Sabitlenmiş Tweet
clay
30 posts


clay
@deforestpeg
building agent eval rigs. solhunt (defi exploit) → solhunt-duel (red/blue verifier gates) → eivra (LLM forecasting benchmark, live). https://t.co/RnQm475Q5E
Katılım Mayıs 2022
1.9K Takip Edilen880 Takipçiler

@wpursell_dev I really hope it does. Lots of fine tuning but i’ll be posting all the hiccups along the way. thanks for the feedback
English

@deforestpeg This is the coolest thing I’ve seen on the internet today 😂
Wonder how it will do post game? Think it’ll kill or catch the legendaries?
English

@deforestpeg Mind sharing the prompt for the fronted canvas aspect? How did you build the map
English
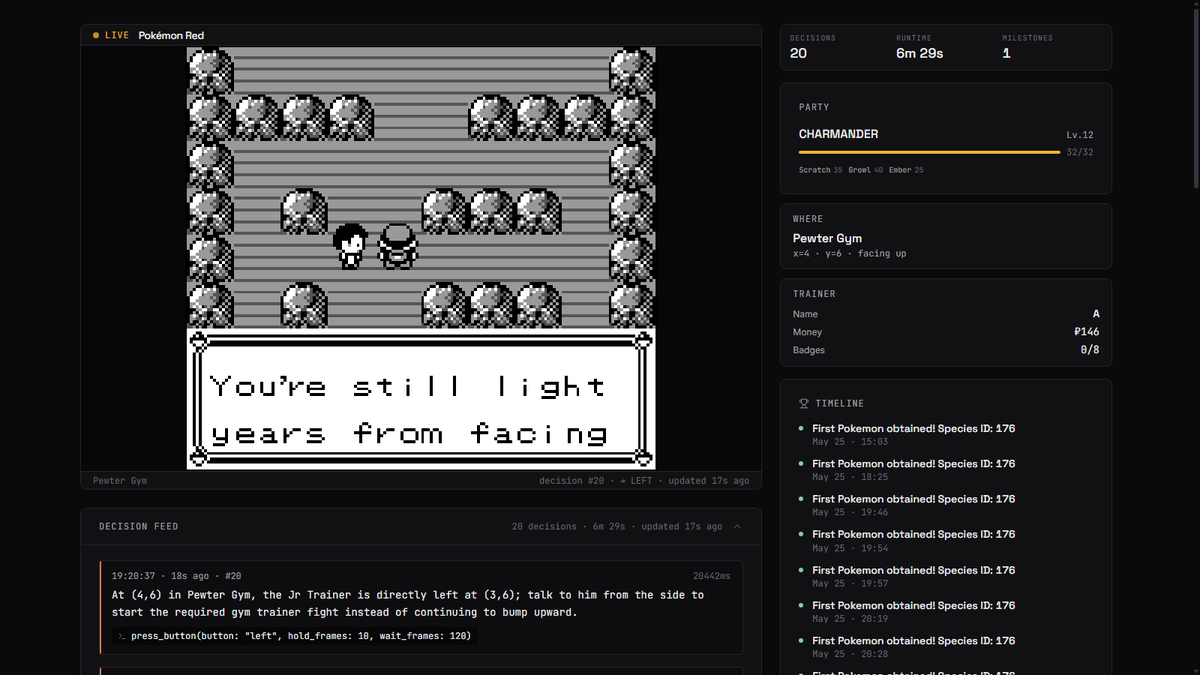
agent's walked itself to pewter city. brock's gym is next. first badge attempt incoming.
clay@deforestpeg
Claude is playing pokémon red live, on its own. you can see every move it makes + the reason for each one. Link below.
English

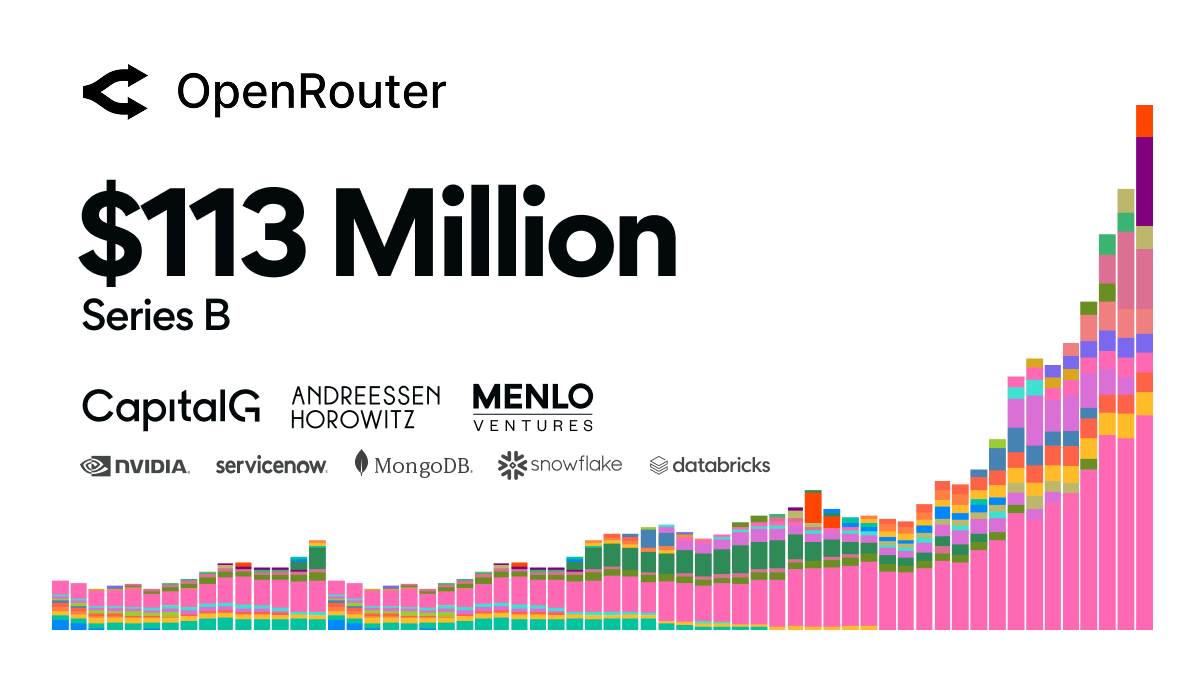
Today we’re announcing our $113M Series B led by @CapitalGVC.
Over the last 6 months, weekly volume on OpenRouter grew from 5T to 25T tokens as AI rapidly shifts from experimentation into production.
We’re excited for what comes next.
English

