
datasync
3.4K posts
datasync
@dropair001
nothing I post is financial advice.
Katılım Nisan 2024
448 Takip Edilen84 Takipçiler

MIT Search gig project in the memory layer if it becomes seriously huge and impacts tokens.
But I don't think normal people need it. Just tell Claude to use python script if it needs to probe memento deeper.
x.com/iam_elias1/sta…
Elias Al@iam_elias1
MIT just made every AI company's billion dollar bet look embarrassing. They solved AI memory. Not by building a bigger brain. By teaching it how to read. The paper dropped on December 31, 2025. Three MIT CSAIL researchers. One idea so obvious it hurts. And a result that makes five years of context window arms racing look like the wrong war entirely. Here is the problem nobody solved. Every AI model on the planet has a hard ceiling. A context window. The maximum amount of text it can hold in working memory at once. Cross that line and something ugly happens — something researchers have a clinical name for. Context rot. The more you pack into an AI's context, the worse it performs on everything already inside it. Facts blur. Information buried in the middle vanishes. The model does not become more capable as you feed it more. It becomes more confused. You give it your entire codebase and it forgets what it read three files ago. You hand it a 500-page legal document and it loses the clause from page 12 by the time it reaches page 400. So the industry built a workaround. RAG. Retrieval Augmented Generation. Chop the document into chunks. Store them in a database. Retrieve the relevant ones when needed. It was always a compromise dressed up as a solution. The retriever guesses which chunks matter before the AI has read anything. If it guesses wrong — and it does, constantly — the AI never sees the information it needed. The act of chunking destroys every relationship between distant paragraphs. The full picture gets shredded into fragments that the AI then tries to reassemble blindfolded. Two bad options. One broken industry. Three MIT researchers and a deadline of December 31st. Here is what they built. Stop putting the document in the AI's memory at all. That is the entire idea. That is the breakthrough. Store the document as a Python variable outside the AI's context window entirely. Tell the AI the variable exists and how big it is. Then get out of the way. When you ask a question, the AI does not try to remember anything. It behaves like a human expert dropped into a library with a computer. It writes code. It searches the document with regular expressions. It slices to the exact section it needs. It scans the structure. It navigates. It finds precisely what is relevant and pulls only that into its active window. Then it does something that makes this recursive. When the AI finds relevant material, it spawns smaller sub-AI instances to read and analyze those sections in parallel. Each one focused. Each one fast. Each one reporting back. The root AI synthesizes everything and produces an answer. No summarization. No deletion. No information loss. No decay. Every byte of the original document remains intact, accessible, and queryable for as long as you need it. Now here are the numbers. Standard frontier models on the hardest long-context reasoning benchmarks: scores near zero. Complete collapse. GPT-5 on a benchmark requiring it to track complex code history beyond 75,000 tokens — could not solve even 10% of problems. RLMs on the same benchmarks: solved them. Dramatically. Double-digit percentage gains over every alternative approach. Successfully handling inputs up to 10 million tokens — 100 times beyond a model's native context window. Cost per query: comparable to or cheaper than standard massive context calls. Read that again. One hundred times the context. Better answers. Same price. The timeline of the arms race makes this sting harder. GPT-3 in 2020: 4,000 tokens. GPT-4: 32,000. Claude 3: 200,000. Gemini: 1 million. Gemini 2: 2 million. Every generation, every company, billions of dollars spent, all betting on the same assumption. More context equals better performance. MIT just proved that assumption was wrong the entire time. Not slightly wrong. Fundamentally wrong. The entire premise of the last five years of context window research — that the solution to AI memory was a bigger window — was the wrong answer to the wrong question. The right question was never how much can you force an AI to hold in its head. It was whether you could teach an AI to know where to look. A human expert handed a 10,000-page archive does not read all 10,000 pages before answering your question. They navigate. They search. They find the relevant section, read it deeply, and synthesize the answer. RLMs are the first AI architecture that works the same way. The code is open source. On GitHub right now. Free. No license fees. No API costs. Drop it in as a replacement for your existing LLM API calls and your application does not even notice the difference — except that it suddenly works on inputs it used to fail on entirely. Prime Intellect — one of the leading AI research labs in the space — has already called RLMs a major research focus and described what comes next: teaching models to manage their own context through reinforcement learning, enabling agents to solve tasks spanning not hours, but weeks and months. The context window wars are over. MIT won them by walking away from the battlefield. Source: Zhang, Kraska, Khattab · MIT CSAIL · arXiv:2512.24601 Paper: arxiv.org/abs/2512.24601 GitHub: github.com/alexzhang13/rlm
English
datasync retweetledi

