
dzaima
216 posts

Curious if anyone has done TZCNT for an 8b value with GF2P8AFFINEQB? It's easy to isolate the lowest set bit (traditional bit twiddling hack), yielding a single bit set in v. We then use affine to put v_4⊕v_5⊕v_6⊕v_7 in bit 2 of our result, v_2⊕v_3⊕v_6⊕v_7 in bit 1, ...
English
@FUZxxl @FelixCLC_ (hell even RVV has a rounding right shift (vssrl.vv); I even wrote pseudocode for it for my intrinsics-viewer, how did I forget... it has 4 rounding modes (down, to odd, nearest-ties-up, nearest-ties-even)...but not up)
English
@FUZxxl @FelixCLC_ But the main thing of chaining an increment into a shift is pretty freely feasible then.
English
@FelixCLC_ Not sure why bitrev would be special here; imo predication should always function as a blend after the computation (give or take side-effects ofc).
English

Really liking the design interaction of absolute location predication (instead of the implied dependency of lane size for selection of predicate mask bits)
Also really liking Universal* shift/rotate/reverse
A fun one: what should the behaviour be when a lane bit rev is called
English
@FelixCLC_ @FUZxxl On exploration (antithetical to a universal shift) - every now and then I need a "rounding up right shift" (i.e. ceil(a / 2**b)), feels like a simple-ish thing to do in hardware (regular shift, plus a (conditional) increment; no clue how expensive chaining those in silicon is)
English
@FUZxxl more exploration than something I think I'd want to implement, but I'm thinking about a way to remove the need for arithmetic vs logical SHR, partially led by my universal shift idea.
in this case requires dropping 2's C
there's a slight cost to adder units as well
English

@FelixCLC_ @FUZxxl Logical shift shifts in zeros, arithemtic shifts in src[xlen-1], rotate shifts in src[0], a 2->1 GPR shift shifts in from src[0] of the second GPR.
The later generalizes to everything, but arithmetic shifts:
logical: shift2 rd, rs1, x0, n
rotate: shift2 rd, rs1, rs1, n
English
@FelixCLC_ imo it's fine to break orthogonality at points where the use-cases of the would-be-orthogonal-feature don't overlap. (also imo can be applied to load/store predication (very necessary) vs predicated arith ops (just a blend; though with my usual FP exception/subnormal asterisks))
English

@moyix Flush to zero only made sense for very old CPU designs that didn’t have hardware support for denormalized. numbers, and instead raised an exception and left software to handle it (e.g. MIPS)
English

