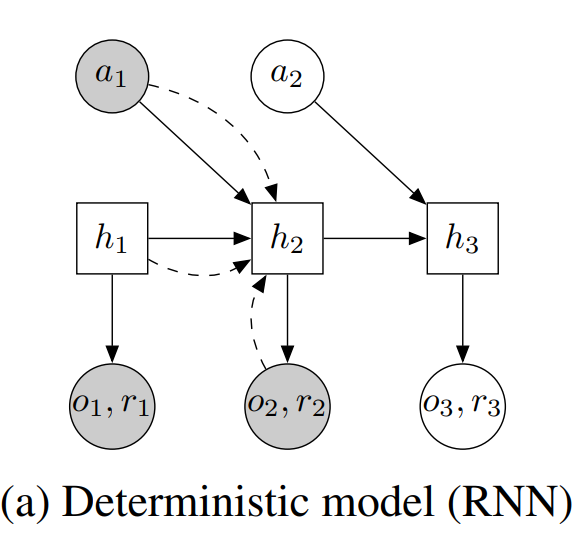
In this post I want to turn our attention to two applications of Bellman’s work: continuous-time reinforcement learning, and how the training of generative models (diffusion models) can be interpreted through stochastic optimal control
Link to post: dani2442.github.io/posts/continuo…
(4/4)
English