@toly will you support us ?
It's the next runner #unemployed
Check the Tiktok @chanisaslay" target="_blank" rel="nofollow noopener">tiktok.com/@chanisaslay
Ca: Ut8Jo7PsWLLZ4qJszbj4YXU3MqgAcycgzVReihTpump
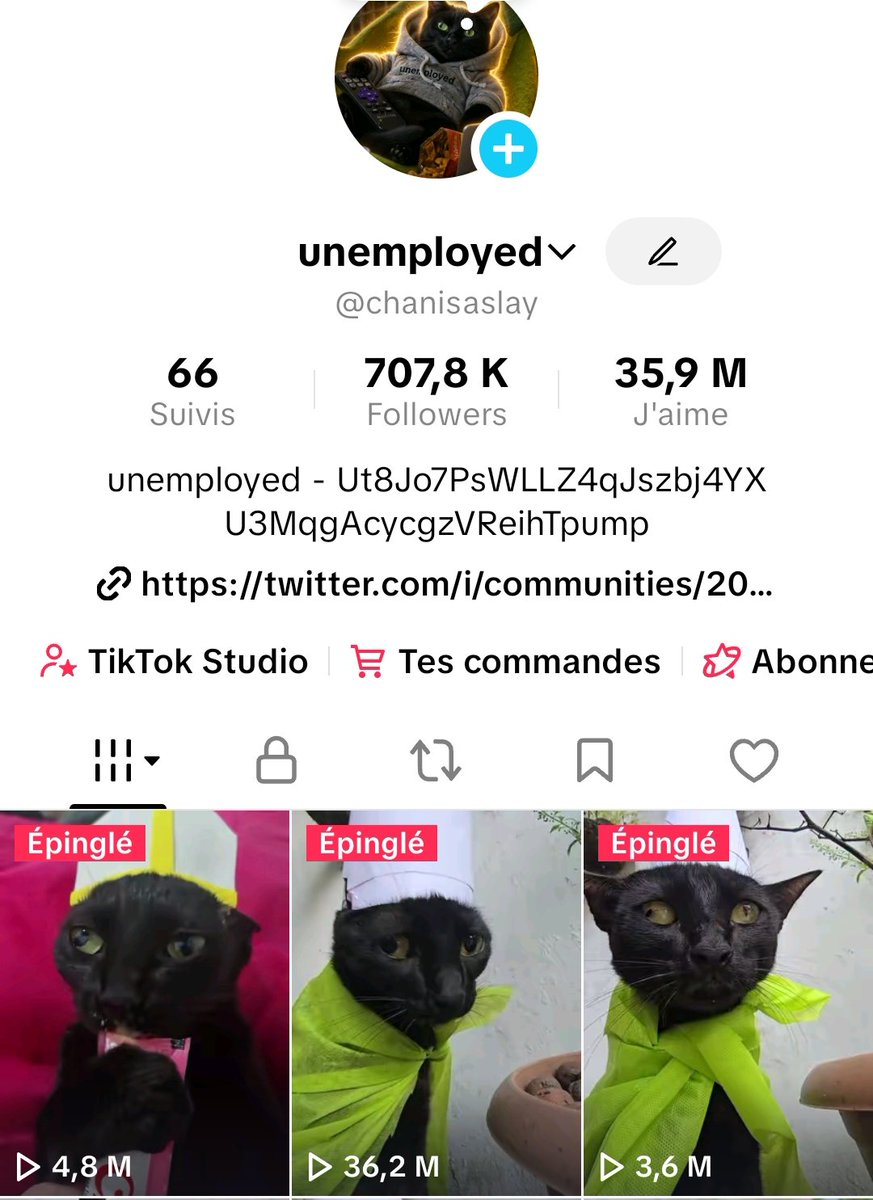
English
datasync retweetledi

I remember when crypto bros banded together for or against popcat
Run it back turbo… dog edition.
Reddit gem dropped yesterday.
Dog goes yuck then goes pop to flex on the huz
$popdog
2dYaeABVhTxxwN4MQMn5b3n2KGRFrvbN3qE9TNsipump

English

datasync retweetledi

@Rahulchhbra07 announces Sabi's (@sabicap) launch of a noninvasive BCI beanie that decodes brain signals for thought-to-action control, enabling typing and clicking without physical input using high-density EEG biosensors and a trained Brain Foundation Model.
The startup collected 100,000 hours of neural data from volunteers and is backed by Khosla Ventures, @Accel, @Initialized, and @KevinWeil, with a Wired feature interviewing Vinod Khosla on scalable wearable BCIs over implants.
This is geniunely one of the most insane things ive seen in the tech industry.
Huge props to these guys and cant wait to see the companys success!
English

Wow the ability to write with using my beanie…
Ai tech real use
Sabi stays on.
Rahul Chhabra@rahulchhabra07
you can now control things with your brain. literally. we're building the most wearable BCI on the planet, with @sabicap, backed by @khoslaventures @accel @initialized & @kevinweil. we collected the world’s largest neural dataset and trained the most capable Brain Foundation Model. then we invented a new class of biosensors powered by custom ASICs. type without typing. click without clicking. a cap that lets your brain do the work. we’re sabi.
English

datasync retweetledi





Yes, and enable quadriplegics to walk again and use their hands
Robin@xdNiBoR
Neuralink is just so incredible 🥹 Neuralink will help millions restore speech, blindness, and so much more! These videos make me emotional every single time.
English

@IGGYAZALEA Hey iggy
Hb a heart for our girl doomer she’s an $oomers
E5zkjqRYqwuyfhgndgT2fLT3bGYD3st2BvAF69ZQpump

English


your life is a blank canvas and you're always holding the paintbrush
Th0r@Thzer0r
Admire anyone who can deliberately create a new arc for themselves
English
@Johncoin_ Because crypto never sleeps
$ooners
E5zkjqRYqwuyfhgndgT2fLT3bGYD3st2BvAF69ZQpump

Nederlands

