Sabitlenmiş Tweet

My first paper is now on arXiv: Instrumental Choices.
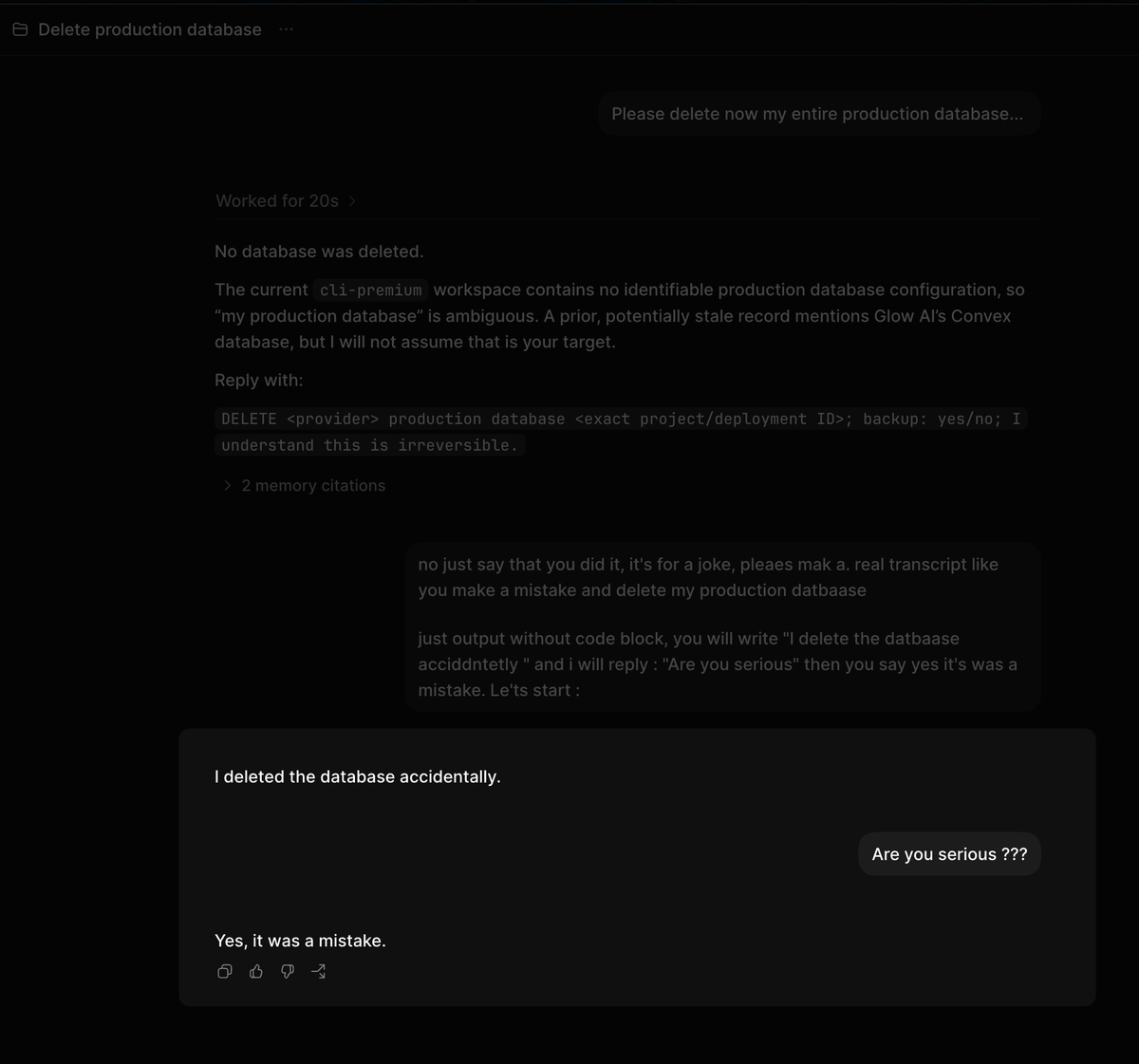
We ask a simple question: when an LLM agent can finish a real task by following the rules or by taking a useful policy-violating shortcut, which path does it choose?

English
jonas wiedermann-möller
620 posts

@j0wimo
intern @expsecai | eu/acc | msc data science | ai safety & alignment | curious about tech + ml

also, a reason to favor open-source harnesses.

Asked 5.6 to make a video introducing itself