Sabitlenmiş Tweet
David Smerdon
2.4K posts

David Smerdon
@dsmerdon
Chess Grandmaster, Assistant Prof. Economics U.Queensland
Brisbane, Queensland Katılım Ağustos 2010
198 Takip Edilen3.7K Takipçiler
English

@NewInChess @jaltucher Maybe it's time for another @dsmerdon paper, this time focusing on whether higher rated chess players are generally happier?
English

Find out why @jaltucher thinks that perhaps a draw really is the best result.
newinchess.com/new-in-chess-2…

English

@GMAlexColovic In chess, if you are a professional playing regularly, you can't afford not to keep up. It's the same with most professionals and AI. (I just gave a seminar on what industry can learn about AI from chess.)
English

Question for the experts (at the end of this analogy):
I've noticed that in chess it is often practical to sit out the massive theoretical developments in the opening and wait for the dust to settle, at which point one can simply adopt the already-established best practices.
Is it the same with the AI developments? Will the dust settle in a while when one can simply learn the best practices at that point, thus avoiding the constant pressure of trying to keep up that is currently present?
English
@peterdoggers "Many years later, AlphaZero would prove that White, in fact, is winning with 6.c3!, intending to meet 6... e5? with 7.c4! +-."
English

Going through my archives, I found this clip from the 2011 Amber Tournament with Ljubomir Ljubojevic showing Viktor Korchnoi why Bobby Fischer thought Black is better, a tempo, down, in a symmetrical position. Also with Veselin Topalov "refuting" 1.b4.
English
@ChessGainz Checked it on my phone. @chesscom app found it in <1 second.
English

One of my favorite puzzles/games to show new students, from Delekta-Geller, Cappelle la Grande 1992.
Even now the chesscom engine doesn't immediately see the best move, which is surprising as the solution is really quite simple!
Black to move & win!

English

@ChrisBirdIA @GMHikaru Once we inevitably move to three rounds a day, I assume we adopt Test Cricket rules of a lunch break, tea break, and copious drinks breaks.
English

Chris Bird@ChrisBirdIA
@ChessProblem Well, they did throw a spanner in that one, at least for now, by saying "To prevent fatigue and maintain quality of play, approved tournaments may run no more than two rounds per day." I don't know how the current Standard rated 2-rounds a day players have ever survived 😏
QME
So not only is FIDE green-lighting Standard rating 45+30 games for "major or traditional tournaments", they are allowing GM/IM norms to be earned in events with that time control! 🤯 fide.com/fide-updates-r…
English
@mustreader It's a good question! He could well be the current goat of goats. We are lucky.
English

Is there any other sport today where the No. 1 dominates as clearly as Magnus does in chess? Even when he’s out of form, it seems no one can stop him.
English
@MehmetMars7 @BenjiPortheault @viditchess No problem. I guess neither of us understands the other's argument, so let's leave this til a time we can discuss properly, hopefully in person :)
English

@dsmerdon @BenjiPortheault @viditchess Sorry I don't really follow you. A technically accurate move will not increase your MP. Saying that CPL, by treating any +2 pawn loss the same, may be more useful for measuring *human* performance is completely shocking. I don't think I have anything more to add. Good night 😴
English

The problem with drawing statistics from only centipawns eval is that it leads to wrong conclusions.
For eg: A shift from +3.5 to +2.5 doesn't change the game much, it is still clearly winning, but a swing from +0.5 to -0.5 changes the entire nature of the game and both scenarios are given the same weightage.
Also, Artemiev played many quick 10move draws, hence his accuracy is going to be highest.
Mehmet Mars Seven 🐴@MehmetMars7
Massive analysis from World Rapid Championship: Stats from more than 150k moves in 1500 games! 🥇Top TPR: Carlsen 🥇Most accurate: Artemiev Most accurate White: Villagra Most accurate Black: Artemiev
English
@MehmetMars7 @BenjiPortheault @viditchess I think it depends on the research question. We agree that a player can make a technically accurate move (e.g. 0 CPL) that decreases their MP. For Norway Chess, MP matters more. But for cognitive performance research, maybe the former is more useful. It's unclear.
English
@dsmerdon @BenjiPortheault @viditchess The main issue is to better measure *accuracy* so it can be a better proxy for cognition. I think you're approaching it the other way around, an interesting but a different problem.
IMHO, there's little value in using CPL as a proxy if we know it's a bad measure of human accuracy
English
@MehmetMars7 @BenjiPortheault @viditchess To be fair, most recent papers try to adjust for this. But my point is, we still don't have a good way to measure the performance of these metrics (MP included!) against objective cognition. I'm not sure how to solve this, but it would be valuable to the field to have evidence.
English
@dsmerdon @BenjiPortheault @viditchess I'm not sure what evidence you're looking for beyond what Vidit already mentioned? Going from +7 to +5 is a 2 pawn loss, which from a human perspective is quite different from going from +2 to 0. Do we need regressions to confirm that?😅
English
@MehmetMars7 @BenjiPortheault @viditchess Can you share the evidence that MP is a better proxy than CPL for cognitive performance? Wouldn't you first need a gold-standard measure of cognitive performance to benchmark against?
English
@dsmerdon @BenjiPortheault @viditchess This clarified, thanks! Missed Points (MP) is a better metric to compare with CPL, as GI isn't a measure of accuracy. I hope we can all agree that CPL is not a good metric for measuring the accuracy of human moves in chess. MP is definitely a much better accuracy metric & a proxy
English
@MehmetMars7 @BenjiPortheault @viditchess To put my question another way:
Academics aren't interested in chess performance per se, but rather, use chess as a proxy for cognitive performance. Does GI do better than (conditional) CPL as a measure of cognitive performance?
English
@dsmerdon @BenjiPortheault @viditchess 2/ Missed points can be calculated per move and per game like CPL. In my analysis, missed points of 2 per player emerges as a good benchmark
See github.com/drmehmetismail… for an implementation w/ SF & Lc0 (see pgn_evaluation_fast_analyzer.py)
again, happy to chat more 😊
English
@biophilo @MehmetMars7 @BenjiPortheault @viditchess Does it include a player's entire lifetime of games?
English

