Sabitlenmiş Tweet
DK
244 posts


DK retweetledi

The latest 𝕏 algorithm has been published to GitHub
github.com/xai-org/x-algo…
English
DK retweetledi

DK retweetledi

Introducing Altara: the scientific intelligence platform for the physical world.
Today @evatuecke and I are excited to announce our $7M seed led by @GreylockVC, joined by @Neo, @BoxGroup, @Liquid2V, and angel investors including @JeffDean and leadership from OpenAI & AMD.
We’re already working with early customers in semiconductors, batteries, and advanced materials. More below.
English
DK retweetledi

I compressed the KV cache of my custom LLM by 6x using multi-head latent attention (MLA).
Feats:
- 6x smaller cache than fp32 MHA (768 KB vs 4.5 MB at 256 tokens)
- One 128-dimensional latent per token instead of full K, V vectors
- Weight absorption at load so attention runs entirely in latent space, eliminating up-projection during inference
Compare MHA vs MLA in your browser via our demo: mni-ml.github.io/demos/mla/

English


DK retweetledi

DK retweetledi

DK retweetledi

We're partnering with SpaceX to improve Composer.
cursor.com/blog/spacex-mo…
English

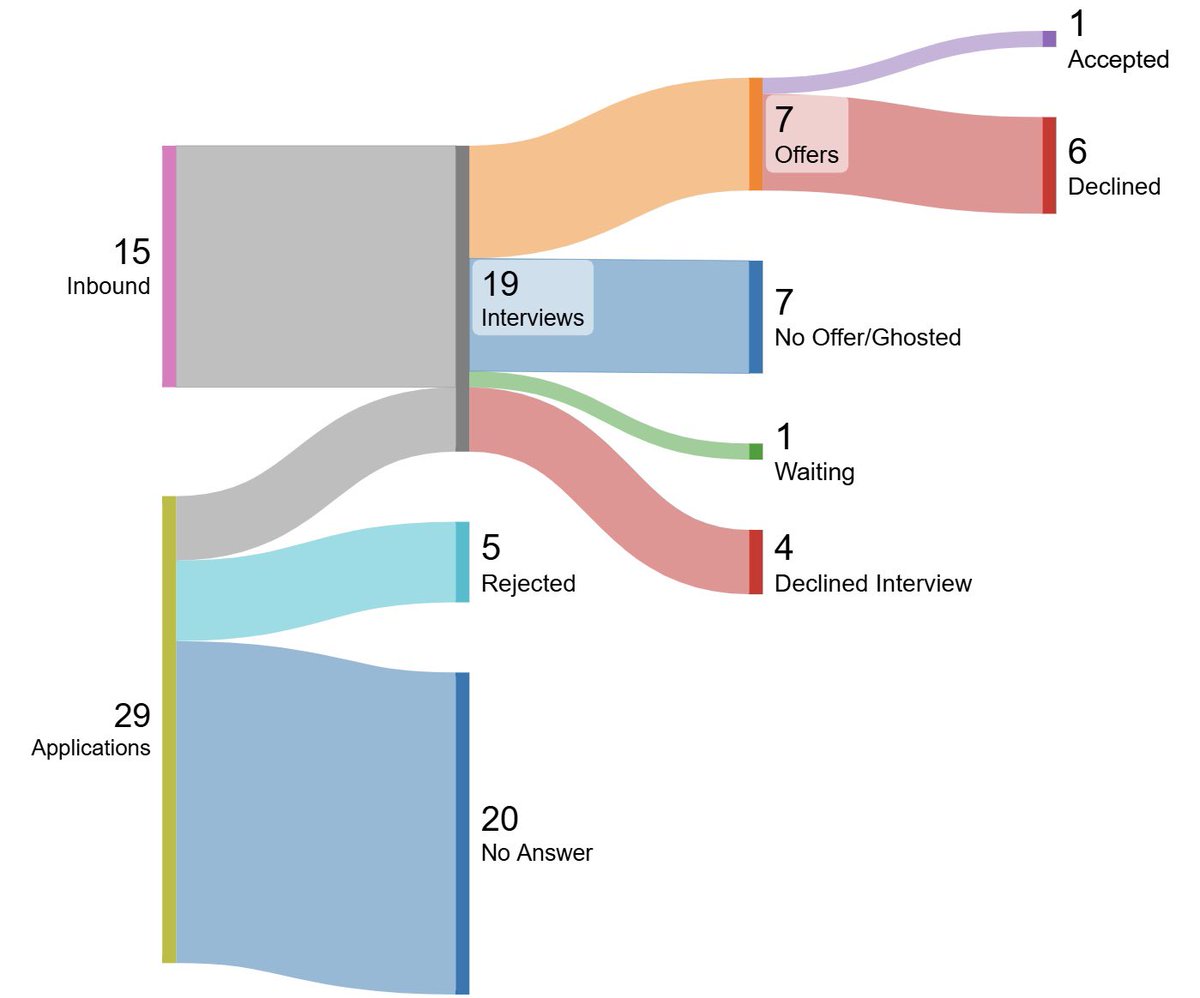
I have some life updates to share!
I'm finally done both recruiting and my first year at waterloo
I'll be moving to New York City this summer to work at @phoebe_work_ as a software engineering intern!
This past semester has been pretty grindy with balancing school, recruiting, and a part-time but it's been very rewarding
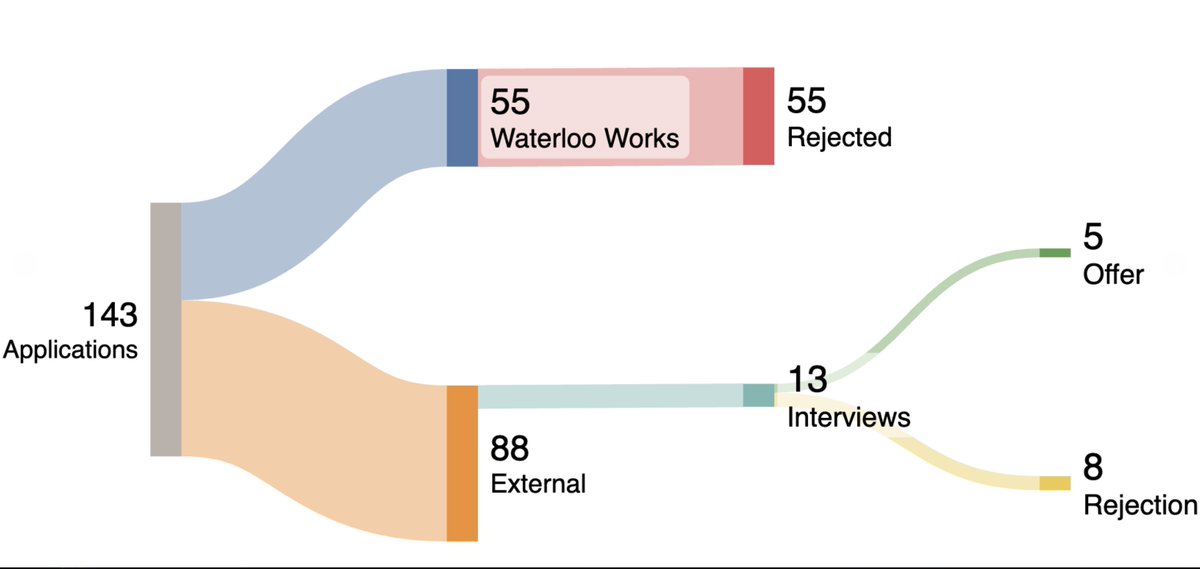
First co-op hunt has also been pretty difficult. Went 0/55 on waterlooworks and failed a lot of interviews (especially in the beginning of the cycle).
However, a lot of people have helped me out by warm introing, mock interviews, and much more, making this process a whole lot easier for me.
I have a lot of ppl to thank. For Phoebe specifically, I'm very grateful to @adiprasadd @shayaan_azeem for the intro, @jrwoodbridge for the quick and smooth hiring process, and fellow intern @casperdongg for helping me navigate with visas and more 🙏
It's been a good year and I'm excited for my next chapter. hmu if you're in nyc this summer!
English
DK retweetledi

