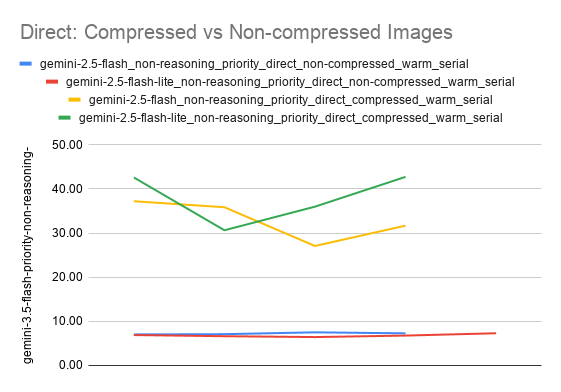
Ternyata ada perbedaan waktu pemrosesan ketika menganalisis gambar pada LLM, apakah lebih baik dikompress (reduksi ukuran bukan resolusi gambar) atau tidak? Kenapa perlu dikompress? Harapannya proses upload ke LLM lebih cepat.
Namun, kompresi gambar justru memperlambat seluruh proses dibandingkan jika tidak dikompress. Total waktu pada chart sudah termasuk waktu untuk mengkompress, lalu upload ke LLM, dan menerima output.
Indonesia