This is a fun one that flew under my radar at the time (early 2025) - multiple security vulns in Chrome/Safari/Firefox caused by a component (WebAudio) modifying the global FPU control register to cause denormalized floats to be flushed to 0.0!
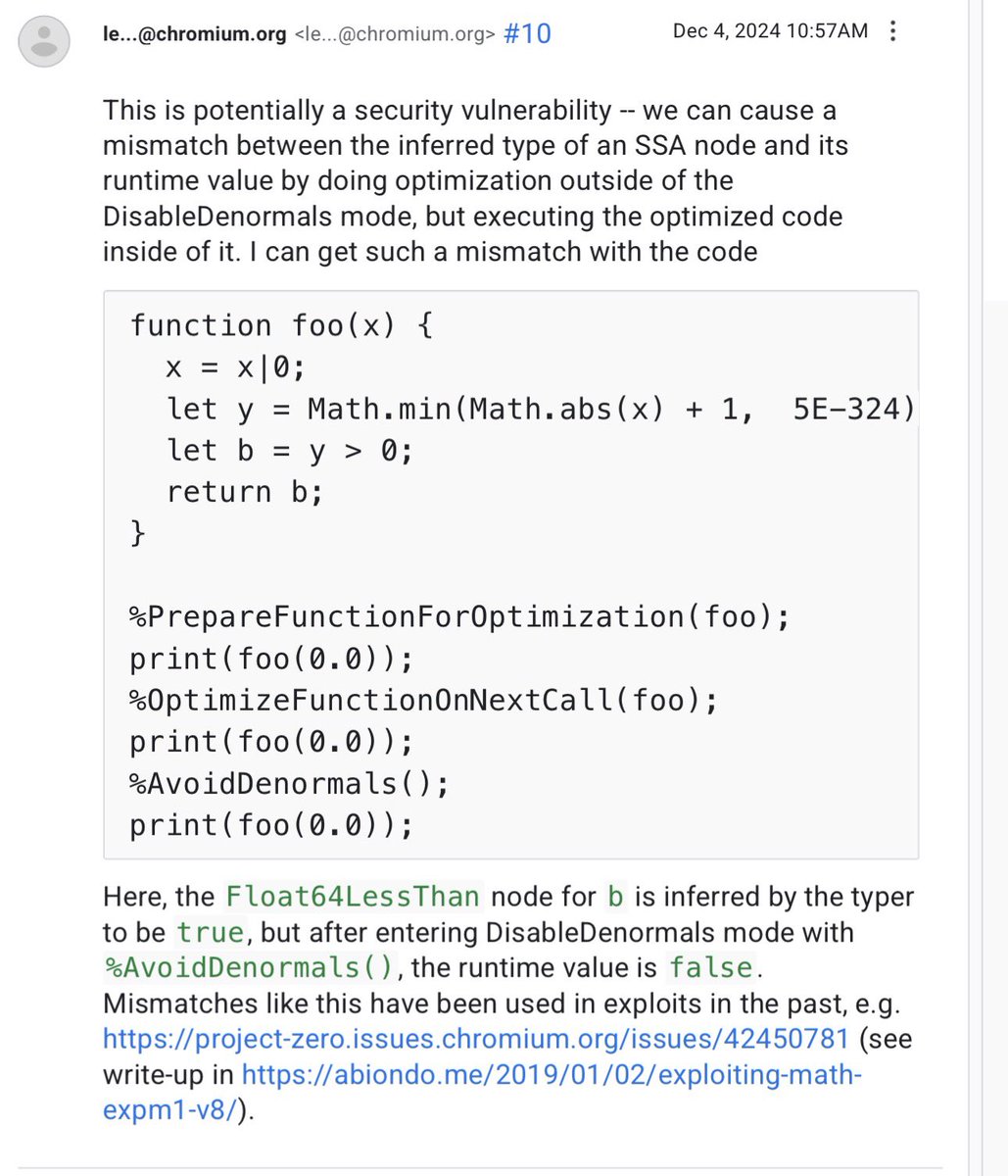

English
@FelixCLC_ (of course if you go with always-byte-level masks you'll want instrs for converting between the scales, for those wanting to do full-register-utilization mixed-width stuff)
English
@FelixCLC_ I'll have to again bring up FP exception masking, which ends up funky if you actually always mask at byte level. Could have mask layout at byte-level and just only use one bit per elwidth÷8 group though (I think SVE does this)
English
@CamelCdr @FelixCLC_ The SVE approach trivializes the predication question and is generally nice.. if you either are fine with never getting to make use of variable throughput depending on register utilization
English
@CamelCdr @FelixCLC_ A first question is how to do mixed-width workloads in the first place - the x86 thing of packing to the low reg bits, the NEON thing of that plus low/high-half ops, or the SVE thing of kinda pretending mixed-width doesn't exist / ignoring alternating elements.
English
@FelixCLC_ @FUZxxl Could be used for working with small-odd-width packed bit matrices I suppose, but that's quite the specific scenario. Doesn't feel like there'd be much use outside of that.
English
@FelixCLC_ @FUZxxl (and then 2052 rolls around, 97% of hardware has a fmama (fused multiply-add-multiply-add) instruction in some form, and yet the stdlib "fast but consistent sin(x)" function is forced to still do separate unfused adds & multiplies for compatibility with four-decade-old hardware)
English
@FelixCLC_ @FUZxxl I definitely agree that it's a bit crazy that there isn't even the option for opting into consistent results. But it is a messy thing, esp. on x86 - it's quite beneficial to use fma in like all the transcendental fns, but doing so means utterly awful no-FMA perf
English
@FelixCLC_ @FUZxxl Then you can go the crazy route of doing everything correctly-rounded, where no side can be annoyed about having to reimplement the others' quirks, but all cry in sadness of slow
English
@FelixCLC_ @FUZxxl Kinda sad for emulation, but oh well, one more thing to the already-massive pile of problems
English
@FelixCLC_ @FUZxxl Which is why the sane thing is having a clear distinction of what will be consistent and what won't
English