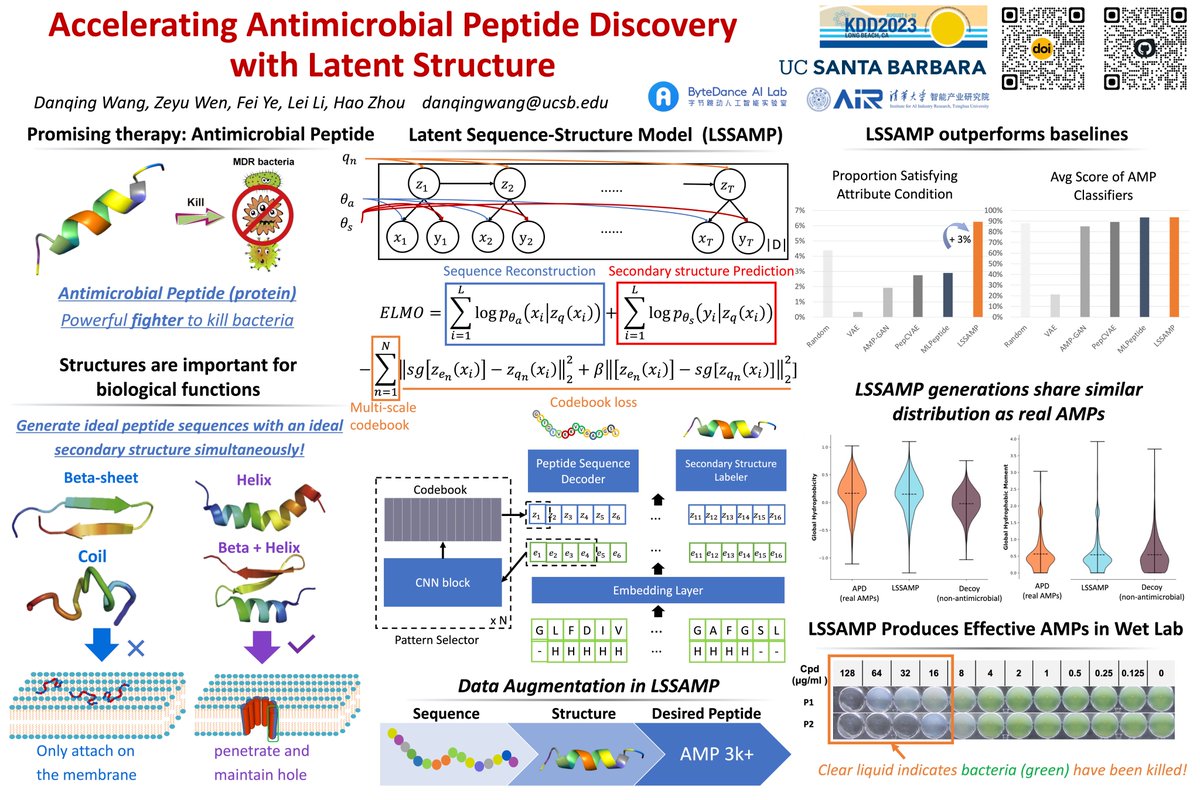
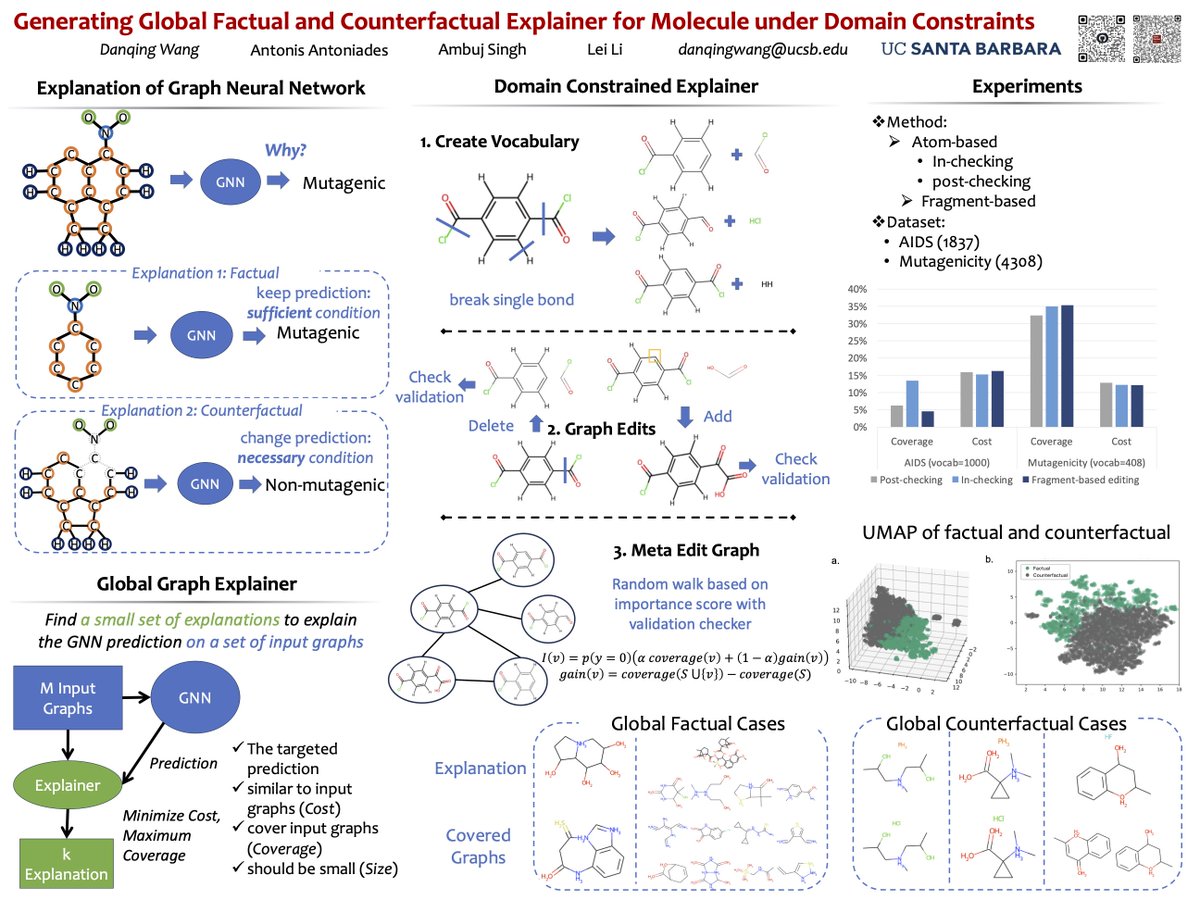
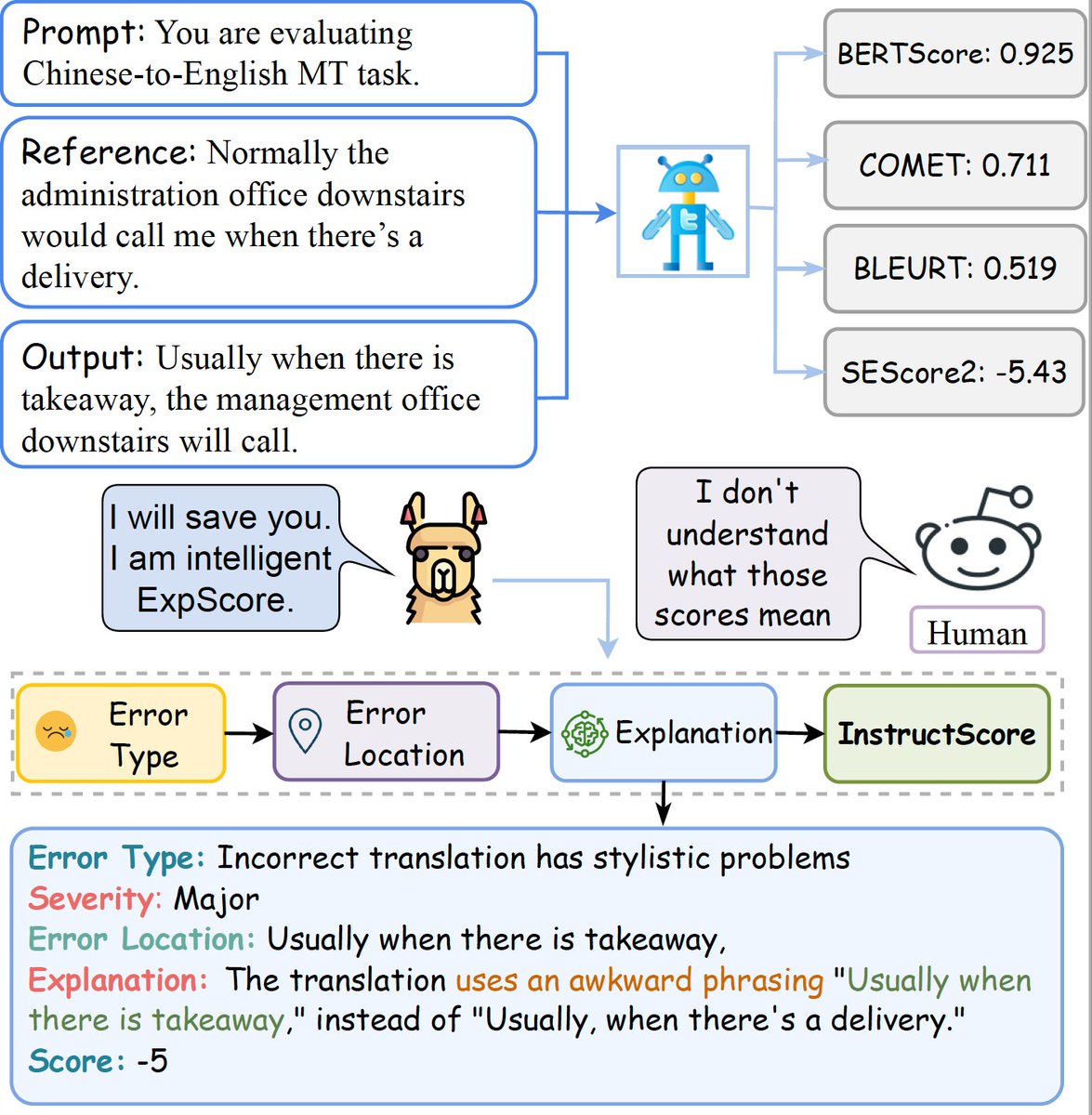
Danqing Wang retweetledi

Everyone talks about scaling inference compute after o1. But how exactly should we do that? We studied compute allocation for sampling -- a basic operation in most LLM meta-generators, and found that optimized allocation can save as much as 128x compute!
arxiv.org/abs/2410.22480
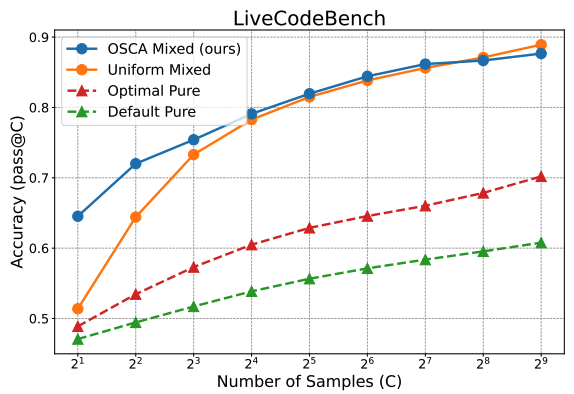


English