Sabitlenmiş Tweet

Generative models are great at mimicking data — but real (scientific) discovery requires going beyond it.
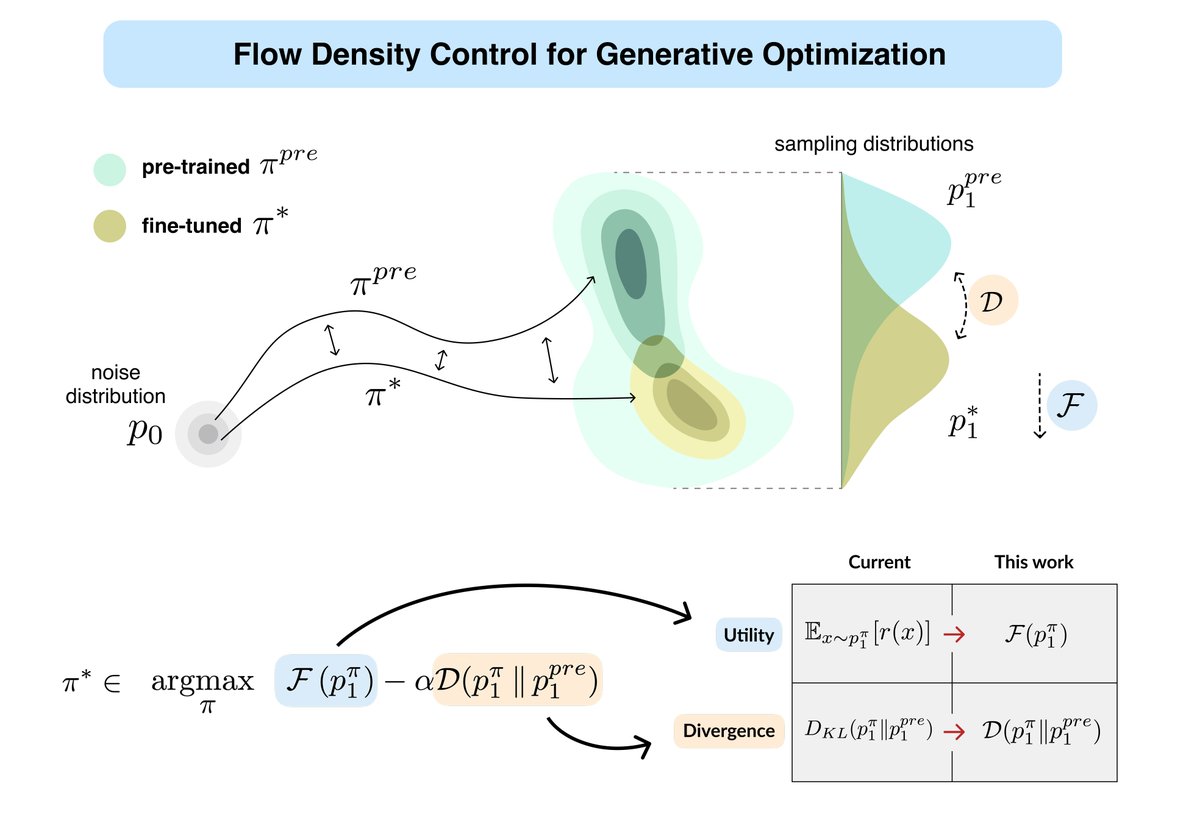
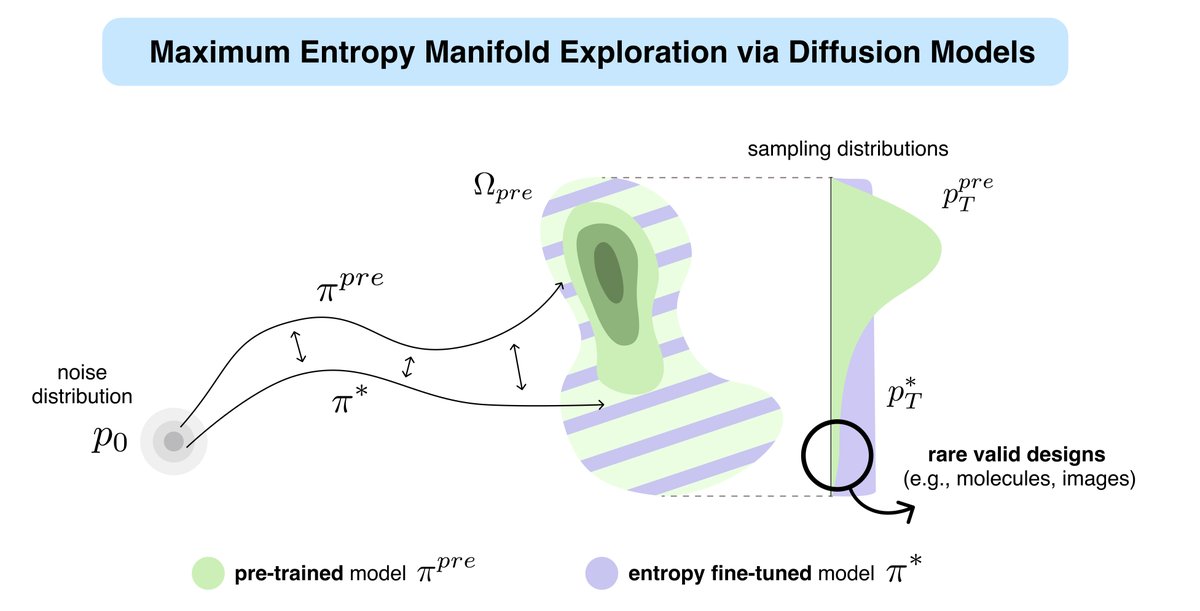
Excited to present our paper “Provable Maximum Entropy Manifold Exploration via Diffusion Models” this Wednesday at ICML 2025!
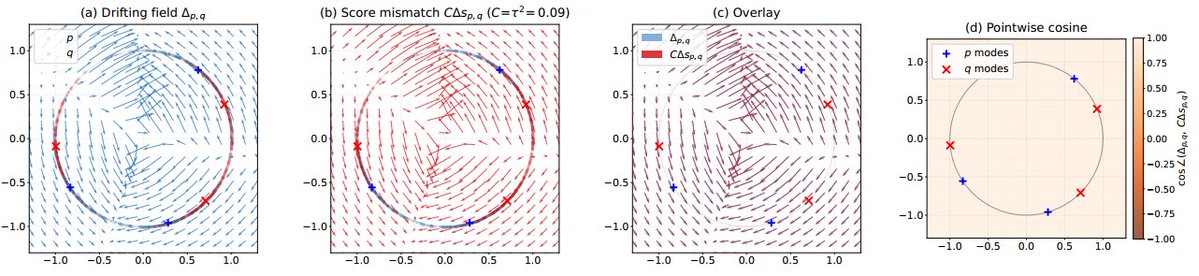
We propose a scalable, theoretically grounded method to fine-tune a pre-trained diffusion model to become maximally explorative over its learned manifold. This makes it possible to go beyond high-density regions and uncover hidden modes via a novel mechanism for self-guided surprise maximization.
Feel free to reach out if interested — and check out riccardodesanti.com for updates!
📄 Paper: arxiv.org/abs/2506.15385
⏳Wednesday at 4:30pm (Vancouver time), Hall A-B/E-2011!
Work done with amazing collaborators @vlastelicap, @yapinghsieh, @ZebangShen, Niao He, and @arkrause
English