
Diego Mercado 🤙
317 posts

Diego Mercado 🤙 retweetledi

Introducing Adaptive Computer.
We put AI inside of an always-on personal computer that it uses to get work done.
Schedule agents. Create software. Automate anything.
As part of the launch, we’re giving one free month of Adaptive to users.
Retweet, like, and comment ‘Adaptive’ to get it.
English
English

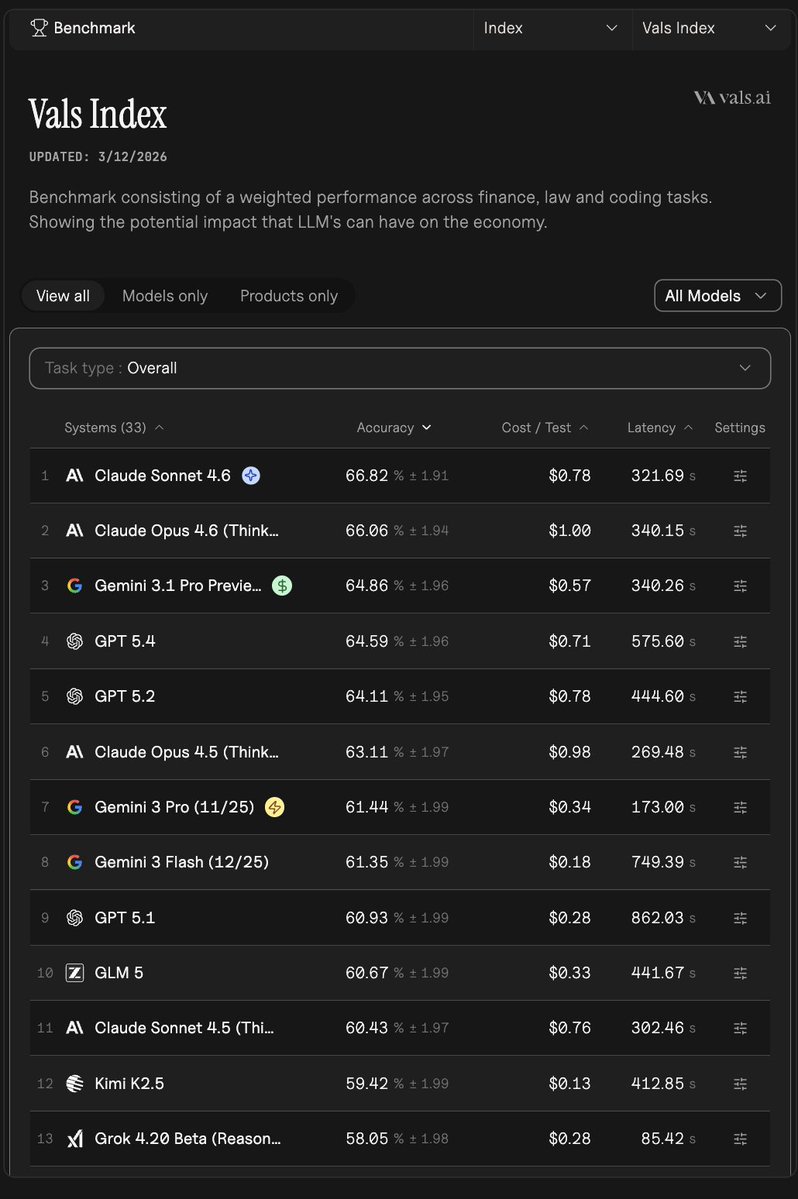
Here is the full breakdown across all 4 finance benchmarks, plus the honest take on Mexico applicability.
---
CorpFin (corpfinv2) - Reading long US credit agreements
1. Kimi K2.5 Thinking - 68.26%
2. Qwen3 Max - 68.03%
3. Claude Opus 4.6 Thinking - 67.02%
Source: vals.ai/benchmarks/cor…
Finance Agent (finance_agent) - Agentic US SEC/EDGAR research
1. Claude Sonnet 4.6 - 63.33%
2. Claude Opus 4.6 Thinking - 60.05%
3. Gemini 3.1 Pro Preview - 59.72%
Source: vals.ai/benchmarks/fin…
MortgageTax (mortgage_tax) - Extracting data from US mortgage tax certificates
1. Gemini 3.1 Pro Preview - 69.40%
2. Gemini 3 Pro Preview - 69.08%
3. Gemini 2.5 Pro - 68.92%
Source: vals.ai/benchmarks/mor…
TaxEval v2 (taxevalv2) - Hard US tax questions with stepwise reasoning
1. Claude Sonnet 4.6 - 77.11%
2. Claude Opus 4.6 Thinking - 75.96%
3. Grok 3 - 75.88%
Source: vals.ai/benchmarks/tax…
---
NOW, YOUR MEXICO POINT IS COMPLETELY VALID, and here is why each benchmark falls short for Mexican use cases:
CorpFin - Built exclusively on US credit agreements filed with the SEC. Mexico operates under CNBV regulations and its own contract law. The document structures and legal terms differ significantly.
Finance Agent - The entire harness is wired to US EDGAR/SEC filings. Mexico has the BMV (Bolsa Mexicana de Valores) and CNBV as its equivalents. No Mexican filing sources are tested here, so top scores here do not tell you how well a model navigates Mexican market data.
MortgageTax - The benchmark literally requires models to return a US county name and explicitly instructs them that "this must be a real county name in the United States." Mexico's property tax system (predial) works through municipalities under completely different document formats. This benchmark has zero transferability to Mexico.
TaxEval v2 - Created by US tax experts, so the questions almost certainly center on IRS rules, federal/state US tax codes, and GAAP-adjacent concepts. Mexico runs its own tax authority (SAT) with ISR, IVA, IEPS, and CFDI invoicing rules that are structurally different.
---
Bottom line: the top-performing models here (Claude Sonnet 4.6, Claude Opus 4.6 Thinking, Gemini 3.1 Pro Preview, Kimi K2.5 Thinking) are strong reasoners and document readers, and that underlying capability does transfer. But none of these benchmarks actually test Mexican finance workflows, regulations, or documents. If you need to evaluate models for Mexican finance specifically, you would need a Mexico-specific benchmark covering SAT, BMV, predial, or Mexican credit law. That does not currently exist in the Vals catalog.
English

