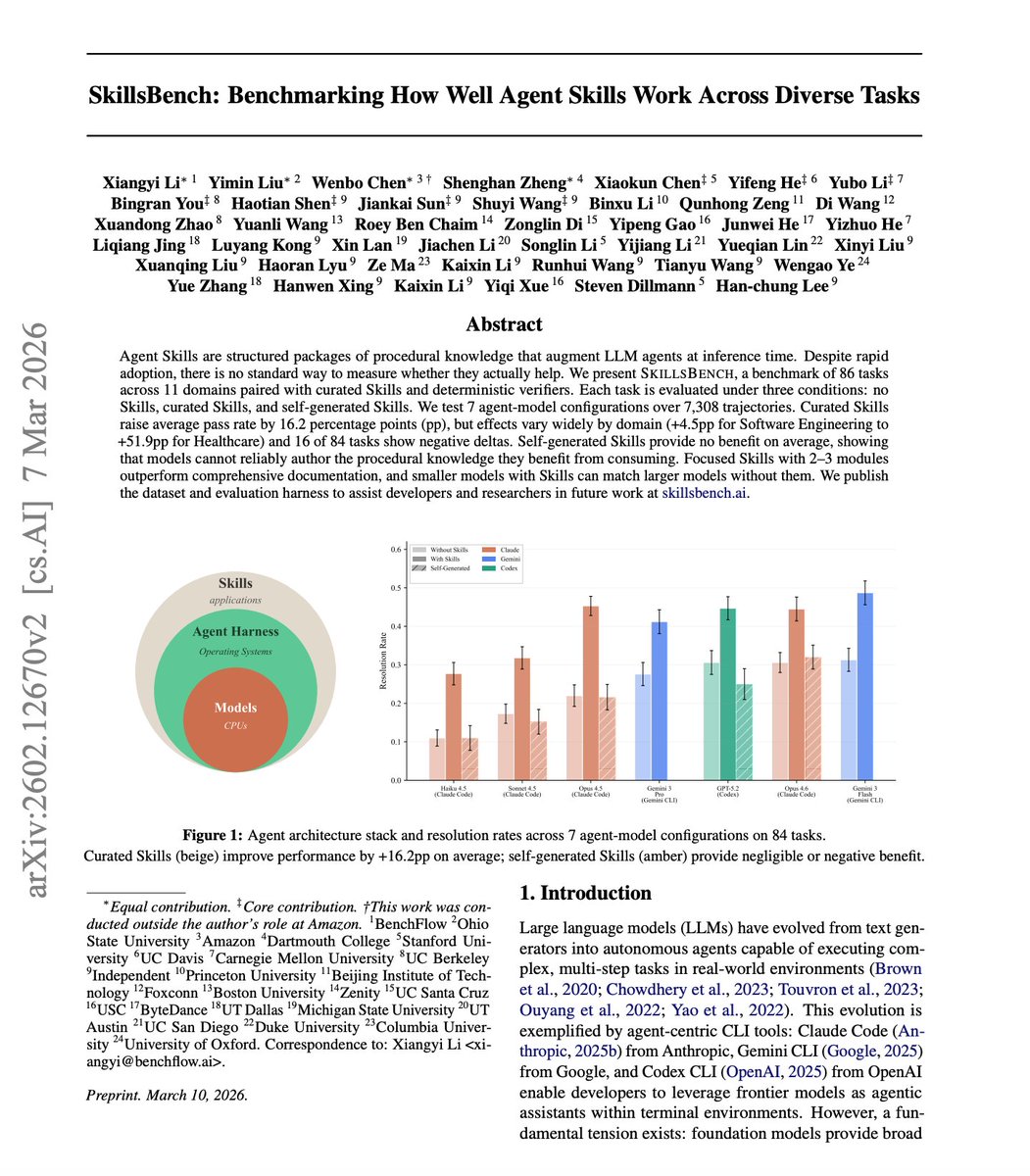
The zero benefit from self-generated skills is a tough reality check for autonomous loops. We're still relying on manual curation to unlock that 16.2% boost. Also wild to see the disparity between domains—Healthcare jumping +51.9pp while Software Engineering only saw +4.5pp suggests current models already saturate coding context but starve for domain-specific workflows.
