diegodl retweetledi
diegodl
3.1K posts

diegodl
@diegodl
Datos, música y cualquier otra cosa. Director de Producto @TheBridge_Tech
Katılım Ocak 2008
937 Takip Edilen281 Takipçiler

diegodl retweetledi

> be Yann LeCun
> spend years building JEPA at Meta
> company focuses on LLaMA instead
> his idea stays complicated and unused
> robotics plans get dropped
> decides to leave and start AMI Labs
> builds a much simpler version from scratch
> trains it on normal hardware in just a few hours
> removes all the complicated tricks and keeps it simple
Results:
-uses 200x less data than similar systems
-makes decisions 50x faster
-runs on a single GPU instead of massive clusters
-simple to train
-understands movement, objects, and space
-can tell when something is physically impossible
-learns how the real world works without being explicitly taught.
Aakash Gupta@aakashgupta
Earlier this year Yann LeCun left Meta because Mark Zuckerberg wouldn't bet the company on JEPA. Last week his group dropped the first JEPA that actually trains end-to-end from raw pixels. 15 million parameters. Single GPU. A few hours. The timing is not a coincidence. For four years Meta has been the house that JEPA built. LeCun published the original paper from FAIR in 2022. I-JEPA and V-JEPA came out of his lab. The architecture was supposed to be the escape hatch from LLMs, the path to robots that actually learn physics instead of hallucinating about it. Every version shipped fragile. Stop-gradients. Exponential moving averages. Frozen pretrained encoders. Six or seven loss terms that had to be hand-tuned or the model collapsed into garbage representations. Meta kept funding LLMs. Llama shipped. Llama scaled. Llama got beat by Qwen and DeepSeek. Zuck spent $14 billion to buy ScaleAI and install Alexandr Wang. The FAIR robotics group was dissolved. LeCun's research kept winning papers and losing the product roadmap. He left, started AMI Labs, and said publicly that LLMs were a dead end. Now the paper. LeWorldModel. One regularizer replaces the entire pile of heuristics. Project the latent embeddings onto random directions, run a normality test, penalize deviation from Gaussian. The model cannot collapse because collapsed embeddings fail the test by construction. Hyperparameter search went from O(n^6) polynomial to O(log n) logarithmic. Six tunable knobs became one. The downstream numbers are what should scare the robotics capex class. 200 times fewer tokens per observation than DINO-WM. Planning time drops from 47 seconds to 0.98 seconds per cycle. 48x faster at matching or beating foundation-model performance on Push-T and 3D cube control. The latent space probes cleanly for agent position, block velocity, end-effector pose. It correctly flags physically impossible events as surprising. It learned physics without being told physics existed. Figure AI is valued at $39 billion. Tesla Optimus is mass-producing. World Labs raised $230 million to sell generative world models. Everyone in humanoid robotics is burning capital on foundation-model pipelines that plan in 47 seconds per cycle. LeCun's group just showed you can do it with 15 million parameters on a single GPU in a few hours. This is the Xerox PARC pattern running again. Meta had the next architecture. Meta had the scientist. Meta dissolved the robotics team, passed on the productization, and watched the exit. Three months later the lab that was supposed to be Meta's publishes the result that resets the robotics cost structure. The paper is worth more than Alexandr Wang.
English
diegodl retweetledi

Una genialidad en la TV británica, sobre cómo se toman sus vacaciones los ingleses en España
Español
@fenris1234 @lagamez Gracias por traer esta mierda a mi timeline. A veces deberíamos pensar si denunciando difundimos más
Español

Yo soy el hospital y empezaria a poner demandas a diestro y siniestro a toda esta panda de hijos de puta.
Jose Gomez Rial@gomez_rial5
Irresponsabilidad desde el desconocimiento, amplificada por el altavoz mediático de ser una supuesta influencer: así nacen bulos que erosionan la confianza en la donación de órganos y ponen en riesgo vidas. No todo vale.
Español
diegodl retweetledi

