
Deepak Gupta
102 posts

Deepak Gupta
@dk_gup
Deep Learning Researcher, Current - AIQ & IIT Dhanbad, Ex-UniAmsterdam, Ex-ShellResearch, PhD@TUDelft
Abu Dhabi, UAE Katılım Temmuz 2016
283 Takip Edilen168 Takipçiler

If you are an AI startup blocked on GPUs, send me a note.
At Lamini, we figured out how to use AMD GPUs, which gives us a relatively large supply compared to the rest of the market.
English
With LLMs and LVMs changing the landscape of deep learning, computational efficiency is going to be critically important from a practical perspective and @Nyun_AI_ is determined to tackle this hard challenge.
Nyun AI@Nyun_AI_
Say hello to Nyun Zero 💡- where AI meets efficiency! Reduce inference costs, speed up training, and secure your data like never before. 🛡️ Join the revolution in AI productivity. #EfficientAI #DeepLearning 🚀 Sign up here ➡️ [forms.office.com/r/NxYwkmGypG]
English
Deepak Gupta retweetledi

Say hello to Nyun Zero 💡- where AI meets efficiency! Reduce inference costs, speed up training, and secure your data like never before. 🛡️ Join the revolution in AI productivity. #EfficientAI #DeepLearning 🚀 Sign up here ➡️ [forms.office.com/r/NxYwkmGypG]
English
Amazing work on quantized generative models at our RCV workshop in #ICCV2023.
Markus Nagel@mnagel87
Softmax Bias Correction for Quantized Generative Models Nilesh Prasad Pandey, @mfournarakis, Chirag Patel, Markus Nagel arxiv.org/abs/2309.01729 RCV workshop, Monday 2nd @ 14:50 (oral presentation, room S04)
English
@fooobar We will also have our OpenAI soon :) We are moving with some lag, but the sentiments are the same.
English

Europe: Let's create an OpenAI of Europe with 100+M USD funding.
India: Let's get our coke can sooner with 200M USD funding.
That's the tweet :(
English
Our GLoRA fine-tuned LLaMA-7B now leads as SOTA fine-tuning technique on the Stanford-Alpaca dataset, outperforming even Falcon-7B, using only an open-source model and dataset.
New SOTA LLM to follow soon!
Link: github.com/Arnav0400/ViT-…
#LLM #lora #Efficiency #largemodels
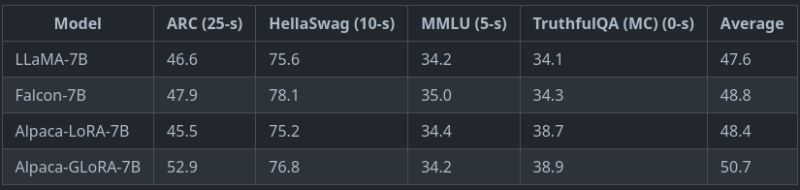
English
Originating from a unified mathematical formulation, GLoRA exhibits strong transfer learning, few-shot learning and domain generalization abilities, as it adjusts to new tasks through additional dimensions on weights and activations.
English
Enhancing Low-Rank Adaptation (LoRA), GLoRA employs a generalized prompt module to optimize pre-trained model weights and adjust intermediate activations, providing more flexibility and capability across diverse tasks and datasets.
English
As part of our effort towards making deep learning more efficient, I am excited to announce our new work "One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning".
See paper here: arxiv.org/abs//2306.07967
English
Glad to share our new preprint on awesome finetuning of large models.
AK@_akhaliq
One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning paper page: huggingface.co/papers/2306.07… present Generalized LoRA (GLoRA), an advanced approach for universal parameter-efficient fine-tuning tasks. Enhancing Low-Rank Adaptation (LoRA), GLoRA employs a generalized prompt module to optimize pre-trained model weights and adjust intermediate activations, providing more flexibility and capability across diverse tasks and datasets. Moreover, GLoRA facilitates efficient parameter adaptation by employing a scalable, modular, layer-wise structure search that learns individual adapter of each layer. Originating from a unified mathematical formulation, GLoRA exhibits strong transfer learning, few-shot learning and domain generalization abilities, as it adjusts to new tasks through additional dimensions on weights and activations. Comprehensive experiments demonstrate that GLoRA outperforms all previous methods in natural, specialized, and structured benchmarks, achieving superior accuracy with fewer parameters and computations on various datasets. Furthermore, our structural re-parameterization design ensures that GLoRA incurs no extra inference cost, rendering it a practical solution for resource-limited applications.
English
Deepak Gupta retweetledi

One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning
paper page: huggingface.co/papers/2306.07…
present Generalized LoRA (GLoRA), an advanced approach for universal parameter-efficient fine-tuning tasks. Enhancing Low-Rank Adaptation (LoRA), GLoRA employs a generalized prompt module to optimize pre-trained model weights and adjust intermediate activations, providing more flexibility and capability across diverse tasks and datasets. Moreover, GLoRA facilitates efficient parameter adaptation by employing a scalable, modular, layer-wise structure search that learns individual adapter of each layer. Originating from a unified mathematical formulation, GLoRA exhibits strong transfer learning, few-shot learning and domain generalization abilities, as it adjusts to new tasks through additional dimensions on weights and activations. Comprehensive experiments demonstrate that GLoRA outperforms all previous methods in natural, specialized, and structured benchmarks, achieving superior accuracy with fewer parameters and computations on various datasets. Furthermore, our structural re-parameterization design ensures that GLoRA incurs no extra inference cost, rendering it a practical solution for resource-limited applications.

English
For more details, see sites.google.com/view/rcv2023/c…
#energyefficiency #modelcompression #Sustainability
@PrasadDilip @tiwarishabh16 @UdbhavBamba @devanshuarya @rajatthomas @KinasRemek
English
Call for papers is now open for @ICCVConference 2023 workshop on Resource Efficient Deep Learning (RCV'23). If you are passionate about reducing energy consumption of large DL models and make them run super fast on low power devices, please consider submitting your works.
English
Deepak Gupta retweetledi

Happy to share our new publication and my first first-author paper, "Data-Efficient Training of CNNs and Transformers with Coresets: A Stability Perspective." Work done with Irtiza Hassan, @PrasadDilip and @dk_gup. arxiv.org/abs/2303.02095
Code: github.com/transmuteai/da…
English
I am especially excited about this work since it opens doors for better processing of large-scale images from medical, space science and earth science domains, among others, and that too in an end-to-end manner.
@egavves @cgmsnoek @vkhetan_iit @KinasRemek @devanshuarya
English
I am happy to release our work "Patch Gradient Descent: Training Neural Networks on Very Large Images",
a method that allows to train existing neural networks on images of very large size without the need to struggle with GPU memory bottleneck.
See here: arxiv.org/abs/2301.13817
English
With no bells and whistles, this approach can be used with any existing architecture and can operate with even very small GPU memory. In simple words, it is a direction towards making CNNs almost invariant to image size.
English