@Zipcar still waiting for your awful customer service to get back to me with the refund.
Seattle, WA 🇺🇸 English
Dhruv Verma
33 posts

@dhr_verma
SWE @microsoft, Grad student @stonybrooku






Excited to announce that 9 papers from Stony Brook NLP and collaborators were accepted to #ACL2023NLP #NLProc Very grateful to contributors @dhr_verma @lal_yash @SinhaShreyashee @azpoliak @ben_vandurme @mhdbst @msurd @b_niranjan @tusharkhot 1/2
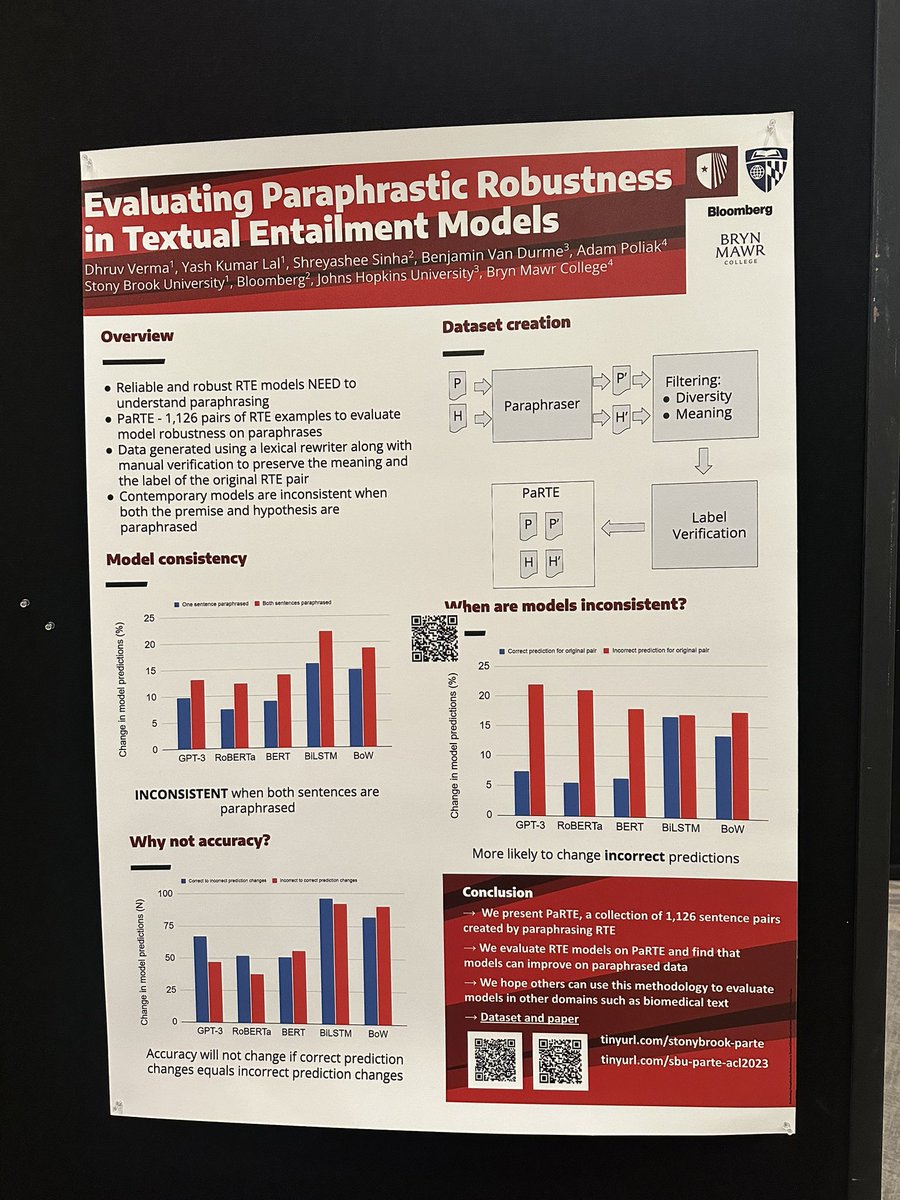
Current models are good at recognizing textual entailment (RTE). But if an RTE model has a sufficiently high capacity for reliable, robust inference necessary for NLU, then the model's predictions should be consistent across paraphrased examples. #NLProc (1/6)
Current models are good at recognizing textual entailment (RTE). But if an RTE model has a sufficiently high capacity for reliable, robust inference necessary for NLU, then the model's predictions should be consistent across paraphrased examples. #NLProc (1/6)
Current models are good at recognizing textual entailment (RTE). But if an RTE model has a sufficiently high capacity for reliable, robust inference necessary for NLU, then the model's predictions should be consistent across paraphrased examples. #NLProc (1/6)
@lal_yash @SinhaShreyashee @azpoliak @ben_vandurme @aclmeeting The paper can be found at arxiv.org/abs/2306.16722. The dataset can be found at tinyurl.com/stonybrook-par…. #ACL2023 #NLProc (6/6)

@lal_yash @SinhaShreyashee @azpoliak @ben_vandurme @aclmeeting The paper can be found at arxiv.org/abs/2306.16722. The dataset can be found at tinyurl.com/stonybrook-par…. #ACL2023 #NLProc (6/6)