Sabitlenmiş Tweet

Started a weekly email – Build Notes. What I find each week building with agents
First issue covers context quality, content entropy and session discipline

English
Dan Hopwood
7.9K posts

@dhpwd
Building Fidero (data platform) with no engineering team. AI agents run everything. Sharing the secrets ↓




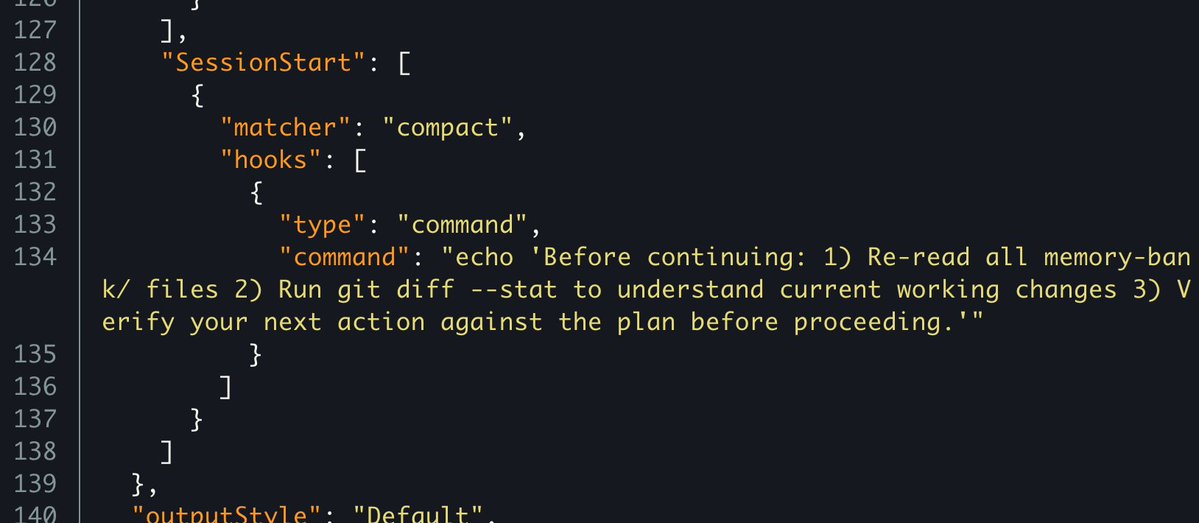


The cofounder and CTO of Perplexity, @denisyarats just said internally at Perplexity they’re moving away from MCPs and instead using APIs and CLIs 👀