Llevo 12 años explicando la utilidad del molesto cambio estacional de la hora, primero desde @politikon_es después en periódicos y revistas científicas. Esta semana hablé para @eldebate_com y continué dando con la misma explicación. Aquí el resultado:
eldebate.com/ciencia/202603…
Español
Igual está semana los MCPs se vuelven a poner de moda.
Tobin South@TobinSouth
go build an interactive mcp app and dm me, we'll put it in claude
Español
diegodl retweetledi

Aunque hubieran escondido 1000€, el hecho de manipular el portal de transparencia debería ser un escándalo que haría dimitir a todo su gobierno.
Aquí no pasa nada, y por eso seguirán haciéndolo, e irá a más.
Arnau Borràs@arnaubor
1) Un particular crea subvencions.cat 2) Es descobreix què a Catalunya es destinen 5.000 milions anuals a subvencions (!) 3) La Generalitat inhabilita l'accés al portal de transparència durant 28 hores 4) Quan rehabilita l'accés, es descobreix que han eliminat 1 milió de registres, dificultant així que la ciutadania pugui fiscalitzar on van i a qui regalen els diners públics 5) Un exemple: Open Arms ha rebut uns 2'5 milions d'euros d'institucions públiques catalanes els últims anys. Al portal de transparència només n'apareixen uns 550.000. És una vergonya i han de donar explicacions. I que no ens prenguin el pèl parlant d'un "error tècnic".
Español
Esto empieza a tener mejor pinta
Satya Nadella@satyanadella
Announcing Copilot Cowork, a new way to complete tasks and get work done in M365. When you hand off a task to Cowork, it turns your request into a plan and executes it across your apps and files, grounded in your work data and operating within M365’s security and governance boundaries.
Español
diegodl retweetledi

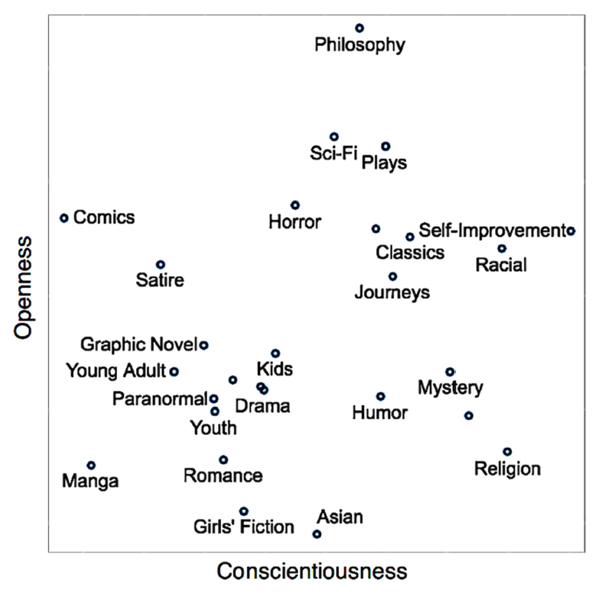
The books you love are a window into your personality.
•Mystery & self-improvement attract conscientious people
•Sci-fi, psychology, philosophy draw open-minded people
•Memoir & horror appeal to neurotic people
Reading doesn't just shape our views. It reveals what we're like.