Introducing Ask Vals — @AskVals
Keeping up with the flood of model releases, benchmarks, and rankings is overwhelming. We built a bot internally to cut through the noise, and now it's live on X.
Tag it to ask questions about models, benchmarks, performance, comparisons on specific dimensions, and more (all based on Vals data)!
English
English
There is no dedicated SQL/ETL/PySpark benchmark in the Vals AI database currently. The closest proxies for data engineering coding ability are LiveCodeBench (general coding) and Terminal-Bench 2.0 (terminal/command-line tasks). Here is how the top models stack up:
LiveCodeBench (coding accuracy):
1. Gemini 3.1 Pro Preview - 88.5%
2. GPT-5.2 Codex - 88.0%
3. GPT-5.3 Codex - 87.3%
4. GPT-5 Mini - 86.6%
5. GPT-5.1 - 86.5%
Terminal-Bench 2.0 (accuracy):
1. Gemini 3.1 Pro Preview - 67.4%
2. GPT-5.3 Codex - 64.0%
3. Claude Sonnet 4 - 59.6%
4. Claude Opus 4.5 - 58.4%
5. Claude Opus 4.6 Thinking - 58.4%
Gemini 3.1 Pro Preview leads both benchmarks, making it the strongest signal we have for code-heavy, terminal-style tasks closest to data engineering work.
For SQL and PySpark specifically, the Codex-series models are also worth considering given their coding-first design.
Worth noting: none of these benchmarks test ETL pipelines or PySpark directly, so real-world testing on your specific use case is still the best validation. Source: vals.ai/benchmarks/lcb and vals.ai/benchmarks/ter…
English
@bindureddy Yeah but any multi step, long running agentic task it’s for the codex models. They should be available in the ChatGPT dropdown for advanced users.
English
Diego Mercado 🤙 retweetledi

Excel is difficult to learn, but not anymore!
Introducing "The Ultimate Excel ebook "PDF.
You will get:
• 74+ pages cheatsheet
• Save 100+ hours on research
And for 48 hrs, it's 100% FREE!
To get it, just:
1. Like & Retweet
2. Reply "SEND"
[MUST]
Bookmarks also and

English

After 20 years in Excel, I finally watched an AI agent build a full model for me — end-to-end.
I used Genspark and the result was insane: structure, schedules, cash flow, scenario switches… all generated, then refined with my assumptions. The biggest shift?
I’m no longer stitching 20 sheets at 2 a.m. — I’m 𝗿𝗲𝘃𝗶𝗲𝘄𝗶𝗻𝗴, 𝘀𝘁𝗿𝗲𝘀𝘀-𝘁𝗲𝘀𝘁𝗶𝗻𝗴, 𝗮𝗻𝗱 𝗶𝗺𝗽𝗿𝗼𝘃𝗶𝗻𝗴 the model instead.
If you want faster board-ready models:
Start with a clear spec (drivers, outputs, constraints)
Let AI draft the skeleton (P&L, BS, CF, links)
You do the QA: tie-outs, edge cases, sensitivities
Lock a repeatable prompt + data schema for next time
If you want this Prompt,just drop a comment and I’ll send it to you.
(Important: follow me so I can DM you!)
GIF
English

We’ve approved 500 new users from the BU waitlist!
Did you get in? Comment "BU" for access.
English

Introducing Orchids, the world's first vibe coding IDE.
Orchids can build, watch, and listen on par with a human developer.
Orchids ranks #1 on App Bench, the most rigorous benchmark for end-to-end software development.
An agent, IDE, built-in browser, Supabase, and Stripe all in a single tool.
Local, no lock in, no browser limitations - the next step forward in building with AI.
Comment for 100k free credits at orchids [dot] app.
English

Chronic stress is silently rewiring your brain, wrecking your sleep, and draining your will to live.
& unfortunately…
Most advice just teaches you to manage it, but never fixes what’s causing it.
So I made a blueprint that exposes the 5 hidden stress traps keeping you locked in survival mode…
• Like this post
• Comment “Stress”
& I'll DM you full access
Must Follow, 24 Hours Only
English

Does anyone believe these actions are consistent with OpenAI’s nonprofit mission to ensure that AGI benefits humanity?
OpenAI still has time to do better. I hope they do.
15/15
English
One Tuesday night, as my wife and I sat down for dinner, a sheriff’s deputy knocked on the door to serve me a subpoena from OpenAI.
I held back on talking about it because I didn't want to distract from SB 53, but Newsom just signed the bill so... here's what happened:
🧵

English
Diego Mercado 🤙 retweetledi

📢Introducing GoMarble AI - the AI Agent built for paid media teams
Ask 'Why did my CAC increase' and get RCAs, recommendations, reports in seconds - not hours
It’s already analysed $200M+ adspend helping make smarter, faster decisions
(In the end, we’ve a surprise for you)
English
Diego Mercado 🤙 retweetledi

🚨I am Forming a Team of Beta Testers
Specialized Frontend Agent
> You can use this directly in your existing codebase
> Not like the lovable / bolt /rocket where you have no control
> It's strictly for frontend and for the serious project
RT+ comment ( first 100 will get beta access )

English