I added KV caching and INT8 KV quantization to our transformer inference, improving throughput by 35x.
All of this was done from scratch in Rust + CUDA, on top of a homemade ML framework.
On a 4-token prompt with 252 generated tokens:
- Original: 0.76 tok/s
- KV cache fp32: 27.21 tok/s
- KV cache int8 (quantized): 27.29 tok/s
Try it out yourself here: mni-ml.github.io/demos/kv-cache/
In practice:
- KV caching gave us about a 35x end-to-end speedup
- INT8 KV cache kept roughly the same speed as fp32 but cut KV cache memory by 3.78x
FP32 cache used 4.5 MB in this run while the INT8 cache used only 1.19 MB
This simple change to inference created a huge impact on performance. To learn more about the KV cache and other optimizations like this, check out the blog at mni.ml!
English
- finished 2A
- stopped GPAmaxxing and started lifemaxxing
time to go to work
GIF
English
DK retweetledi
I integrated speculative decoding into the LLM I trained from scratch leading to 3x improvements in token throughput (demo + blog below).
This is just one of many inference optimizations we discuss in our latest blog post. Check it out if you want to learn about:
- The KV Cache
- Mixture of Experts
- Paged Attention
- Quantization
- and much more
Using an ML framework @_reesechong and I wrote in Rust + CUDA, we trained a smaller 2M parameter LLM that proposes draft tokens. These tokens can then be accepted together with just one forward pass of the larger model, decreasing inter-token latency.
You can now visualize speculative decoding in the link below, all running in your browser. Try it out and build your own ML projects with:
npm i @mni-ml/framework
Already sitting at 1600+ downloads!

English
DK retweetledi
Behind the scenes of mni-ml:
January 4th 2026 - my roommate @MankyDankyBanky and I wanted to do a big project together.
”maybe we should try to build pytorch from scratch”
We found @srush_nlp's minitorch curriculum and committed to grinding through it Jan to April.
February - autodiff and tensor internals done. lots of late night PR reviews, stacked diffs, Kinton ramen runs to Toronto when I'd visit Aadi at Shopify. We started posting on X to keep ourselves accountable.
March - the month of parallelization: Aadi shipped tiled matmul using the same algo @nvidia teaches in their CUDA guide, wrapped by end of month - pooling, conv1d/2d forward+backward, softmax, dropout.
March 22-23 — @socraticainfo symposium & we see the tinytpu team on the stage which filled us with determination 🫡 cc: @evanliin @XanderChin @suryasure05 @kennykgguo
March 24 - chose the mni-ml brand and started the educational blog
March 30 - minitorch is DONE ahead of schedule. now we build on top of the framework.
April 5-6 - cuBLAS matmul via koffi FFI. buffer pooling, strided batched GEMM, kernel optimizations. CUDA backend takes shape.
April 7 - huge day. cross-platform CI pipeline, prebuilt npm binaries, v0.3.0 — CUDA live on @npmjs. flatten the monorepo, add @WebGPU + Windows CUDA build targets by eod.
April 12 - flash attention CUDA kernel ships. we caught a bug where head dim > 32 was truncating.
April 14 (during exam season), we recorded the demo in @Shopify recording studio during Aadi’s lunch break. Everything over the last 4mo finally came together. Cc: @fnthawar @tobi @alspee
April 17: launch post and bought the domain mni.ml and we’re just getting started. We have so much in store for this summer, stay tuned 🫡
cc: @sundeep @GavinSherry

Aadi Kulshrestha@MankyDankyBanky
I trained a 12M parameter LLM on my own ML framework using a Rust backend and CUDA kernels for flash attention, AdamW, and more. Wrote the full transformer architecture, and BPE tokenizer from scratch. The framework features: - Custom CUDA kernels (Flash Attention, fused LayerNorm, fused GELU) for 3x increased throughput - Automatic WebGPU fallback for non-NVIDIA devices - TypeScript API with Rust compute backend - One npm install to get started, prebuilt binaries for every platform Try out the model for yourself: mni-ml.github.io/demos/transfor… Built with @_reesechong. Check out the repos and blog if you want to learn more. Shoutout to @modal for the compute credits allowing me to train on 2 A100 GPUs without going broke cc @sundeep @GavinSherry
English
DK retweetledi
I trained a 12M parameter LLM on my own ML framework using a Rust backend and CUDA kernels for flash attention, AdamW, and more.
Wrote the full transformer architecture, and BPE tokenizer from scratch.
The framework features:
- Custom CUDA kernels (Flash Attention, fused LayerNorm, fused GELU) for 3x increased throughput
- Automatic WebGPU fallback for non-NVIDIA devices
- TypeScript API with Rust compute backend
- One npm install to get started, prebuilt binaries for every platform
Try out the model for yourself: mni-ml.github.io/demos/transfor…
Built with @_reesechong. Check out the repos and blog if you want to learn more.
Shoutout to @modal for the compute credits allowing me to train on 2 A100 GPUs without going broke
cc @sundeep @GavinSherry
English