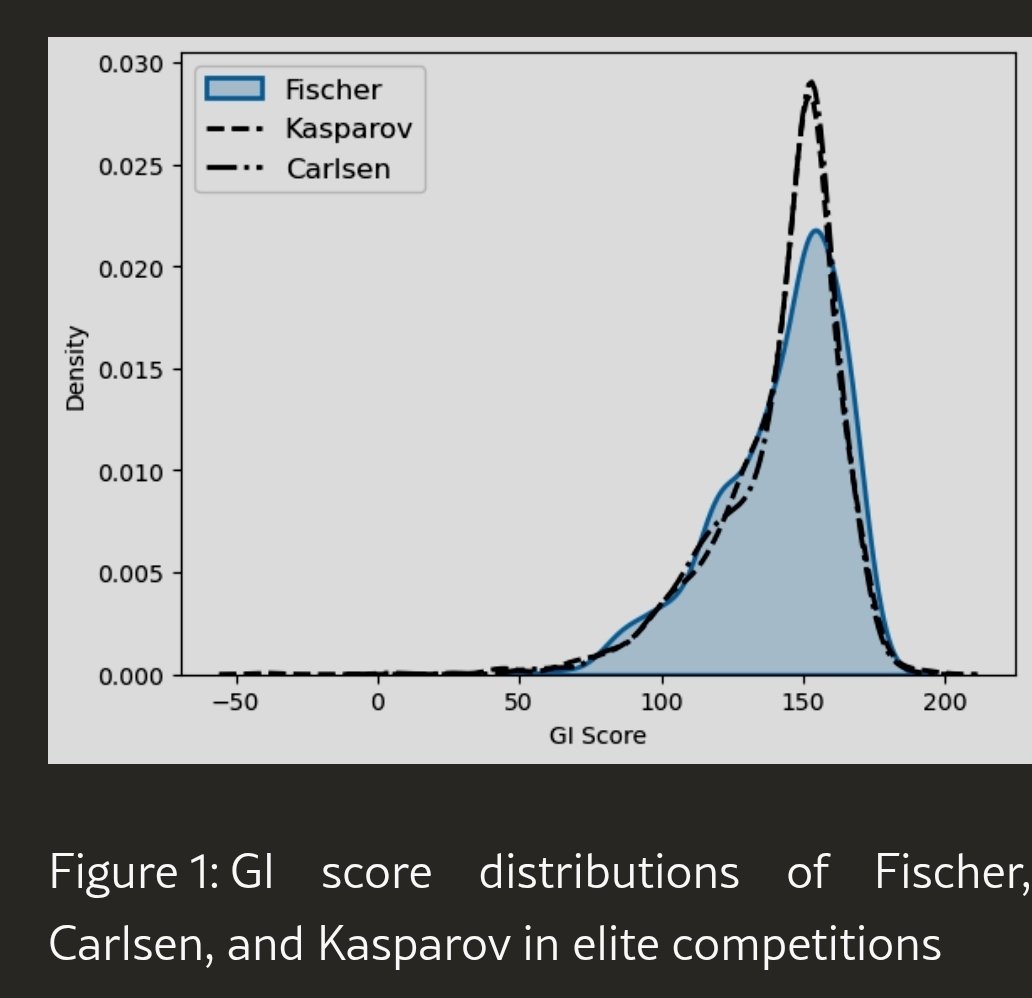
@MehmetMars7 @BenjiPortheault @dsmerdon @viditchess I found it quite surprising that top players have such high variability in GI, which is so unlike IQ tests (a 150-IQ-person has to be very drunk to get 50 on a test). But if you look at some games, it completely makes sense 😅.
x.com/i/status/20046…
Dani Sharon@biophilo
Dude, Vinnie just missed a 1000 rated puzzle, and he's not even in time trouble 😵💫
English
@MehmetMars7 @BenjiPortheault @viditchess Yes, I remember your email and your interesting approach of course, and no criticism taken :) How would you benchmark game points against using WDL, and against using ACPL with a complexity adjustment? (Maybe you've already done this?)
English
@BenjiPortheault @dsmerdon @viditchess (2) To be clear, this wasn't meant as a criticism at all, as average centipawn loss has long been the standard. That said, IMHO, revisiting past results with the missed points metric is needed from a replication and robustness perspective, to ensure conclusions remain consistent
English
@JohnHolbein1 It's easy enough to test for this channel by cross-randomising a class signal.
English

