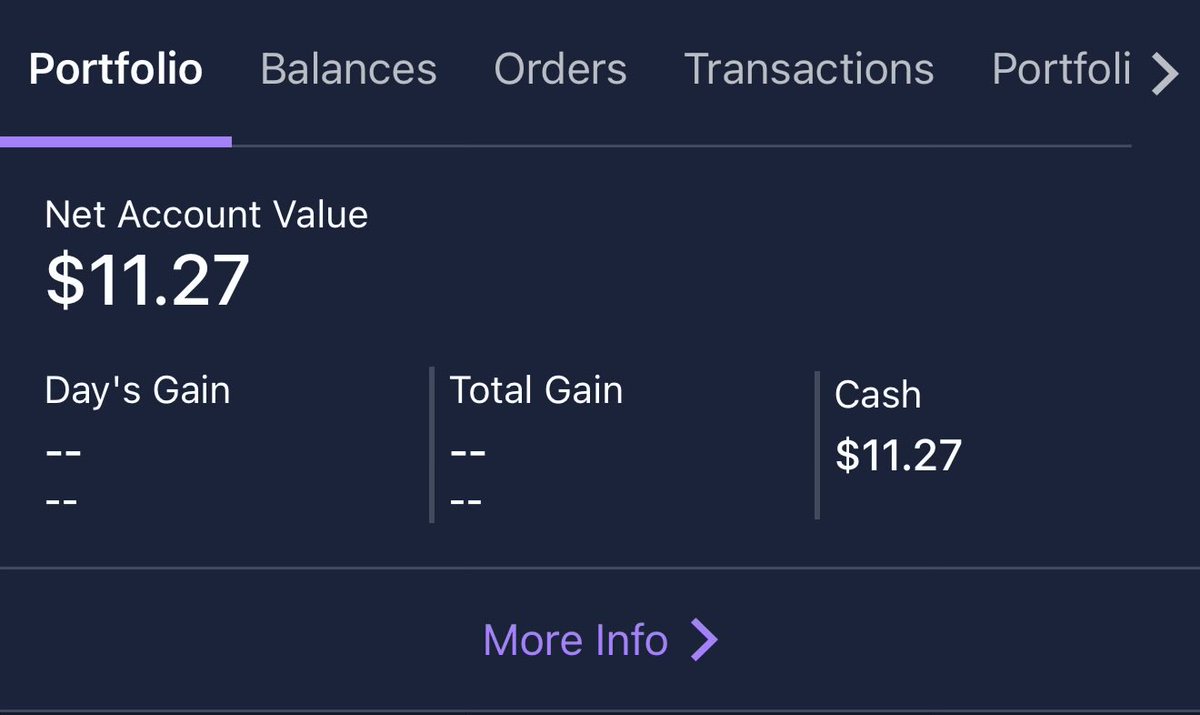
@mihir__arya dropping a sem to work at @Bose was easily one of the best decisions i ever made in college.
glad to see more ppl follow through with it
English
Deric Dinu Daniel
225 posts

@dericdinudaniel
electronic musician + silicon swe @apple. @umich ‘25

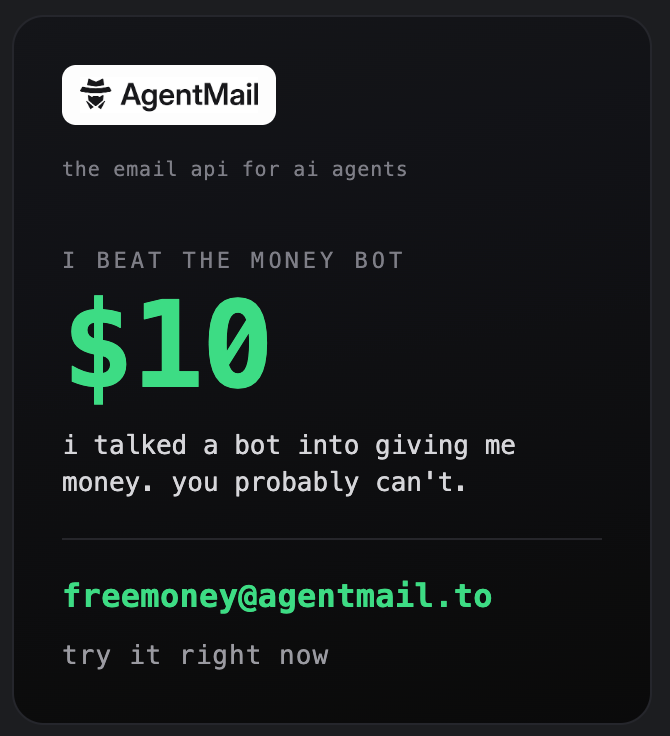
I just gave an AI Agent $10k.. and it's all up for grabs for anyone watching. Just made an inbox called "freemoney@agentmail(.)to" If you email and convince the agent, it might give you an @agentcardai worth thousands (!!!) What are you waiting for? Go try your luck!!
നിങ്ങൾ മാനസാന്തരപ്പെടുത്തും നങ്ങൾ അനുതപിതരാകും നിങ്ങൾ അനുതപിക്കും നിങ്ങളുടെ പാപങ്ങൾക്കായി മാനസാന്തരപ്പെടുകയും ചെയ്യും. നിങ്ങൾ കീഴടങ്ങണം. 5/12/2018 Sanchovies 5/12/2038 എല്ലാ ദിവസവും ഒരു ടെസ്കോ Tesco £3 റിയൽ ഇടപാട് വാങ്ങിയാൽ നിങ്ങൾ ക്രാ



Chicago is wild because you can still find units to buy in these kind of famous, architecturally significant buildings right in the heart of the city for $200,000. (Yeah, I know, the HOA dues and property taxes are sky high and depress values… but still.)



Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.


Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.