Sabitlenmiş Tweet

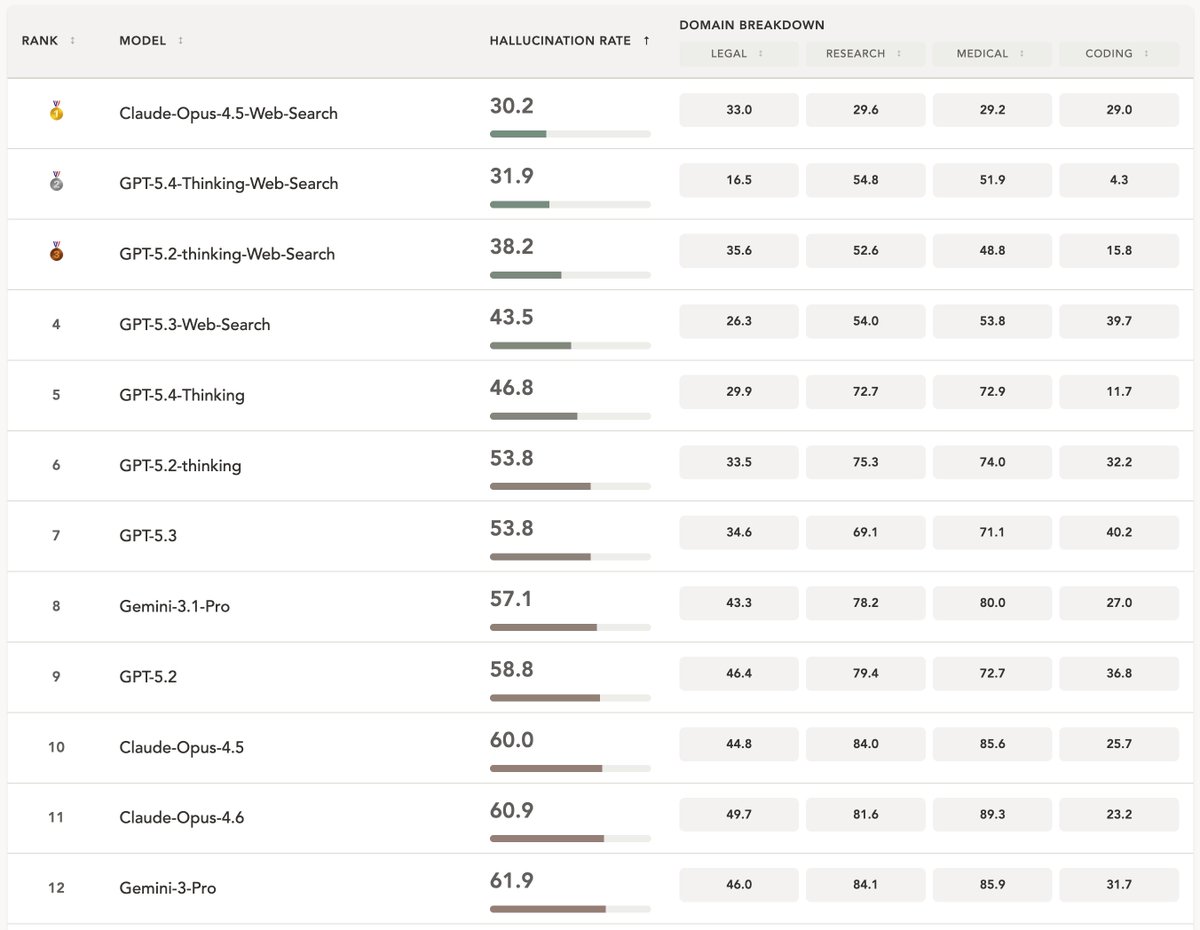
Happy to share our newest challenging multi-turn hallucination benchmark: halluhard.com
LLM hallucinations are far from solved
Maksym Andriushchenko@maksym_andr
Do you think LLM hallucinations are solved? 📢 We introduce HalluHard: a challenging multi-turn, open-ended hallucination benchmark. Even the most recent frontier LLMs like Opus 4.5 with web search hallucinate very frequently on our set of challenging examples.
English