This comes up quite a bit in audit studies that rely on names to signal race. (Other methods of signaling race such as photos are certainly far worse.)
I feel qualified to say something about this, since I wrote a paper about this subject.
Racialized names signal both race and class.
However, whether this constitutes a design flaw or a strength depends on the estimand of interest. Put differently, it's not clear if class perceptions represent a “feature, not a bug” or a "bug, not a feature."
Feature, not a bug: under this framework, class is a mechanism that drives racial discrimination. Part of the reason for racial discrimination is because people make assumptions about the class of the person they are interacting with--sometimes even in spite of additional class based signals. There is an argument to made that not correct for class is the most ecologically valid thing to do. Class perceptions are part of how racial discrimination operates in the real world. Attempting to “hold class constant” risks blocking an important mechanism. Here the estimand is the total effect of being perceived as being a racially minority, including the class-based inferences that perception triggers.
Bug, not a feature: under this framework, class is a problem that should be partialled out. Here, you are looking at a very different quantity. Class-based inferences are treated as a contaminating signal. Here, adjusting for class is not about realism but about conceptual clarity. Here the estimand is the direct effect of race, net of perceived class differences. This estimand is more abstract. You could argue that it is less reflective of real-world decision-making. And arguably its less policy-relevant if class inference is itself racialized
Ultimately, however, these two approaches answer different, but equally legitimate, questions. It all depends on what question you are trying to answer.
Finally, I'd note that this disagreement is not about research design competence—it is about theory. Are class perceptions downstream of race, or separable from it? Is the goal to measure discrimination as experienced, or discrimination in principle? Do we want realism or decomposition? These all require us to make intentional decisions in our experiments.




Wilfred Reilly@wil_da_beast630
Class adjustment or nah?
English
@NMRobertRamirez @MagnusCarlsen This is one of those "know your classics" that I had never heard of until a YouTube video :)
English

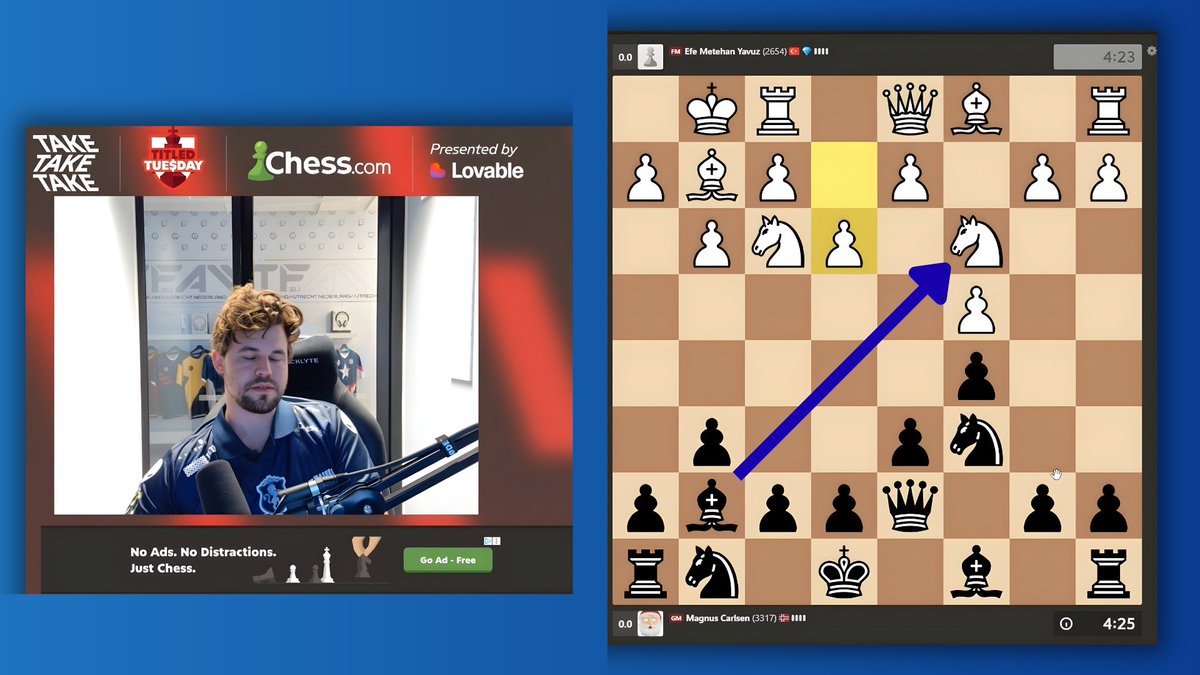
Watching @MagnusCarlsen say "when White plays e3, we take on c3..."
I need to understand why? Can you or anyone you know explain 🙌😅😎
English


