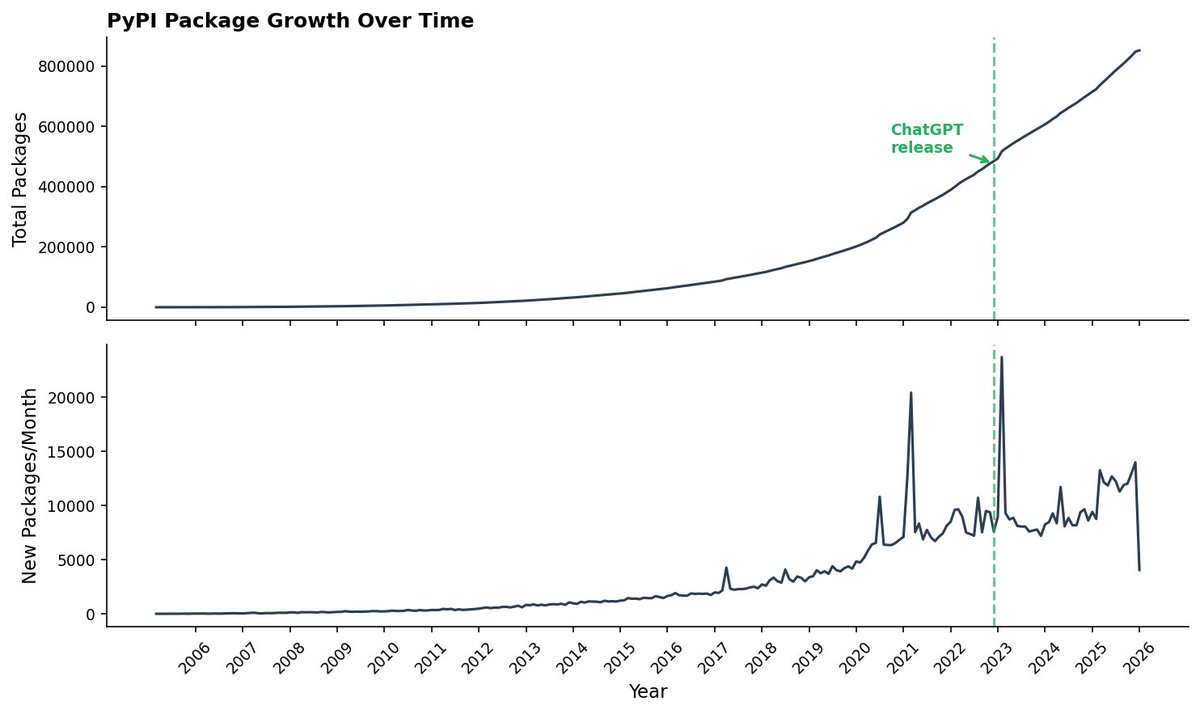
Information from Documents retweetledi

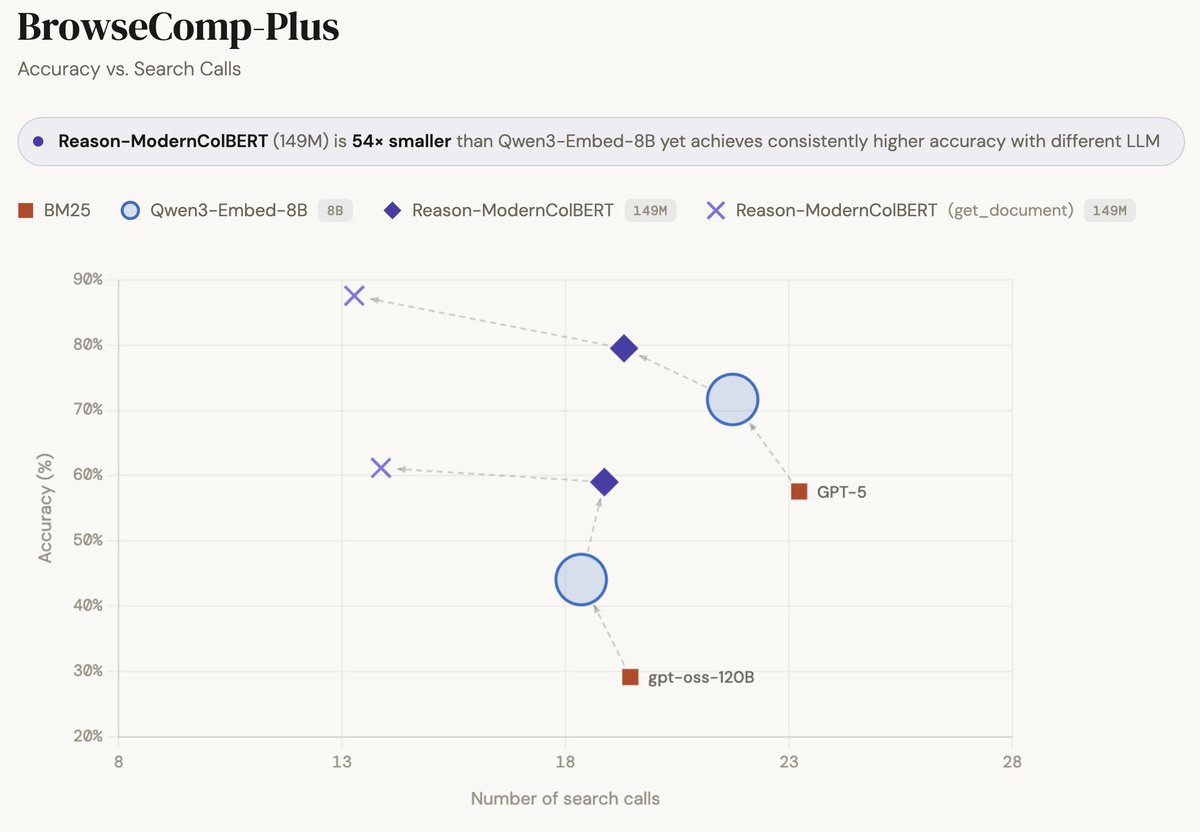
BrowseComp-Plus, perhaps the hardest popular deep research task, is now solved at nearly 90%...
... and all it took was a 150M model ✨
Thrilled to announce that Reason-ModernColBERT did it again and outperform all models (including models 54× bigger) on all metrics
English