Txema ⚡
16.9K posts


Txema ⚡
@durbon
Director of Mobile @jobandtalentEng. Formerly @idealista @genbetadev También escribo sobre tecnología https://t.co/4N8UPJ6eEp Del Rayo ⚡Runner
Madrid Katılım Nisan 2007
1.8K Takip Edilen3.2K Takipçiler
Txema ⚡ retweetledi


Txema ⚡ retweetledi

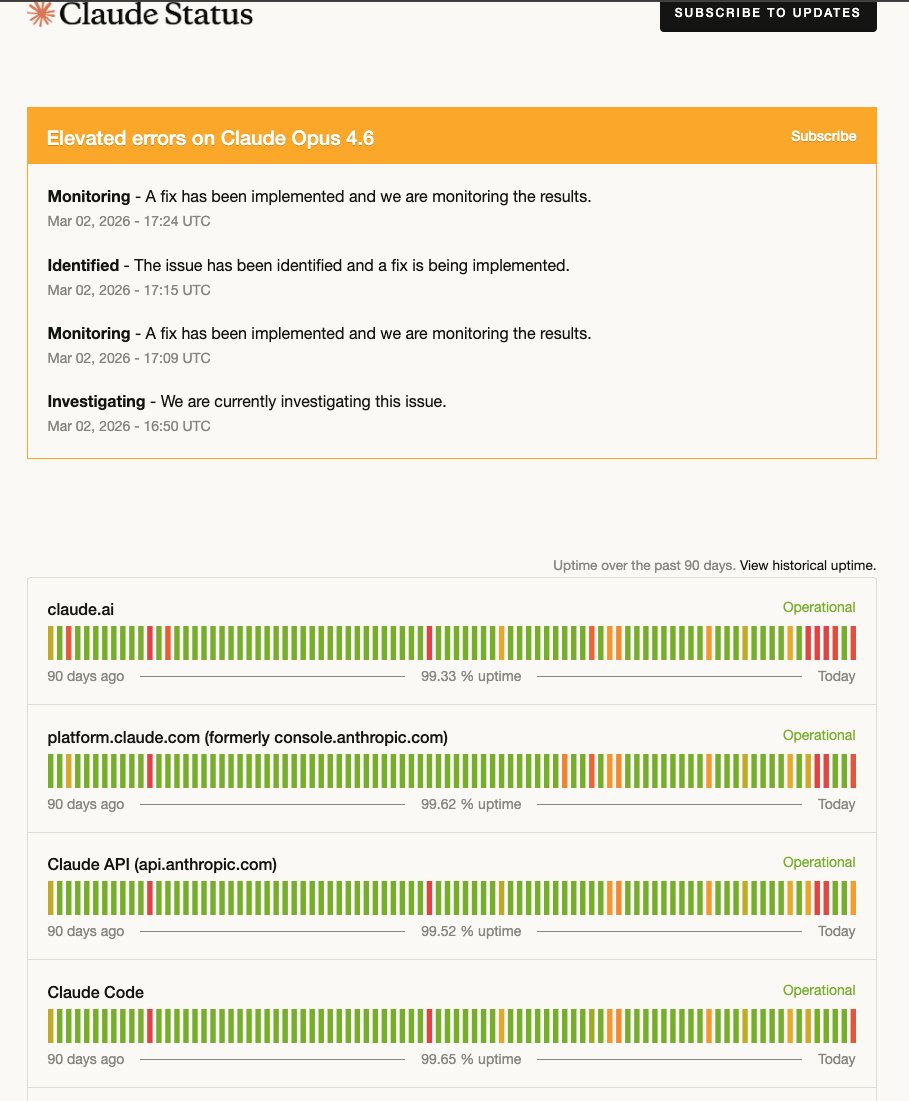
If you used a Claude subscription with OpenClaw, read this:
Unfortunately all other AI models out there absolutely suck with OpenClaw compared to Opus
It's just a fact and anyone denying this is delusional
So here is my new recommended OpenClaw setup:
Pay for the Opus API and use it as your orchestrator
Then use other models as the execution layer
If you do this correctly, yes your costs will go up, but not by as much as you think
I use my ChatGPT subscription as the coding execution. GPT 5.4 is excellent at coding. When The Opus orchestrator gives a coding task to the ChatGPT subagent, it always performs really well
If you are on the Pro plan, you should have enough usage to have ChatGPT be the execution layer for every task. But if youre on the $20 a month plan, youre going to need other subscriptions to handle other tasks
GLM 5.1 and Qwen are excellent. I'd get a cheap sub through them and have them handle all other tasks given to them from the orchestrator
The best setup tho if you have the hardware is Opus API for orchestrator, ChatGPT for coding, then local Gemma 4 and local Qwen handling everything else.
Right now have Gemma running on my DGX Spark and Qwen 3.5 on my Mac Studio. They handle all other execution from my Opus API orchestrator
Unfortunately all options above will cost more than the $200 a month subscription. It just is what it is. But if you optimize correctly it wont cost much more, and you'll still get frontier performance.
OpenClaw is the most powerful piece of software ever released. $200 a month ($2,400 a year) was a steal for a digital employee. Honestly anything under $50,000 a year is a no brainer if you run a serious business.
The situation isn't great but you also need to face reality: Claude Opus 4.6 is the best model for OpenClaw. If you use any other model, your productivity will suffer
Business is a battlefield and I refuse to fall behind, so despite me not being happy with the Anthropic decision the setup above is what I'm going with
Virtue signaling might get me brownie points on the internet, but it won't increase my productivity
English
Txema ⚡ retweetledi

Anthropic now blocks first-party harness use too 👀
claude -p --append-system-prompt 'A personal assistant running inside OpenClaw.' 'is clawd here?'
→ 400 Third-party apps now draw from your extra usage, not your plan limits.
So yeah: bring your own coin 🪙🦞
English

@durbon Eso es una movida grande. Por eso yo uso openrouter para routing - no dependes de un solo proveedor. Minimize the blast radius cuando pasa esto
Español
Fue bonito mientras duró. Anthropic se se pone serio con lo de usar la suscripción de Claude Max en OpenClaw reddit.com/r/openclaw/s/V…
Español
El 95% de las organizaciones no ven ROI en sus iniciativas de IA. Quizá el problema no sea la herramienta durbon.com/tecnologia/com…
Español
Tokenmaxxing isn't an AI adoption strategy. It's a cargo cult dressed up as data-driven management. Measure impact. Measure outcomes. Or don't, and in two years we can all write the retrospective about how obvious it was. durbon.dev/tokenmaxxing-m…
English
Txema ⚡ retweetledi

No project has gotten more traction in such a short time than @openclaw by @steipete But how is he building it?
Watch or listen:
• YouTube: youtube.com/watch?v=8lF7Hm…
• Spotify: open.spotify.com/episode/5Ie6Qt…
• Apple: podcasts.apple.com/us/podcast/the…
Brought to you by:
• @statsig — The unified platform for flags, analytics, experiments, and more. Join us at The Pragmatic Summit I’m hosting with Statsig, on 11 February: pragmaticsummit.com
• @SonarSource – The makers of SonarQube, the industry standard for automated code review. Join me online at the Sonar Summit, on 3rd March: sonarsource.com/pragmatic/sona…
• @WorkOS – Everything you need to make your app enterprise ready. If you're in SF on 9 February, stop by at the WorkOS AI Night with The Pragmatic Engineer (free to register): luma.com/workos-pragmat…

YouTube
English
Txema ⚡ retweetledi

