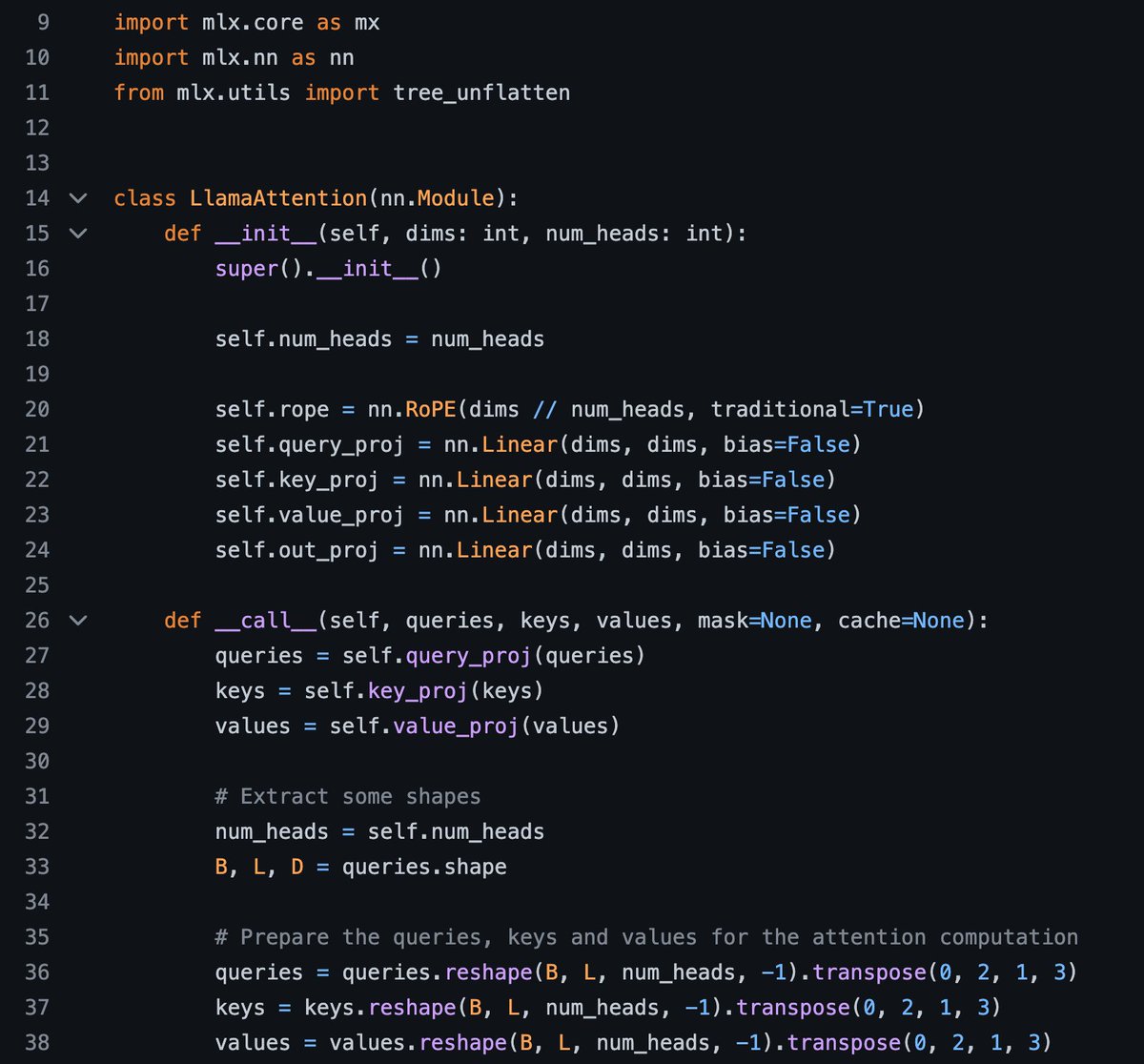
Dmitri retweetledi

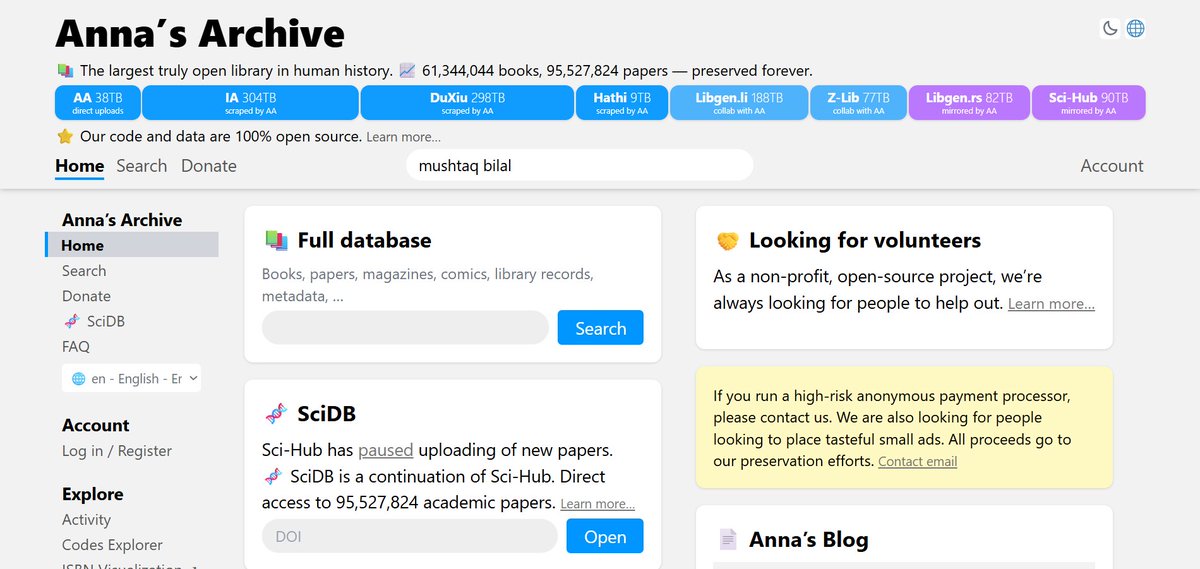
🚨Don't use Anna's Archive — it's pirate website with 61M+ books and 95M+ research papers freely available.
We should all try to make billion-dollar academic publishers richer.
English
Dmitri
165 posts

















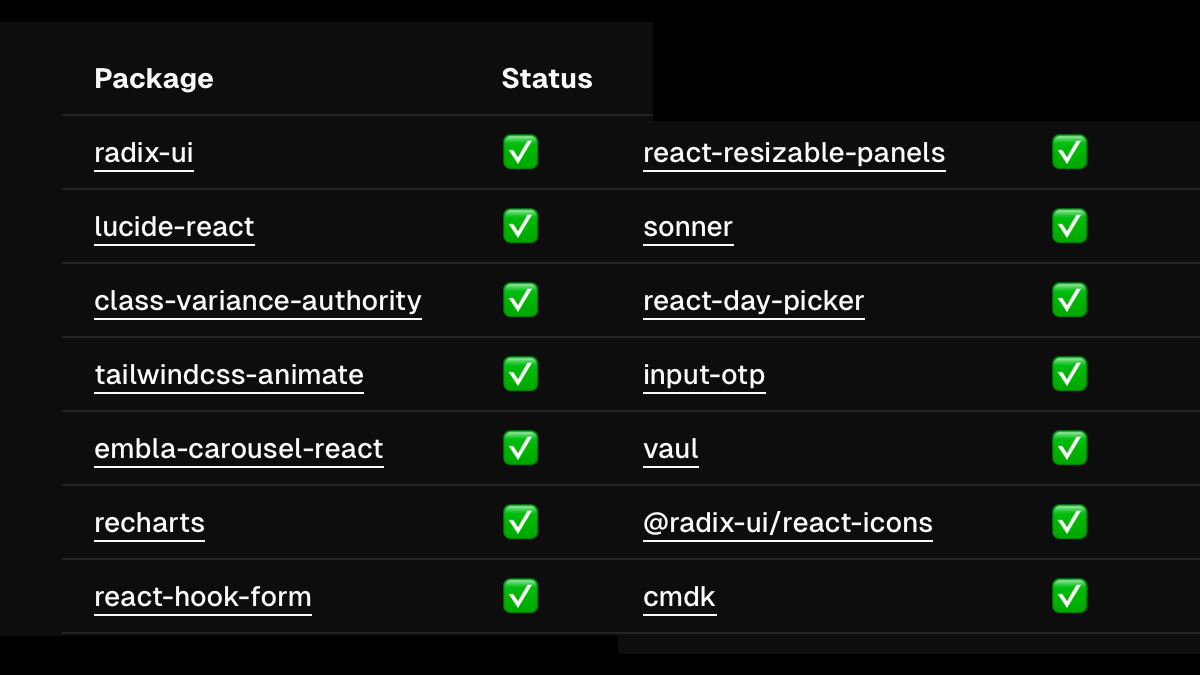
An update on Next.js 15 and React 19 1/5 - I published a guide on how to use shadcn/ui with React 19: ui.shadcn.com/docs/react-19 - it covers the peer deps issue & how to resolve. - how to use recharts with React 19 - upgrade status of dependencies - and more ⬇️

Today we're launching Y-Sweet on Jamsocket! Y-Sweet is a Yjs sync server + document store that makes building realtime applications like Google Docs easy. jamsocket.com/y-sweet