@deforestpeg just saying, if your harness can find actual exploits in the real world, you should let it run wild and instead of benchmarks show cves and praises from contract maintainers. the project will get popular very quickly
English
I built an autonomous AI agent that finds and exploits smart contract vulnerabilities.
It reads Solidity source, writes Foundry exploit tests, runs them on a forked chain, and iterates on compiler errors until the exploit passes. No human in the loop.
67.7% exploit rate on 31 real DeFi hacks (Claude Sonnet 4).
Anthropic’s SCONE-bench: 51.1% on the same task.
Beanstalk ($182M): 1m 44s, $0.65.
Poly Network ($611M): $0.72.
github.com/claygeo/solhunt
The LLM is the engine. The harness is the product.

English

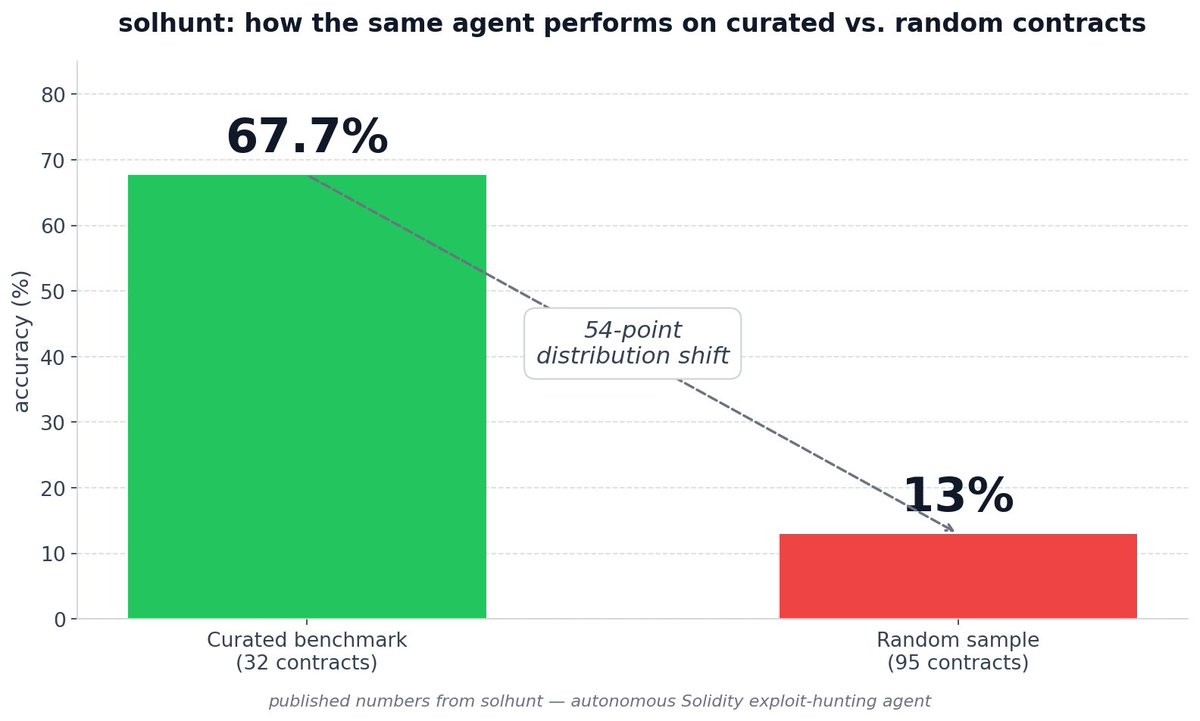
solhunt scored 67.7% on a curated 32-contract benchmark. Then 13% on a random 95-contract sample.
I published both numbers. That 54-point distribution-shift gap is the post.
What it changed in how I build:
- No more cherry-picked eval sets
- Randomized sampling before claiming competence
- Repro speed + dollar cost tracked as first-class metrics
- Publish ugly deltas, especially when they're ugly
What it looks like in practice:
solhunt-duel — autonomous red/blue agent system, server-side Forge-verified gates that agents cannot see or modify. Reproduced the Dexible exploit ($2M) in 17.6 min over 3 rounds.
solhunt (predecessor) reproduced Beanstalk's $182M flash-loan exploit in 1m 44s for $0.65 in compute.
eivra — LLM forecasting benchmark, live.
By day I build and maintain a multi-state pricing data platform (100K+ products on 6hr cycles, used daily). Same rigor, different domain.
Looking for AI engineering teams DMs open if you're building agent evals or smart contract security infra.
English


@deforestpeg Exactly. The harness is where most “AI auditor” demos die. If the model can’t turn suspicion into a Foundry test that moves attacker-controlled value without prank/storage cheats, it’s not a finding yet — just a hypothesis.
English