Nice paper studying whether agents can generate their own procedural knowledge. This is very important to build more reliable self-improving agents. The new benchmark evaluates how well Skills help LLM agents across 86 tasks and 11 domains. Finding over 7,300 agent trajectories: Curated Skills improved agent pass rates by 16.2 percentage points on average. But the gains varied wildly, from +4.5pp in Software Engineering to +51.9pp in Healthcare. The most surprising finding is that self-generated Skills provide no benefit on average. Models struggle to create the procedural knowledge that actually helps them. Focused, concise skills outperformed comprehensive documentation. And smaller models with Skills matched larger models without them. If agents can't reliably create their own procedural knowledge, the curation and design of Skills becomes a critical bottleneck for agent systems. Paper: arxiv.org/abs/2602.12670 Learn to build effective AI agents in our academy: academy.dair.ai



Agent Skills are everywhere - Claude Code, Gemini CLI, Codex all support them. But do they actually work? 105 domain experts from Stanford, CMU, Berkeley, Oxford, Amazon, ByteDance & more built SkillsBench to find that out. 86 tasks. 11 domains. 7,308 trajectories. 🧵👇

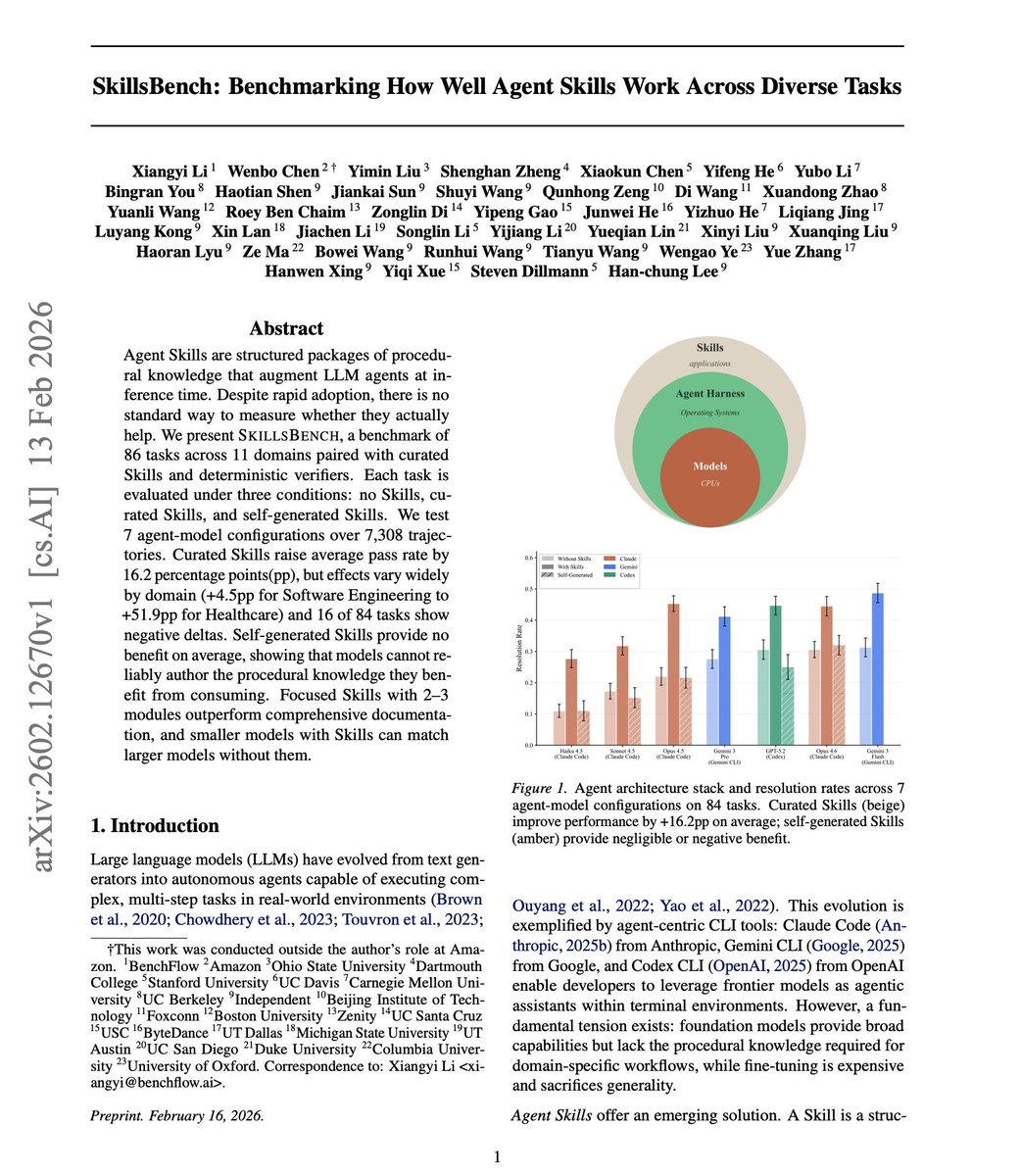
Agent Skills are everywhere - Claude Code, Gemini CLI, Codex all support them. But do they actually work? 105 domain experts from Stanford, CMU, Berkeley, Oxford, Amazon, ByteDance & more built SkillsBench to find that out. 86 tasks. 11 domains. 7,308 trajectories. 🧵👇
Given the most effective skills Can agents correctly implement the DeepSeek mHC paper from scratch and train nanoGPT with FineWeb? We made a benchmark and we found Claude Code was able to not only achieve targeted loss, but also replicate main conclusion from the paper ->