English
diegodl retweetledi

Hace año y medio. Recuerdo que en una entrevista me preguntaron. ¿Cuánto tiempo crees que tardará la IA en cambiar cómo vivimos? Y respondí de 10 a 15 años.
La reacción fue un poco de estupefacción, porque viniendo de mí seguro que esperaban otra respuesta.
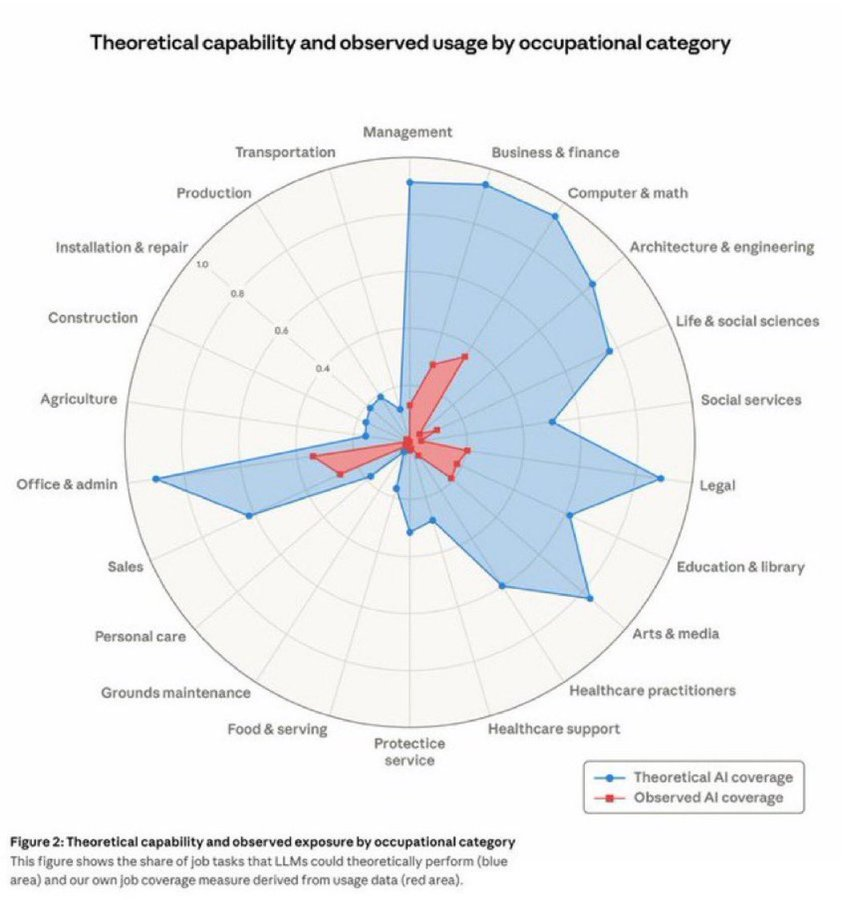
Pero la razón de mi respuesta no radicaba en la tecnología (la IA me parece maravillosa). Mi conclusión se basaba en lo que muestra este gráfico de una publicación de Anthropic.
Las previsiones optimistas siempre se hacen en base a lo que la IA potencialmente puede hacer (área azul), no en cómo realmente se usa (área roja).
Ese proceso de adopción es muchísimo más lento y progresivo.
El cuello de botella hace tiempo que somos nosotros.
Español
diegodl retweetledi

Hay gente muy muy sectaria que dice que es imposible que existan buenas personas de derechas (o de izquierdas). Para todos ellos esta magnífica columna de Manuel Vicent en El País.

Español
diegodl retweetledi

Prediction: In the AI age, taste will become even more important. When anyone can make anything, the big differentiator is what you choose to make.
paulgraham.com/taste.html
English
diegodl retweetledi

diegodl retweetledi

Cheap models are extremely under-rated!
These models will automate routine tasks and will play a key role in achieveing
Best cheap / small models in the world today
Gemini Flash 3 - excellent price for performance
Kimi K2.5 - very good on benchmarks
Haiku 4.5 - faster and better than Flash
GPT 5 nano - insanely fast, great for a classifier
Qwen family - great for fine-tuning
English
El nivel de cuento cosas, pero no del todo de la @La_SER es lamentable. La noticia del maquinista, ahora esto. Nos merecemos que la radio más escuchada del país y de la que yo soy oyente eleve el nivel, porque encima les escucharemos dando clases sobre bulos. Muy triste
Cadena SER@La_SER
🔴 Renfe comunicó a Emergencias la existencia de heridos en el tren Alvia a las 20:00 horas el día del accidente de Adamuz La SER publica en exclusiva el audio de la conversación entre la trabajadora de Renfe y el Centro de Coordinación de Emergencias cadenaser.com/nacional/2026/…
Español
diegodl retweetledi

Es usted el gobierno de España y tiene 1371 millones para gastar en transporte. Su red ferroviaria y de carreteras se cae en pedazos. Qué decide:
- Invertir los 1371 m. en mantenimiento de las infraestructuras.
- Comprar votos subvencionando un bono de transporte a 60 euros.


Español